Optimising DAX: VertiPaq Encoding Techniques


In the previous post, we covered how VertiPaq uses column-oriented storage to make aggregations fast. But we left a fairly important question unanswered: how does it fit all this data into memory in the first place?
The answer is compression. VertiPaq uses three encoding techniques, and understanding them is key to understanding why certain model designs perform better than others. Bear with me through the mechanics - it'll pay off when we get to the practical implications in later posts.
Value Encoding
Value encoding is the simplest of the three. The idea is to reduce the number of bits needed per value by applying a mathematical transformation.
A concrete example: say you have a column containing 194, 205, 114, and 216. Storing these raw requires 8 bits per value. But if you instead store values as offsets from 114 (so 80, 91, 0, 102), and the engine knows to add 114 back when reading, you'll need fewer bits. This is a simplified example - In practice, the engine finds the transformation that minimises storage.

Doing this means you can store smaller columns and therefore do faster reads. Again, this adds load to the CPU as the values need to be decoded, but CPU is cheap and getting ever-faster (a recurring theme in this series).
Hash Encoding
Hash encoding is used for any non-numerical values. Instead of storing actual values in the column, VertiPaq stores small integers and keeps a separate dictionary that maps those integers back to the original values.
This is especially powerful when values are repeated. Imagine a column of customer names - large strings appearing across millions of order rows. Without hash encoding, every row stores the full string, which would be a huge amount of memory. With hash encoding, each unique string appears once in the dictionary, and the column itself contains only tiny integers.
Clearly, if a column has very few repeated values (like... for example... an ID column), the dictionary ends up being as large as the column, and you've gained nothing. We'll come back to this when we talk about cardinality in a couple of posts' time.
A couple of details worth knowing:
Any column that participates in a relationship must be hash encoded. This is a VertiPaq requirement for how it handles joins.
Hash encoding also means that VertiPaq is essentially type-independent under the hood. Strings, dates, decimals - everything ends up as hashed integers internally.
Run-Length Encoding
The final technique is run-length encoding (RLE). Instead of storing every value in a column, RLE stores how many times each value repeats in sequence.

For example, a column:
| Value |
|---|
| Q1 |
| Q1 |
| Q1 |
| Q1 |
| Q1 |
| Q1 |
| Q1 |
| Q1 |
| Q1 |
| Q1 |
| Q2 |
| Q2 |
Can instead be stored as (combining run-length and hash encoding):
| Value | Repeated |
|---|---|
| 1 | 5 |
| 2 | 2 |
| 1 | 5 |
With a dictionary:
| Hash | Value |
|---|---|
| 1 | Q1 |
| 2 | Q2 |
Which is a significant reduction, especially when tables get much larger!
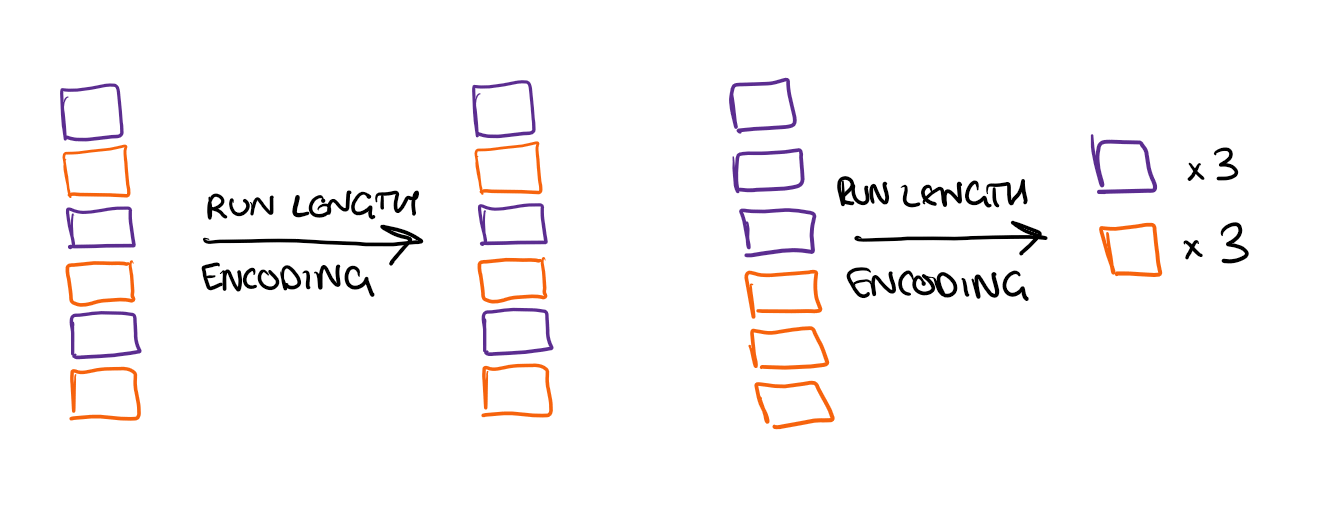
The effectiveness of RLE depends heavily on the sort order of the data. If all the Q1 values were grouped together rather than split across two runs, you'd get even better compression.
The 10-Second Sort Budget
When you import data, VertiPaq analyses the optimal sort order for run-length encoding. By default, it spends 10 seconds on this analysis. If it hasn't found the optimal ordering in that time, it uses the best one found so far.
This is one of the main reasons that reducing the number of columns in your model is a good idea. Fewer columns means fewer permutations to evaluate, making it more likely the engine finds a good sort order within the time budget.
Putting It Together
These techniques work together, but not all at once. Value encoding and hash encoding are mutually exclusive - numeric columns generally use value encoding, while text and other non-numeric data use hash encoding. The exception is that any column participating in a relationship must be hash encoded, so a numeric foreign key column will use hash encoding rather than value encoding. Run-length encoding is then applied on top of whichever encoding is used, compressing consecutive repeated values.
The result is that VertiPaq can hold impressively large datasets in memory - but how well it compresses depends very much on the characteristics of your data. Look out for the next post on why cardinality matters.