FabCon Vienna 2025: Day 3


After a busy start to FabCon Vienna, day 3 continued with a focus on practical sessions and technical updates. The sessions covered migration from Azure Synapse, platform integration, and performance improvements.
Accelerating Fabric Migration: New Assistant Tools for Data Engineering and Warehousing
(Jenny Jiang - Microsoft, Charles Webb - Microsoft)
The morning kicked off with a session on Synapse to Fabric migration. The new Migration Assistant looks useful. It can migrate Spark pools, notebooks, job definitions, and lake databases. But, it is worth keeping in mind that it doesn't touch pipelines, which is still going to be a bit of a headache for anyone with complex ETL flows!

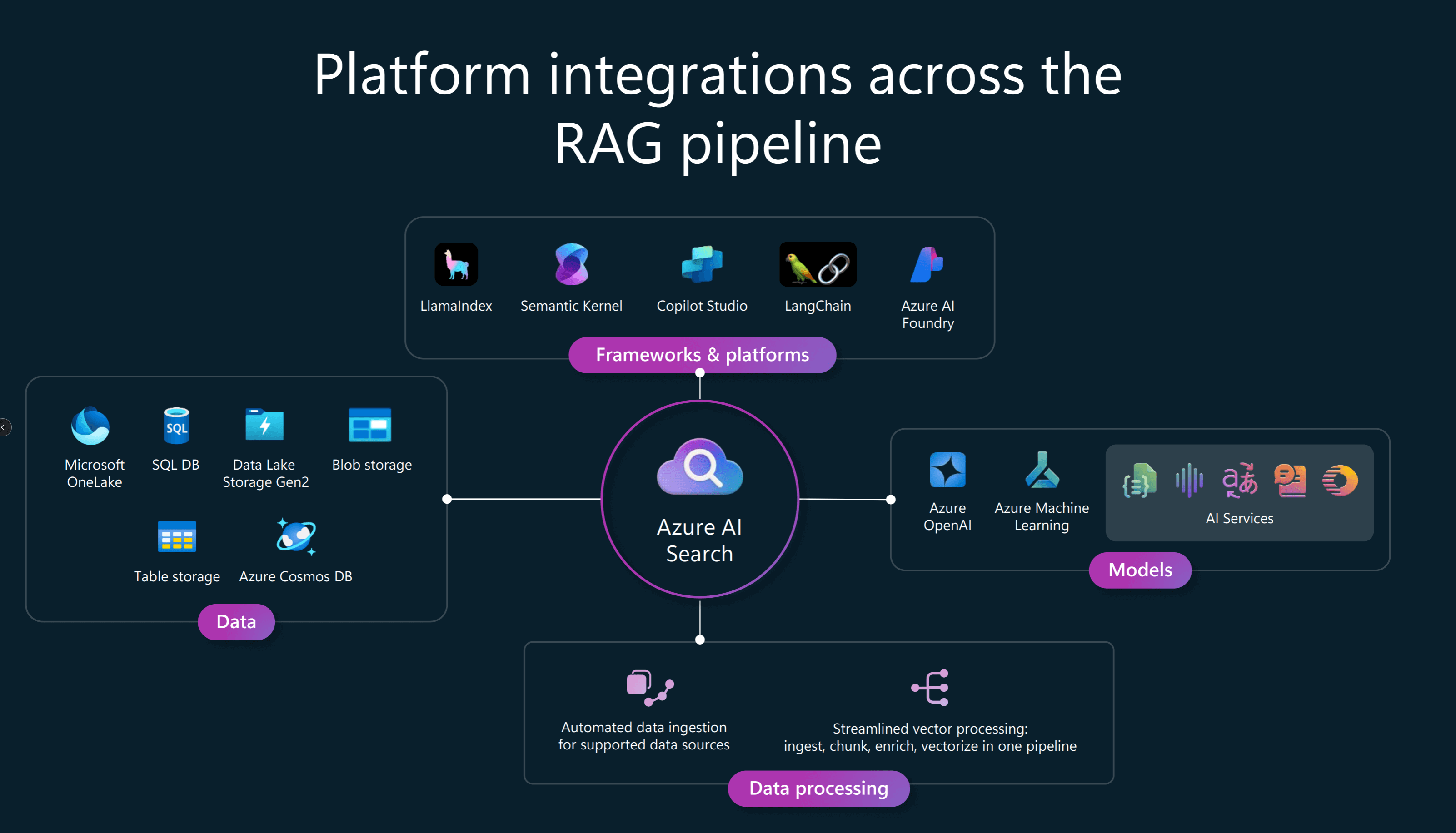
Powering AI Foundry Agents with Azure AI Search
(Farzad Sunavala - Microsoft)
This session was a deep dive into Azure AI Foundry and how it integrates with Azure AI Search for RAG (Retrieval Augmented Generation) scenarios.
- Azure AI Foundry is best used for more complex business processes
- Azure AI Foundry Agent Service - connects the core pieces of Azure Foundry into a single runtime, combining:
- Azure AI Foundry Models (with most people gravitating towards OpenAI models)
- Tools like Azure AI Search, Azure Machine Learning, and Azure AI Services.
- Content filters and enterprise security
- Observability through tracing modules and evaluation frameworks.

The session focused heavily on Azure AI Search and RAG patterns.
RAG allows you to ground LLM responses in your own data rather than relying solely on pre-trained knowledge. When a user asks a question, the data store is searched, and the results are combined with the original question to generate contextually relevant answers.
RAG can be used to tackle harder questions from humans and agents, such as:
- Producing multi-stage queries
- Achieving the aim of "natural language to SQL"
They outlined the RAG framework pattern with three main components:
Data Pipeline
This is probably the most critical step to get right - requiring clean, standardised data across multiple sources.
- Ingest - Multiple different data sources unified (can use OneLake shortcuts and mirroring).
- Extract - Parse raw documents from tables, images, pdfs into a usable format.
- Chunk - Split large documents into smaller segments to fit context windows.
- Embed - Convert chunks into vector embeddings.
- Index - Store embeddings, processed data and enriched content for efficient querying.
Query / Retrieval Pipeline
The query/retrieval pipeline was broken down into several key steps:
- Transform query – The LLM optimises the raw user input, making it more effective for search.
- Retrieve – The system searches for relevant information based on the optimised query. This stage includes:
- Vector Search
- Keyword Search - Which is sometimes required when vector search is not sufficient.
- And, Agentic Retrieval.
- Re-ranking – Results are reordered using semantic ranking to ensure the most relevant items appear first.
- Generate response – The LLM uses the retrieved information and prompt to generate a contextual answer.
The true strength of this pattern lies in its advanced retrieval pipelines, which include two key stages:
- Query pre-processing: Involves query planning to optimise how searches are executed.
- Retrieval: Utilises vector search, keyword search, and agentic retrieval methods.
Agentic Retrieval: Enabled by a new API within Azure AI Search, agentic retrieval applies techniques such as:
- Query planning
- Fan-out query execution
- Results merging
- And, within a single LLM call, it can:
- Use conversation history for added context
- Correct spelling errors contextually
- Break down complex queries as needed
- Paraphrase queries for clarity
- Rewrite queries using acronyms - you can do this providing the LLM with a JSON containing acronym definitions
Agent Orchestration
The agent orchestration layer brings together all components needed for end-to-end RAG pipelines, enabling seamless integration for GenAI deployments. It supports:
- AI Models: Including multimodal models, embedding models, and enrichment models.
- Developer Frameworks: Integrations with GitHub, Copilot Studio, Azure AI Foundry, and open-source tools.
Storage and Cost Optimisation in Azure AI Search
The session also covered techniques for optimising storage and reducing costs in Azure AI Search:
- Scalar quantisation: Compresses vector data by lowering its resolution.
- Binary quantisation: Encodes each vector component as a single bit (1 or 0).
- Matryoska representative learning (MRL): Applies multi-level compression to vector embeddings.
- Variable dimensions: Automatically reduces storage requirements for vector indexes.
- Narrow types: Uses smaller data types (e.g., float16, int16, int8) for vector fields to minimise memory and disk usage.
Demo Highlights
Azure AI Foundry & OneLake Demo
A brief demo showcased how "top-k" chunks are used in RAG scenarios. The web app combined AI Foundry and AI Search to retrieve the top 3 most relevant matches for a user query. You are able to see information that the prompt included, such filters, semantic captions, and semantic ranking, in order to generate the search query.
Azure AI Foundry & AI Search Demo
This demo walked through deploying a model (e.g., GPT-4.0) in Azure AI Foundry and creating a new agent. You can provide AI instructions, such as specifying access to Azure AI Search. The agent was connected to an Azure AI Search resource containing cardiology data from OneLake. The "hybrid and semantic search" configuration was recommended for domain-specific queries. When a user asked a question, the agent returned responses grounded in the AI Search data, and you could inspect the underlying search queries.
Azure AI Search Portal (Agentic RAG Demo)
The final demo briefly showed how to create knowledge sources in the Azure AI Search portal. Within agentic retrieval, you can prioritise different knowledge sources for specific questions using the "Mode + Instructions" configuration.
Democratize Generating Business Insights with Azure Databricks through AI and No-Code
(Adam Wasserman - Databricks, Isaac Gritz - Databricks)
Next up was a session on Azure Databricks. I imagined it would be a session about the integration between Azure Databricks and Fabric, but the session was more of a tour through Databricks' latest features.
There's a new business user portal, dashboards, and an AI assistant that lets you "chat with your data" - sound familiar? The "unity catalog business metrics" feature lets you centrally define things like revenue and save it in the catalog.
Databricks Apps (GA) make it easy to build data apps over your data, which are "production ready" and built on serverless technology.
Databricks One brings together all your data, apps, and dashboards for business users. This is great for data discovery, and it also supports integration with things like Teams.
Lakeflows let you design no-code ETL (like dataflows). Alongside this GUI experience, you can also upload an image or table of your desired state, and AI will design it for you!
There is also support for designing no-code AI agents using "Agent Bricks".
Overall, it's clear that Databricks are moving in a direction similar to Fabric - with a focus on support for non-technical users and expanding out of the "ETL" space.

Scaling and Protecting Data Engineering in Fabric: Best Practices for Success
(Santhosh Kumar Ravindran - Microsoft, Ashit Gosalia - Microsoft)
Back in Fabric-land, we attended a session on Spark optimisation at scale. This session ran through a load of "tips" for optimisation:
The new(ish) autoscale billing for Spark lets you scale compute independently of capacity. This is great as it means that you can start to use Fabric in a more serverless way - something we're big fans of here at endjin!
There are new controls to turn off starter pools (which might be bigger than you need), turn off job bursting, create custom pools at the capacity level, set max session lifetimes, and enable responsive scale-down (which means that executors are decommissioned when not active). Combined, these give you a lot of ways to limit excess usage.
They stressed the importance of enabling the native execution engine for massive performance improvements (at no extra cost). The engineering team has done loads of work on the native engine: faster write speeds, file size optimisation, auto file size optimisation, and alerts for when you fall back from the native engine. All these need to be toggled in pool or notebook settings.
There's a lot of additional features around private networking - for example, you can now block all outbound traffic. This means that by default you are unable to access anything external, unless it's on a specific allow list.
They touched on the new custom live pools, which should go live in Q1 next year.
There are big performance improvements coming for uploading JAR files and python packages.
And, as mentioned previously in the previous blog on day 1, you can massively increase notebook concurrency.
Row and column-level security in Spark are coming soon.
And, finally, there's a new JDBC driver for integration with external orchestrators and systems.
Microsoft Purview Data Security Protections in the AI Era
(Shilpa Ranganathan - Microsoft, Anton Fritz - Microsoft)
The final session covered data security challenges in the age of AI. With the rise of AI-generated attacks and the risk of inadvertent data exposure through tools like Copilot, organisations need robust security frameworks.
Microsoft Purview provides a unified approach to data security and governance, offering estate-wide protection for Fabric (and beyond!). You can use Fabric's built-in security features, or add Purview-specific capabilities with an additional license.
Key Purview security features for Fabric include:
- Information protection (GA) - Using the same sensitivity labels as Office and SharePoint and Azure, with label-based access controls that follow data throughout Fabric and downstream to Office, PDF files and Power BI reports.
- Data loss prevention policies (GA) - Automatically scanning to detect sensitive data across semantic models, lakehouses, SQL, KQL, and mirrored databases. When violations are detected, you can take immediate remediation actions, including restricting access (Preview) to data owners only.
- Data risk assessments (Preview) - Discovering overshared data and identifying potential leakage risks. The assessment page shows metrics like unique user access patterns across Fabric workspaces.
- Insider risk management (GA) - Helps security teams identify potentially risky users and malicious activities, including monitoring Copilot prompts for Power BI.
Here are some general ways to audit, monitor, and govern data using Microsoft Fabric and Purview:
Audit & Monitoring
- Fabric Admin Monitoring and Auditing: Fabric provides built-in admin monitoring tools to track activity, usage, and changes across your organisation’s data estate.
- Purview Audit: Microsoft Purview offers comprehensive audit capabilities, enabling you to monitor data access, usage, and policy compliance across multiple platforms.
- Integrated Auditing: Purview audit can be layered on top of Fabric’s native auditing, providing unified visibility and deeper insights into data operations and security events.
Metadata & Lineage
- Fabric Lineage: Fabric’s lineage features allow you to trace data movement and transformations, helping you understand dependencies and the flow of data across workspaces.
- OneLake Catalog: The OneLake catalog centralises metadata management, making it easier to discover, classify, and govern data assets within Fabric.
- Purview Unified Catalog: Purview’s unified catalog extends metadata and lineage capabilities across your entire data estate, integrating with Fabric and other sources for holistic governance and compliance.
The session emphasised that while Fabric has strong built-in security, Purview adds enterprise-grade governance across the entire data estate, which is increasingly critical as AI capabilities expand.

Overall
A packed few days, with a truly ridiculous amount of announcements and features - with many set to go live over the coming months. I'm looking forward to exploring a lot of these in more detail. And with that, I headed out to the alps to make the most of a long weekend in Austria!

Keep an eye out for coming articles and videos as we dig into the practicalities, share hands-on experiences, and see how these new features can be used in real-world projects!
If you're interested in Microsoft Fabric, why not sign up to our new FREE Fabric Weekly Newsletter? We also run Azure Weekly and Power BI Weekly Newsletters too!



