A beginner's guide to agile estimation and planning


My take on the cornerstones of good project estimation and planning.
Firstly, a huge thank you to Mike Cohn for his book on Agile estimation and Planning, which I wholeheartedly recommend if you want to know more about these techniques. And also, to Steve McConnell for going into the real details of software estimation in his book "Software Estimation – Demystifying the Black Art", a really in depth read with a lot of useful insight.
So, over the last few months I have been reading a lot about the issues surrounding software estimation and planning and, before it all leaks out of my brain, I thought I'd try and distil a bit of that knowledge. Specifically, recently I've been reading about Agile project planning, and it's been really interesting to see a lot of the concepts reflected in endjin's day-to-day activities.
Before I go into the problems which we all face with estimating and planning, I think it's worth highlighting the motivations behind creating good estimates. The key motivation behind good estimation is to be useful for project planning. There is a huge amount of inherent uncertainty surrounding estimates, especially early in the project. So, we shift our aim from 100% precise, or "true", estimates, and towards providing estimates which are useful and accurate (accurate in this sense meaning that they are a good measure of effort and convey a truly representative amount of uncertainty).

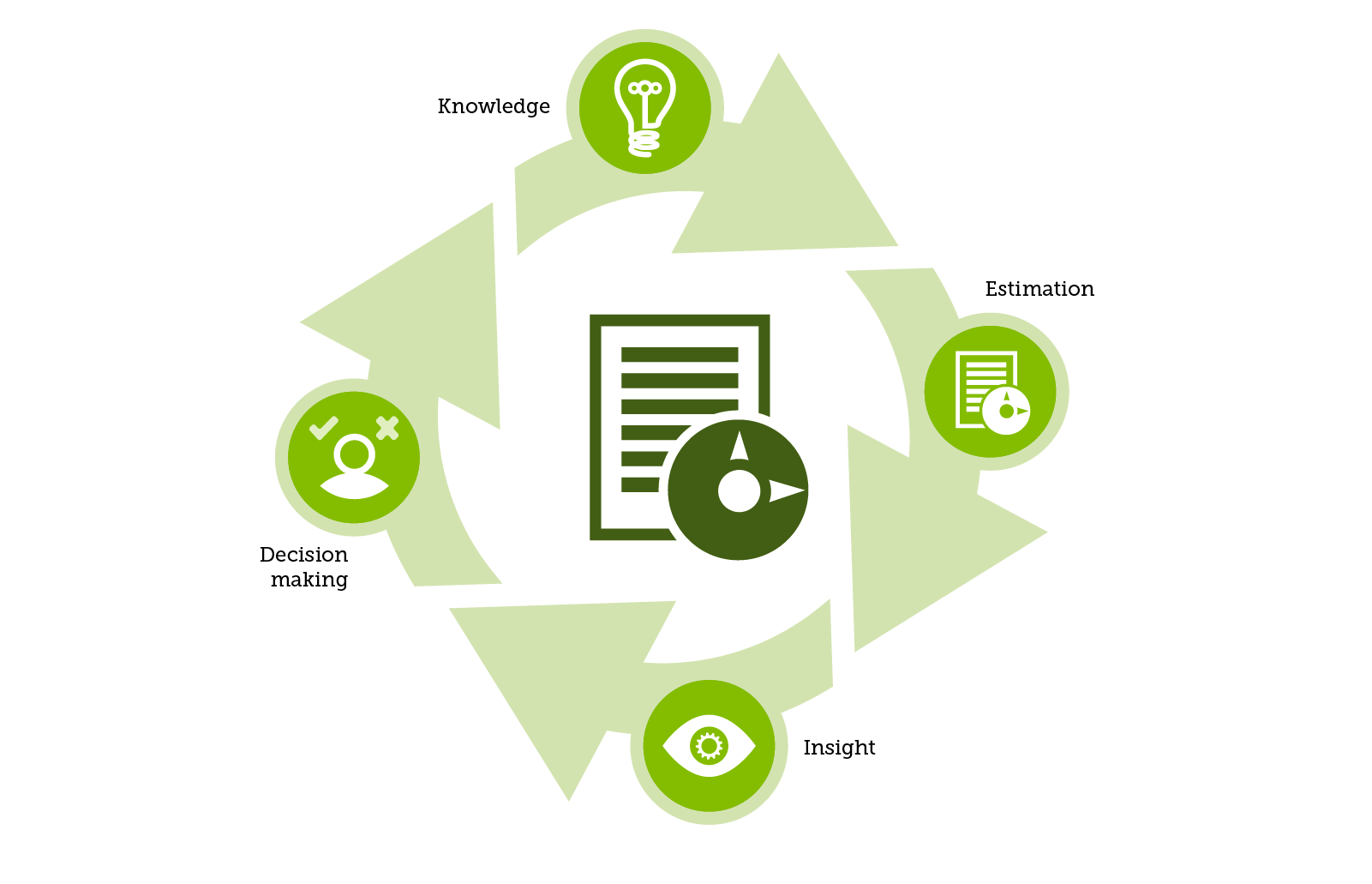
The usefulness of an estimate is achieved through the following:
- It provides insights into the risks involved with the project.
- By constantly reassessing as more knowledge is gained throughout the project you reduce the uncertainty involved over time.
- Reliable estimates lead to reliable delivery which establishes trust between the developers and management.
- Estimating supports decision making by providing insight into the costs and schedule of a proposed project.
So, what are the biggest challenges faced by those tasked with project planning?
The distinction between estimates and commitments is often blurred and warped. The difference between these concepts needs to be clearly defined.
Often features are not prioritised and are just developed in a random order. This means that if a project then runs late, and features need to be removed, these may be ones which would add more value than those which have already been developed.
When estimates are presented, or passed around a company, the uncertainty in those estimates is often ignored. This could be because the estimate was originally given with an error, which is then stripped away. It could also be because, even though the estimate was originally given as a range, management, or project-planning systems, will not accept a range.
Planning is often based on completing activities rather than features. If the planning is all based around the completion of tasks, then because tasks are not independent, lateness propagates. Another reason that planning by activity is a bad idea is Parkinson's law. This states that activities will expand to fill the time allotted. So, if we plan per task then each task is unlikely to finish early, meaning that it is far more likely that a feature will be completed late than early.
Finally, there is an assumption that by throwing more people at a problem a project will be finished faster. There are two main issues with this. Firstly, it does not acknowledge the fact that development is a problem solving activity. Adding more people to a problem does not necessarily make the logic involved move any faster. Secondly, adding more people to a team introduces far more lines of communication, and therefore complexity, which can actually slow a project down rather than speed it up.
To try and combat some of these issues, agile planning techniques have been developed. Mark Cohn summarizes the fundamental basics for an agile project as:
- Work is done in iterations, in each of which a set of features is taken from a set of requirements, to a finished and deliverable solution. Planning is done at an iteration and at a release level separately.
- Prioritise the features for a release, so that high value features (or user stories) can be delivered first. Also define the conditions of satisfaction at both a feature, and a project level, so the aims of each iteration and the release as a whole are clear.
- Continuously update the plans, and priorities, as knowledge is gained throughout the project.
- Teams should have an "all in this together" approach to the project, where the whole team takes responsibility for the estimates and delivery. If the team is working as a whole there is less of a cycle of blame which can lead to people padding estimates so as not to be seen as running late.
- Finally, agile teams shouldn't be larger than 9 people (and on average 7) or the lines of communication start to get too complex for effective communication and planning.
Estimation
Firstly, and clearly, an estimate is not the same as a commitment. The aim of an estimate is to be as useful and accurate as possible. This means that padding or being optimistic about estimates is counterproductive. These may be valid things to do when talking about commitments – adding buffers, or making optimistic delivery plans, but these same things should never be done when estimating.
An estimate should never be changed unless the assumptions, requirements or dependencies have changed. It is a calculated value for how much effort something requires and should not be adjusted due to scheduling constraints or management pressure. In a software project it is the engineers' (this includes everyone on the development team – programmers, testers, etc etc) responsibility to uncover the risks involved in the project. However, it is not their responsibility to mitigate the risks once discovered. If they can provide good estimates, it is then the business' problem to decide how to approach any issues raised. If there is a large mismatch between the schedule/commitments and an estimate this is indicative of a risk that needs to be addressed (which has been identified by the developers). For example, if you have committed to delivery in 6 months and you estimate that the work will take a year, this is something that it is important to acknowledge. Mismatches are good to identify as early as possible so that action can be taken to remedy the situation. Putting pressure on the developers to adjust the estimate at this point to match the outside requirements adds no value, the project will likely overrun, and nothing will have been done to deal with this outcome.
In this way, producing good estimates (remember a good estimate is one that is useful to the project plan, including conveying accurate information about the uncertainty) is crucial to effective project planning.
A key concern in agile estimation is to separate the estimation of size and the measuring of velocity. In separating these concerns, you can achieve an unbiased view of the size of a project, and afterwards assess the ability to achieve commitments or a schedule.
Story points
At a release level, the best way to achieve this is via story points. Story points are a relative measure of the size of a feature. You take each user story and assign it a number of points based on the effort you think will be required for the feature. This is all of the effort to take it from a requirements list to a deliverable product (so including exploration, dev, testing, production pipelines, etc.) The best way to do this is to use a non-linear scale, where the gaps in between the values increase as the scale increases. This reflects the the larger amount of uncertainty, and diminishing precision at larger scales. For example, you might say that for your project each user story can be given a value of 1, 2, 3, 5 or 8. Think of these numbers as buckets, if a story is maybe a little over a 3 then you can probable squeeze it into a 3 bucket, but if it is likely more like a 4, it will necessarily be placed into the 5 bucket. It is best to group very small stories, smaller than a 1, because if you assign each a value of 1 then it will appear that the team completed more work than they did in a given iteration.
There are some situations in which you must include an estimate for a much larger story (or epic). This is usually a group of stories for which the requirements are not fully defined. For this you may want to include 20, 40 and 100 in your scale. But bear in mind that these estimates will include a lot higher uncertainty. It is best to break down these features where possible.
The usual way to estimate a story's size is by analogy. This means to compare with other similar stories. You build up a baseline of the size of a variety of different stories, usually based on knowledge from another project. Each new story is estimated relative to all those already estimated, triangulating the estimations.
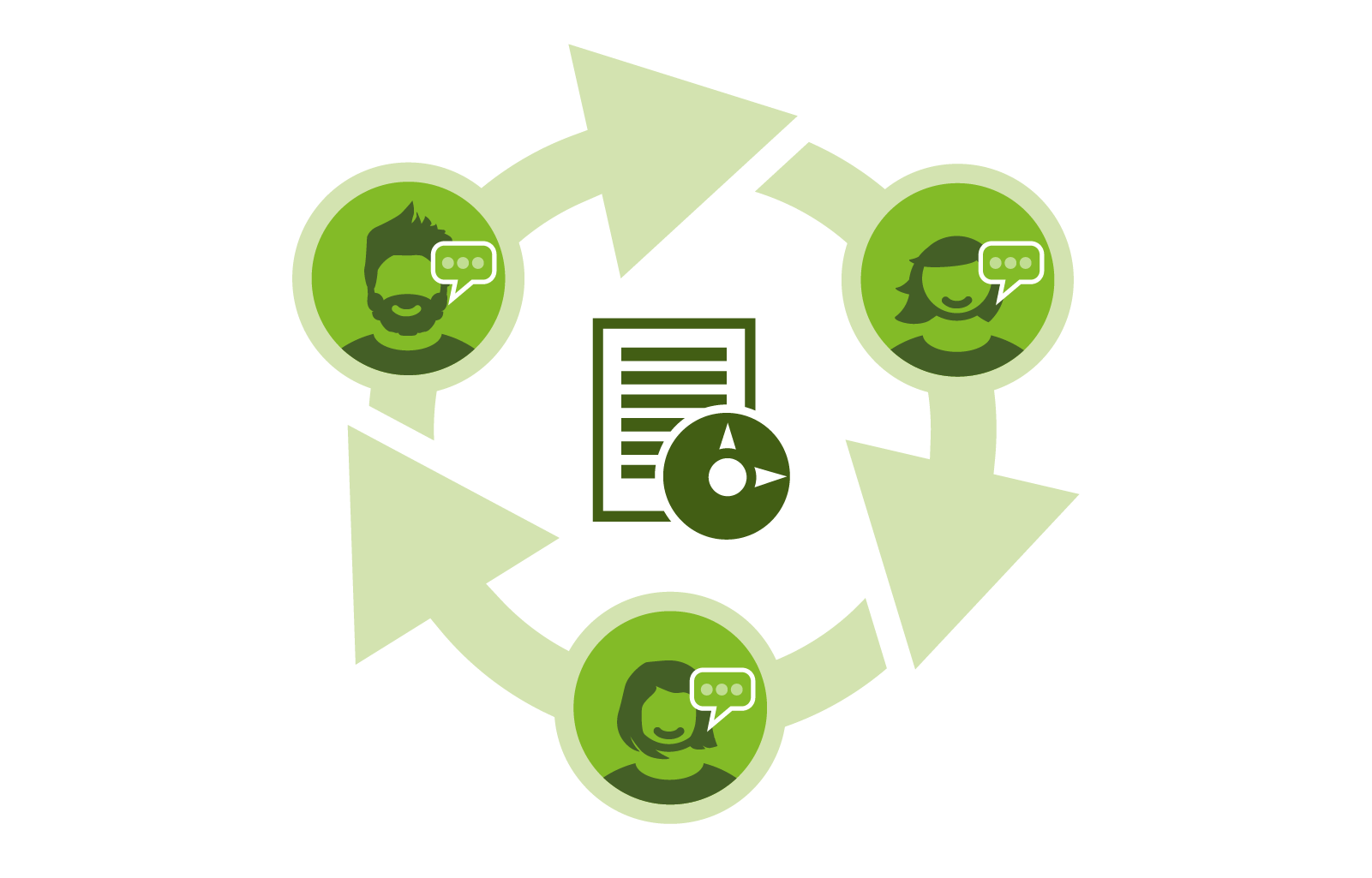
It is important that estimation is done with the whole team, meaning that those who will be carrying out the work will be involved in the estimation (and at this point we don't know who exactly will end up completing what work). The group discussion involved when estimating as a team also leads to needing to justify your estimates in some way, which generally improves their accuracy.
User stories should only ever be re-estimated if something changes. E.g. if the requirements around authorization grow which means that a story was larger than expected (so took longer), you may re-estimate it, meaning that more story points were completed in that iteration. However, in this case you must also re-estimate every story that will involve this more complex authorization. This may change the total number of story points in the release, which will need to be accounted for in further planning.
The amount of story points completed per iteration is a team's velocity. The points from a user story are only added to an iteration's total if the story is completely finished. This means that though the iteration velocity will be much lower in the first iteration, it is likely to be much higher in the next (because there is not much of the story left to complete) so the variation will even out. It is better to do it in this way rather to try and split the story because only "not started" and "done" are well defined points. Trying to define how much of a story is left if only the testing is left to do is difficult, and moves away from the team acting as one. It is important to give an accurate picture of the work that is left to do, otherwise risks are hidden. There is a lot of pressure to only report good news, however if you report a feature as "done" when it is not done, this incurs a build up of extra work which will just lead to problems later down the line. A shifting of mindset so that identifying risk is thought of as a positive outcome is crucial for a successful agile project.
Planning
Planning for an agile project should happen for at least two distinct levels: release and iteration. Planning is also required on a day to day basis, though this is less structured and is more based around team members communicating their individual task list.

Release planning
When planning a release follow this process:
- Define the conditions of satisfaction.
- Define the user stories needed for meeting the requirement conditions.
- You then estimate the user stories for meeting these conditions, using the technique described in the previous section.
- You then estimate velocity (the number of story points completed per iteration), this is best done by carrying out a few iterations and producing a range of possible velocities (this conveys the uncertainty in that velocity) based on the range found during those iterations. However, if this is not possible, historical data (from projects carried out by the same team, in the same environment) can be used. Where possible carrying out a few iterations to gauge velocity is always the best way.
- Select an iteration length, usually between 2 and 4 weeks. This decision is based on many factors including project length, uncertainty, fluctuations in requirements, need for feedback, etc. For example, if the requirements and priorities fluctuate a lot, then shorter iterations may be better because feedback on what is delivered can be given more regularly.
- Prioritise the user stories. This is done by considering the value, cost, knowledge gained and risk associated with each feature. There are many techniques for this, which I won't get into here, but essentially you want to get the most value for the least cost (obvious I know). Another thing to consider is that sometimes it is worth completing the riskier features first, as this means you can eliminate more risk earlier in the project. It is also important to think about any useful knowledge that will be gained whilst developing the feature.
- Select stories and release date. This is done differently depending on whether the release is requirement or schedule driven. If schedule driven take the required release date, divide the time you have by the length of an iteration to work out how many iterations you will be able to complete. Then, if you multiply this by the velocity you know how many story points you will be able to deliver and can choose stories (in order of priority) until you reach this value. If the project is feature driven you do the inverse. You add up the number of story points which equates to the features you want to deliver. You then divide this by the velocity to calculate the number of iterations required. E.g. If you have measured a velocity of 20 story points per iteration, with each iteration spanning 3 weeks: If your project is schedule-driven, and the required released date is 12 weeks away, then you can complete 4 iterations in that time. Therefore at 20 points per iteration you would complete 80 story points worth of features in this time. If you are requirements driven and you have 100 story points worth of requirements, then dividing this by 20 then the features will take 5 iterations, so 15 weeks to complete.
You should continually revisit and update the release plan throughout the project, at least once per iteration. This allows for the reassessment of priorities, the adjustment of the plan according to a change in velocity and allows risks to be identified early.
The key in all of this is communication, so that messages around requirements and expectations are clear.
The key aspects to remember when communicating about plans are:
- Avoid being overly precise, if you say "27 days" rather than "1 month" it implies that you are surer about an estimate than the uncertainty will allow. (And in most cases a range should be used – calculated using the range in the team's velocity).
- Use a feature breakdown rather than a work breakdown, this will keep the focus on value rather than on the individual pieces of work which must be completed.
- Using release burndown charts can be useful in order to clearly show progress, and to accurately represent requirement growth as the project progresses. These are charts with number of iterations completed on the x axis, and story points left in the release on the y.
- Use a range of velocities when forecasting. This communicates the uncertainty inherent in the project. Use a best, average and worst-case velocity for the previous (up to) 8 iterations to calculate this range.
This allows you to continually reassess and update a release plan as the project progresses. This feedback loop which is created (complete iteration, feedback progress, update plan, repeat) means that as you learn more about the project you can continually mitigate discovered risks, and keep the momentum moving towards a common goal. It makes miscommunication about requirements or expectations far less likely, and stops projects going down an unproductive route without any chance to course correct. A feedback loop of successful communication and reassessment means that a project can be kept on track and on target.
Projects with firm deadlines and requirements
All of the above works very well when you have some flexibility in schedule or requirements. In the vast majority of cases there is flexibility in at least one of these outcomes. However, sometimes we are forced to work in environments where there will be large consequences when changing the schedule or requirements.
In these cases, it is sometimes appropriate to use a buffer. This is not the same as padding tasks, it is an acknowledgement of the uncertainty involved in estimating and the consequences of overrunning. The size of a schedule buffer should be statistically based on the best and average case scenarios of each feature (the method for this is outlined in Mark Cohn's book). Combining this with a feature buffer can be very effective. This involves asking which user stories are "essential" and which are "ideal". At endjin we use "bronze", "silver", "gold" and "platinum" to grade the necessity of different features. You then estimate all of the stories and use this as your size estimate, but only commit to delivering the essential ones, and as many of the ideal as possible.
Iteration planning
A key thing to remember here is that tasks are not allocated when iteration planning. Projects work best if teams will pick up slack for one another, which works best if tasks are just picked out of a big pot.
1. First, select the goal of the iteration
This is done after review of the previous iteration, as part of which the project's priorities may have been updated. The goal selection should be done based on the updated priorities.
2. Select a story in-keeping with the goal
This should be done using the list of prioritised remaining stories. Remember that the release plan should be reviewed after each iteration, so this list may change as the project progresses.
3. Split that story into tasks
There should be an aim that all bugs which are found during an iteration should be fixed within that iteration (this will intrinsically be taken into account in your velocity measurements). It is important here to note the difference between a bug and a defect. A bug is something that is generally caused during development. They are usually found during testing, and sent back for fixing. The aim is to complete this cycle all within an iteration. A defect however is indicative of a much wider problem. In this case, usually something is wrong with either the specifications of the assumptions. These can be extremely expensive to fix if they are found in production (e.g. in manufacturing if it is found that one of the parts cannot cope with the normal use case). The feedback loop discussed earlier, where progress, assumptions and expectations are continually updated, is the best way to avoid defects making their way through to production.
4. Estimate those tasks
This should also be a group activity. Tasks are not assigned at this point, and everyone might have some valuable input. At this level, story points should not be used when estimating. When estimating tasks it is much more useful to use ideal days, or hours. Ideal time is the time that would be taken if there were no distractions, no meetings to go to, emails to answer etc. etc. Ideal time is preferable at this point because story points are too coarse grained a measure, and teams should now have a reasonable insight into the required work. The amount of ideal time a developer has during a day varies depending on company, environment and many other factors and will become obvious as the project progresses. (In the first few iterations, it is possible that not all of the committed user stories will be completed. But these commitments are internal and are more about planning an order of development than meeting targets.)
5. Ask the team for a commitment to complete that story within the next iteration
This is a unified commitment made by the whole team based on how much estimated ideal time they have already committed to. Usually it works best if the sum of ideal time is equal to about 4-6 hours per person per day. If the team can commit, add that story to the iteration plan. If they then have reached their limit in ideal time, then you are finished, otherwise select another story and repeat.
Now, I'm sure there aren't many people who are completely unfamiliar with the idea of a task board. However, these are essential during each iteration of an agile project. A task board has various columns:

This allows you to easily see what tasks are still to do for each user story, whether the tests are ready for that story, what tasks are in progress, and the estimated amount of hours left for that story. Tasks are not moved to in progress until they are claimed by team members, which happens throughout the iteration. It is recommended that the tasks for a story are not started until the tests are ready, this way development can be test driven, rather than testing after the fact.
Tracking effort expended can be useful for improving estimates, however it is important to not put pressure on the estimators. If there is pressure to produce accurate estimates, then people are more likely to expand the tasks to fill the estimated time or pad the estimates so that they are unlikely to overrun. Along this vein, do not track individual velocity, this goes directly against the agile "all in this together" principle. If individual velocity is tracked, people are more likely to be focused on completing as many tasks as possible and are therefore less likely to help someone else with an issue they're having. It can also mean that the quality suffers because it is all about how fast a developer can tick off a list of tasks.
Overall
The important things to remember about agile estimation and planning are as follows:
- As knowledge is gained and more progress is made through the project, re-planning allows you to reduce uncertainty around delivery.
- Teams work far better when they are of a unified mindset, monitoring team members individually or splitting teams into "devs", "testers", "database specialists" etc. is counterproductive. Estimating should all be carried out as a team.
- Planning is done at different levels: iteration planning provides structure; release planning provides direction.
- Planning based on prioritised features rather than tasks keeps the focus on providing value rather than assigning and completing work.
- Smaller stories and cycles keep up momentum, there is less of a "relaxed start" and "frantic end" in shorter iterations, resulting in a more constant flow of work. Also this allows for a shorter feedback loop, keeping the project on track and mitigating risk as you progress.
And finally, always, always, acknowledge your uncertainty. No estimate or plan is ever 100% accurate and pretending otherwise is, I think, the problem at the heart of software estimation.
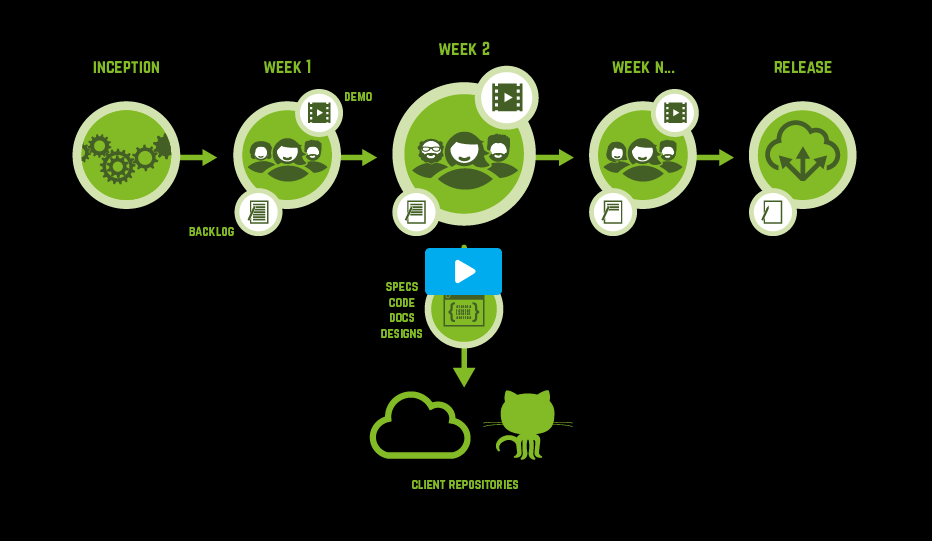
We reflect these principles in the delivery process here at endjin, where we work in iterations and provide weekly update videos to maintain our feedback loop. If you want to know more about our delivery process, I recommend giving this video a watch!