FabCon Vienna 2025: Day 1


Jess and I recently attended Microsoft FabCon (Vienna) - a twice yearly conference dedicated to Microsoft Fabric. Many topics were explored as part of the conference; unsurprisingly a lot of the content was focused around data and data engineering, but there were also many sessions on monitoring, security, governance, AI, and much more. This highlights the importance and positioning of Fabric as an all-encompassing tool for data engineering and exploration.

This post will run through day 1 of the conference, which was absolutely full to the brim with announcements.
Key Note - Microsoft Fabric: The Data Platform for the AI Frontier
Sadly the Vienna transport system failed us on the first full morning of the conference, meaning that we (and many others) had to walk the ~40 minutes to the conference centre - we'll have to wait and see whether the pilgrimmage of Fabric enthusiasts over the Danube makes it into the history books... But this meant that we missed the first 20 minutes of the Keynote, and when we arrived the announcements were already in full flow.
Developer Productivity
The first section that we saw was announcements about developer productivity, including:
- MCP Servers for Fabric
- All of the Fabric items are now supported in Git and CI/CD - which is a huge step forward for productionising the platform.
- Tabulated view: You can now view multiple items at once, including multiple lakehouses and workspaces - which will make a big difference in productivity. I've definitely been annoyed at having to go and re-open things when moving around in Fabric so far! The tabs for different workspaces will show up in different colours, making it obvious which you're looking at.
- You can now use variable libraries in shortcuts
- The Fabric 2.0 runtime (including Spark 4.0, and Delta 4.0).
- Materialised lakeviews now with incremental refresh, general perf improvements, and native execution engine
- AI functions in Data Wrangler

Data Warehouse
- General performance, scale and migration improvements
- Warehouse migration assistant (upload a dacpac)
- Graph capabilities now in Fabric - you can use a no-code view to build up the graph and perform graph-based analysis. It's a shame that at present this feature only exists for data warehouses, and isn't available as a view over lakehouse.
- New Event House endpoint
- Real time automated anomaly detection using ML
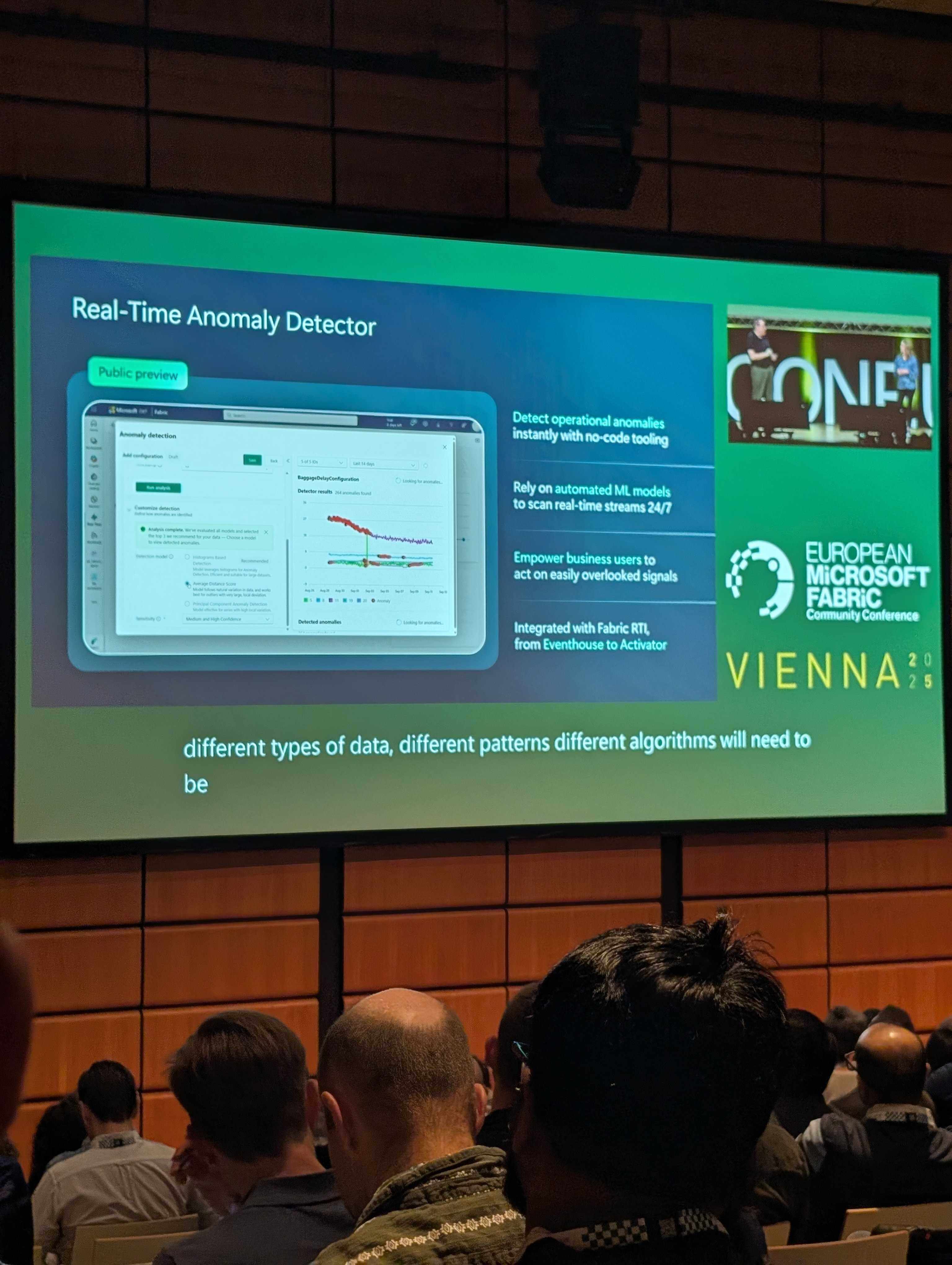
- User defined functions for calling store procedures and AI functions
- And, you can now call UDFs directly from Power BI, passing in measure values. This means that you can have parameterised write-back into your data, and perform analysis based on those values, which could then in turn be used to update the Power BI report. A powerful tool for interactive reporting!
Data Factory
There were two announcements around performance:
- Faster data previews in Data Factory
- And, Modern Query Evaluator provides huge performance improvements for Data Flows

Alongside this, the prices for Data Flow Gen 2 (CI/CD) have been decreased, using a two-tiered approach:
- First 10 Minutes: 12 CU (25% reduction)
- After that: Drops to 1.5 CU (90% reduction)
This combined with the performance improvement (decreasing time-spent) should make a big difference in overall costs.
OneLake:
- New Shortcut endpoints: Azure Blob and Azure SQL MI,
- New Mirroring endpoints: Oracle (preview), Google Big Query (preview)
- OneLake table API, introducing Iceberg and Delta Lake standard APIs, for greater interoperability, with anything that can understand the new table endpoints.
- OneLake storage diagnostics has been announced, which allows for diagnostics and audit over all data in OneLake, including shortcuts and mirrored databases.
- New security centre (tab) in Microsoft OneLake for increased security management.
There was a lot more on this in the OneLake CoreNote later in the day!
Power BI:
- Power BI modelling in the web is now supported. This was a theme amongst the Power BI announcements - with the aim of reaching feature parity between the web and desktop experience - opening the foor for MAC users!
- Button slicer in GA
- Bard visuals in GA
- Copilot in Power BI apps (public preview). This is a great feature that allows you to use Copilot within your apps. You get returned visuals on-the-fly to answer the questions you ask. And, you can also use this functionality to discover reports within the application that might be of interest given the context.
Again, there was more on this in the Power BI CoreNote.
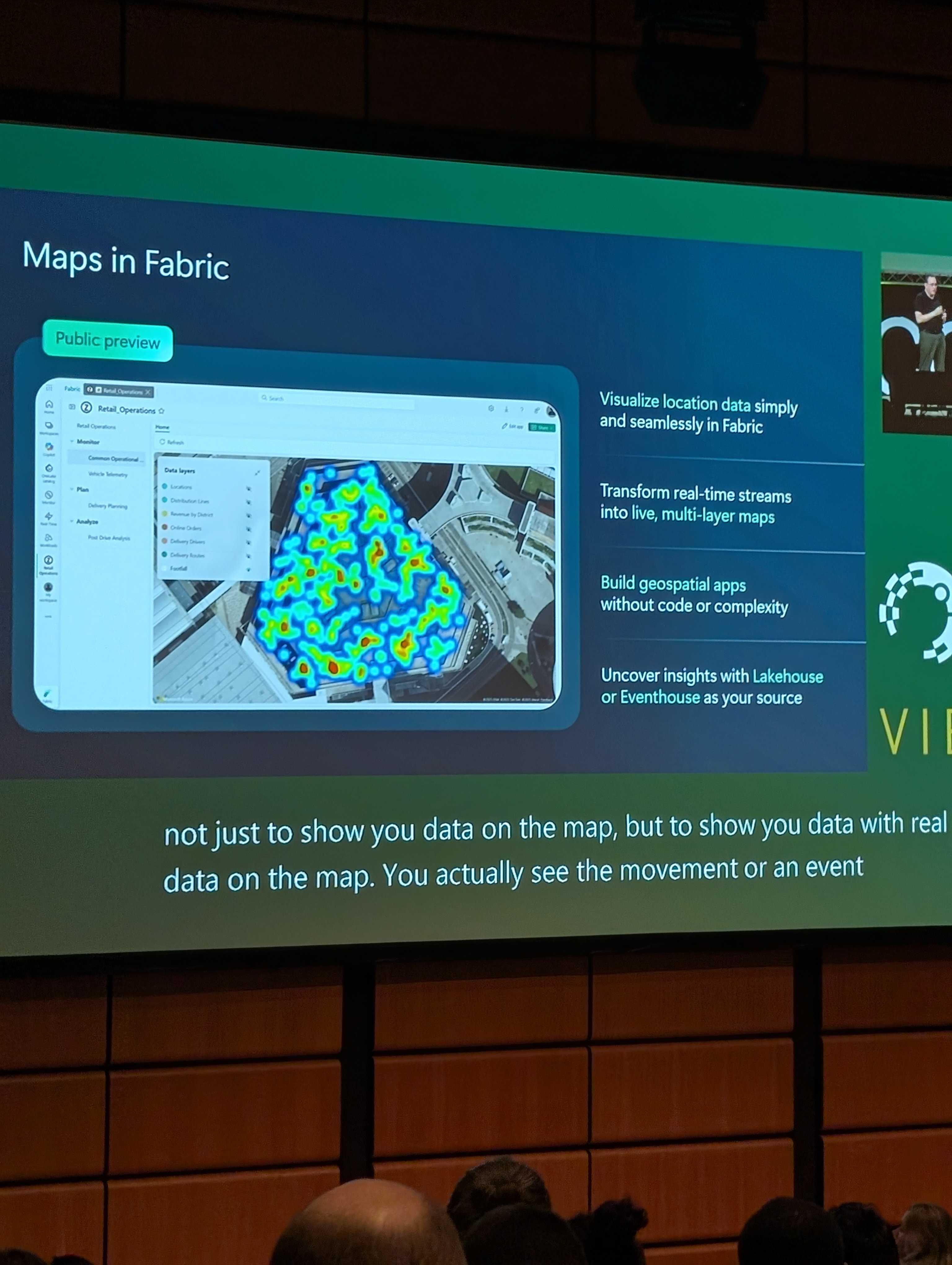
Maps in Fabric
This is a new Geospatial feature in Fabric used for displaying data on a map. This is separate to the new map visuals in Power BI (though looks to be powered by the same ArcGis technology) (EDIT: It is not powered by the same ArcGis technology!). You can display realtime data, and build up performant map layers. The maps are also very customisable, letting you display a huge breadth of data at once.
CoreNote - Fabric Data Factory: What's New and Roadmap
The next session I attended was the Fabric Data Factory CoreNote, where we explored some of the announcements in more detail.
Again, this was mostly running through a list of announcements.
Here is an overview of the roadmap:

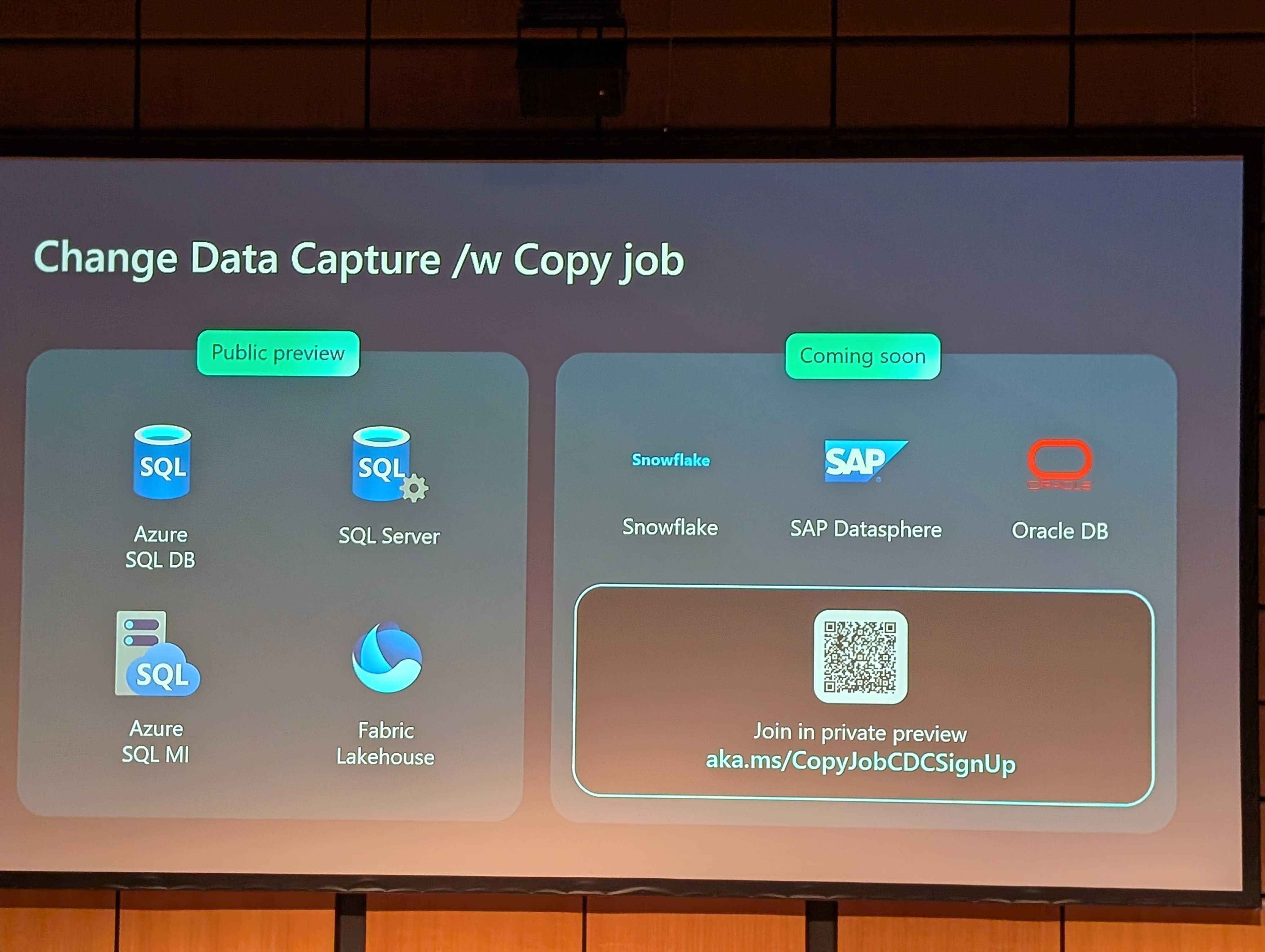
There were a few announcements around copy jobs, including:
- New connectors:
- The new "Copy Job Activity" in pipelines
- Support for Change Data Capture in Copy Jobs (in preview) - meaning that you only replicate changed data from a source.
- And, you now have the option to "Reset Incremental Copy" - which allows you to perform a full re-ingestion on the next run.
Outside of this,
- The session re-touched on the Data Flow improvements
- Went into the new built-in debugging and testing of expressions in pipelines - incredibly useful as typos in pipeline expressions can be very hard to spot!
- You can also now use Copilot in Data Factory to create transformations in Power Query and write pipeline expressions This will massively improve productivity in these environments.
- Support for multiple schedules, granting much more flexibility in how you trigger your pipelines.
- And, the addition of interval (tumbling window) schedules
There was also a section around OneLake, but given I attended the OneLake session later in the day I won't go into detail on that here.
Then they talked about the preview of Business Process Solutions, which includes prebuilt models, reports, dashboards, and AI agents for standard business processes, including integrated security and compliance. Currently the solutions focus on:
- Finance
- Sales
- Manufacturing
- And, procurement
I'm interested to see how flexible these models actually are in catering for real-world process analytics.
As mentioned in the keynote, everything is now supported in Git. There is also additional support for Workspace Identity and networking.
Here is a summary slide of the announcments:

CoreNote - Power BI Roadmap: Strategy, Vision and Demos
As I'm sure you've guessed by now, the CoreNotes throughout the day followed a similar line - exploring the wealth of new features and functionality, so this time, in Power BI...
Data Visualisations
- As mentioned earlier, card visuals are now GA. You can add image heroes and customise them in a lot of different ways, which adds a lot of visually interesting options in reports.
- Button slicers are also generally available. This includes partial highlighting based on data selection, and customisation.
- There is additional image support where you can change the image on hover over or click, which can add an interactive feel to reports.
- There are new Azure Maps features, coming with the replacement of Bing Maps, which allow you to add path layers and customise the base map.
- And, you can now create organisational themes, which will have a huge impact for people who need to create many different reports within an organisation whilst preserving a coherent look and feel. Certainly for us we have long term clients for who we have created hundreds of reports. This will mean reduce the manual effort involved in creating new reports, and ensure that theming is completely consistent.
- Performance analyser is also now available in the web, continuing the theme of enabling web feature parity.
Semantic Modelling
- As mentioned earlier, semantic modelling is now available on the web.
- Report creation is also now available in the web
- Best Practice Analyzer and Memory Analyzer are now generally available. These allow you to use a one-click Fabric notebook to identify improvements to your models.
- Modelling over Direct Lake and import models in now available in Power BI desktop and on the web (preview)
- Tabular Model Definition Language (TMDL) is now generally available. This is a code-first way to define your semantic models. Not only does this cater for those of us who would rather use a code-first than visual approach, it is also useful for large-scale model editing.
- You can now choose whether you want to refresh data, schema or both in Power BI Desktop
- And, there have been some exciting DAX improvements:
- You can now create User Defined Functions (preview). This allows you to define custom functions with parameters. As someone from a software development background, seeing DAX move this way is very exciting, paving the way for useful DAX utility libraries and reusable functionality.
- Customised time intelligence - you can now define custom calendars, which enables huge flexibility in time-based analysis (you can, for example, define your calendar to coincide with the Fiscal year). You can also now perform week-based analysis, and work with "sparse date" columns, where not every date is represented.
- Copilot in DAX query view is also now GA - allowing for improved productivity whilst working on these queries.
Power BI Copilot
And then finally, around Copilot more generally:
There was a good demo about using the Copilot chat in a Power BI App. When you use it inside of an application, it is scoped to the data an the reports inside of that app. You can use it to gain visibility on the available data and reports, or ask specific questions, to which the answers may include on-demand visualisations, which can be edited and interacted with inside of the chat.
You are also able to "prep your data for AI" which means to add metadata which allows Copilot (and Fabric Data Agents) to better understand your data. There are a few things you can do:
- You can remove certain things from Copilot's view
- You can add descriptions to the sources in the semantic model, which Copilot will use to understand the context around the data.
- You can set up "verified answers" based on certain visuals, so that when users ask specific questions it knows where to get the answer.
- And, you can mark data as prepared for AI, so agents and users know that the model has been prepped for these use cases.
You can also now do this with Direct Lake.

And, there is now a Power BI Data Agent that you can connect to from M365 Copilot. This means that you can have these data exploration and report discovery conversations (with all the in-place visuals) directly from M365 Copilot.
CoreNote - Unify your Data Estate with OneLake - the OneDrive for Data
The next CoreNote was on OneLake - the storage technology which powers Fabric.
There was quite a deep dive in to OneLake Catalog, which is a powerful tool for discoverability, tagging, governance etc.
A question I had was how OneLake Catalog related to Purview. Someone asked this exact question and got an answer along the lines: "Purview is an enterprise catalog solution, OneLake Catalog is designed to Catalog all of your data estate. There are integrations between the two, meaning that you can encompass your OneLake Catalog data within your enterprise solution". To understand a bit more about how this works in practice, keep your eyes open for coming deep dive on the topic!
There was then an exploration of shortcut transforms. Shortcuts allow you to create a pointer to data stored in another system (within Azure, or elsewhere - e.g. in other clouds such as S3) without replicating the data. Shortcut transforms allow you to automatically apply transforms as part of this process, for example, transforming from CSV to Delta. This specific transform has been available for a little while, but you can also now transform between Parquet and Delta, and JSON and Delta, as part of the shortcut. Alongside this, there are also new "AI Transforms" which allow you to do things like sentiment analysis without setting up an entire ETL process.
They then focused on how you can use mirroring to bring catalogs together. Mirroring syncs the metadata from whatever service you're using (be that Databricks, Snowflake, etc.), and then, if the data is in an open table format, uses shortcuts to mirror the data itself. For proprietary data, it creates a replica and uses change management to keep it up to date. More on this in day 2, where we attended a deeper dive into shortcuts and mirroring in OneLake!
You can also now use Fabric Agents over shortcuts and mirrored data - meaning that you can include this data in your natural language queries, and connect to it from Azure Foundry.
As mentioned earlier, shortcuts to Azure Blob Storage and Azure SQL MI are now GA. And, mirroring support for Oracle and Google Big Query, and some SAP mirroring, is now in preview.
There is a new Onelake.Table API, which is interoperable with Snowflake, and can be used with DuckDB, Spark, and anything that can understand table endpoint.
As mentioned in the KeyNote, there is a new preview of OneLake Diagnostics, which allows you to monitor usage for audit and debugging, including for shortcuts and mirrored data.
There is also a new "OneLake Security Tab" which lets you view and define security within onelake, including mirrored items. This provides a centralised place for managing users and roles accross your data estate.
A lot of these OneLake announcements are hot off the press, so I'm sure we'll see more information about what's on offer and examples of usage in the coming weeks.
CoreNote - What's next for Fabric Data Engineering: Roadmap and Innovations
The final session of day 1 focused on data engineering.
Ingest + Connect
- We re-touched on shortcut transformations
- You can now add data connections in notebooks. This involves adding a connection via the UI within the notebook, which then allows you to autogenerate cells containing the connection code. As someone who has to go and look up the syntax for these connections every time, this feels like a great quality of life improvement!
- The OneLake Catalog integration in Spark lets you explore available items from the UI.
- And, they demonstrated using the Spark Connector for SQL databases (announced in March) to read/write from SQL databases directly from Spark.
Configure + Scale
- For setting up new Spark tools, they are introducing the concept of "Spark Resource Profiles". Using these, instead of having many settings to understand and fine tune, you'll just answer a series of questions about your workload and the configuration will be fone for you.
- Coming soon: Custom live pools in Fabric! Until this point, anyone who wanted to use a custom pool rather than the starter pool had to pay a start up cost. With this feature, you'll be able to mark custom pools as "live and configure schedules and deactivation times.
- Fabric Runtime 2.0 is being relaeased, which includes Spark and Delta 4.0. Alongside this, they are releasing a feature called "early runtime access" where you can try runtimes before they are put through to full release. The idea with this is that you can set up a test environment and migrate that over early. If anything breaks, you can then report this to the Fabric team and they can take this into account before releasing.
- There have also been some big performance improvements over the past few months for the Native Execution Engine. The headline figure is that, using this engine, you can achieve up to 6X faster performance than using OSS versions of the Spark runtime. You currently need to enable the use of the native execution engine (which I'd definitely recommend doing if you haven't already!), but eventually it will be turned on by default. There are still cases where processing will "fall-back" to normal, but the scenarios the engine can cope with are increasing all the time - for example, CSV support is coming soon!
- There also should be big performance improvements for installations when publishing environments coming in October, and faster session start up times when you've got custom libraries installed!
- And, finally, you can now share sessions across up to 50 notebooks, rather than the current 5. This is a big win for avoiding those start up times when doing concurrent work in Fabric environments. However, it is worth noting that if you are working in many notebooks concurrently, you need to watch out for "out of memory" exceptions, as the nodes' memory will be shared!
Transform + Model
Alongside the "quality of life" improvements in configuration, there have been quite a few improvements specifically for notebooks:
- You can now see notebook version history across multiple IDEs, allowing for much more flexibility.
- User defined functions can be accessed directly from notebooks, they are now discoverable via intellisense, and you can now pass dataframes.
- Improved error messaging in Fabric notebooks.
- Insights into why Spark pools might be taking longer to set up e.g. Fabric starter pools all in use, rare but a possibility.
And, there is a new Spark Monitoring library, and improvements in the monitoring tabs, which allow you to see what's going on in notebooks whilst they are running. You can use the monitoring library from a notebook to get insight into job statistics like run durations, number of queued/rejected/running jobs, and how many cores are in use.
And soon, you'll be able to see resource allocation across a workspace, and across the whole Fabric capacity.
Alongside this,
- The Notebook utils APIs are now generally available.
- They have added much better GeoSpatial support, using the ArcGIS technology, adding 180+ geospatial analytics functions to Fabric Spark.
- There are new AI functions available in Data Wrangler.
- Python notebooks are now generally available.
- Python 3.1.2 is coming soon.
- And, you will soon be able to connect to the real-time hub directly from the Notebook object explore.
A lot of this is still "coming soon" but they assured that the majority should be done this quarter. You can see that there's a huge wealth of exciting new functionality and features coming, both in the data engineering space, but also in Fabric as a whole!
Overall
That's a wrap on FabCon Day 1, look out for the next blog which provides a summary of day 2, where both me and Jess attended more technical "deep dive" sessions. Hope you've enjoyed this announcements firehose, I certainly feel excited by the direction that Fabric is going, and am looking forward to exploring some of these new features myself over the coming months!

If you're interested in Microsoft Fabric, why not sign up to our new FREE Fabric Weekly Newsletter? We also run Azure Weekly and Power BI Weekly Newsletters too!



