What is OneLake?


If you haven't already read my Intro to Microsoft Fabric blog, then please go and check that out for a full introduction to Microsoft's new, SaaS based end-to-end analytical platform.
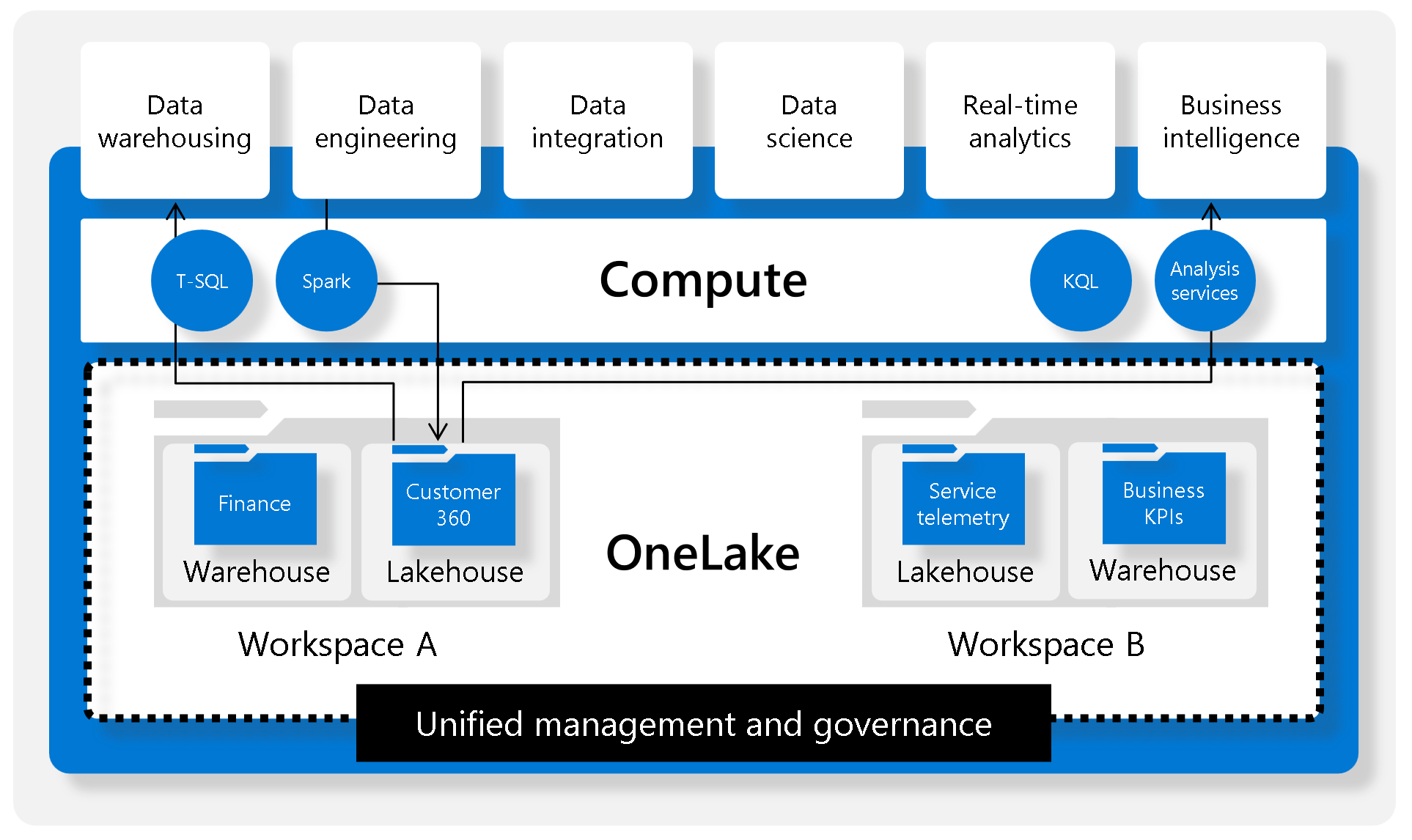
OneLake is the core of Microsoft Fabric - it is essentially the storage account for all of your data utilized within Fabric, be that within Azure or from another cloud*. As the name suggests, it is a single, logical "data lake" backing more or less all of your Fabric workloads. For fans of analogies: you'll have probably heard Microsoft use the tag-line "OneLake is to data what OneDrive is to files/documents".
When thinking of the modern data principal of "separating storage from compute", OneLake is the "storage" element. It has been designed in such a way to enable multiple compute engines to seamlessly integrate and interoperate with the underlying data stored in OneLake. To see all these corresponding "compute" options, check out the Intro to Microsoft Fabric blog post.
See the information about "Shortcuts".

Why should I care about OneLake?
The goal of OneLake is to provide a single place to land all data, and in the process break down data silos and simplify management (security/governance/data discovery) for your organization's data. It encourages distributed ownership of organizational data, by making it easier than ever to share data without duplicating it.
Currently, data lake services in Azure are offered as PaaS. The most notable service being Azure Data Lake Storage Gen2 (ADLS Gen2), which needs to be provisioned, configured and managed by someone familiar with Azure. OneLake comes provisioned by default with Microsoft Fabric, removing that initial barrier.
There also tends to need to be a bit of up-front planning with regards to storage account/file system/folder structure. Do I need multiple ADLS Gen2 instances? Or can I segregate my data by file systems? Or by directories? What about my data tables vs my raw data - how are they separated? Do I need to worry about performance/scaling? With OneLake, there is only one logical account - though naturally that concept doesn't equate to all data having to reside in a single location or all data having the same access rules - that type of thing will be configurable. That's because there's likely multiple storage accounts that have been provisioned under the covers, which also makes performance less of a concern. OneLake also introduces the separation of Tables and Files. "Tables" being your managed data tables created via one of the compute engines, "Files" being just that - files. Separating these concepts out physically allows Fabric to provide UX enhancements on top of your data, with auto-discovery of certain artifacts so long as the patterns are followed.*
See the information about "Structure" further below.
Key OneLake concepts
Shortcuts
Shortcuts are a very cool feature allowing you to "virtualize data across domains and clouds" into your OneLake. They essentially allow you to connect to your data which reside elsewhere (think "symlinks"). This could be files/tables from other Fabric workspaces, or external ADLS Gen2/AWS S3 accounts.
This will reduce the need for duplication and unnecessary data copy, but only if your source data is stored in one of the above data stores. Maybe other supported "shortcut" sources will come in the future.
What you shouldn't do is shortcut every data source you have just for the heck of it. Naturally, you should still work "right to left" when delivering a data pipeline; define your Actionable Insights and pull in only the data you need for those well-defined outputs.
Shortcuts can be created from any type of file, or indeed a "Delta" table. If you create a shortcut to a Delta table (created from Databricks, for example) and you place this shortcut at the top level of the "Tables" directory in OneLake*, then that Delta table should be automatically recognized and made available for querying in your Lakehouse. Which is pretty cool.
See the "Structure" section for more information about the "Tables" directory.
Open access
Despite being a SaaS service, you can access OneLake data using existing ADLS Gen2 APIs/SDKs. So you don't have to be familiar with Fabric yourself to be able to access the underlying data, and there shouldn't be too much difficulty migrating solutions utilizing these SDKs to point to Fabric instead.
You might have heard the statement "support for industry standard APIs" from people talking about OneLake. This is a bit of a stretch - they're referring to OneLake being accessible via the ADLS Gen2 API. However, it's generally considered that AWS S3 is more of a standard, with many object-store tools claiming to be "S3 compatible" by replicating the S3 API interface as a baseline. I mean, even Snowflake have claimed that AWS S3 API is the industry standard in their docs. If everything's a standard, nothing's a standard.
One copy
OneLake follows the "One copy" principal, enabling data virtualization and the the reduction of duplicated copies of the same version of data in order to be operated on by other tools.
At a high level, the "One copy" tagline refers to the ability of any compute engine being able to query (note: not "update") a table created by any other engine within Fabric. This is because, for its data tables, Fabric utilizes the Delta open table format*. So it's not just Fabric compute engines - many other modern analytical tools that can read Delta can interface with the same Fabric tables out-of-the-box. This obviously leads to some level of de-duplication - hence "One copy".

However, when it comes to Lakehouses/Warehouses, "one copy" doesn't mean that there's a single, unified read/write table shared between Lakehouses & Warehouses. Rather, tables created by Spark (Lakehouses) can only be updated by Spark, and tables created by T-SQL (Warehouses) can only be updated by T-SQL. If you want to use both engines to update the same table of data, you can't (unlike Databricks/Snowflake). To benefit from both you'd have to create equivalent tables in both engines.
So features like IDENTITY columns and multi-table transactions aren't going to be possible in Fabric Spark notebooks, I'm sorry to say.
The Fabric team has been able to apply internal optimizations to the Delta tables that are written by Fabric, so that they perform optimally with the Fabric Data Warehouse SQL engine and the Power BI Direct Lake mode, while still adhering to the open protocol. These optimizations can be applied to Delta tables written by other tools, but those optimizations need to be managed from the Fabric side.
One security
This tagline is a bit tenuous. There is workspace level security (much like Power BI roles), artifact level security, and then compute engine level security (which may or may not grant access to OneLake). It is hoped that there will eventually be functionality where certain concepts (such as RLS/CLS) will be propagated across artifacts giving the impression of "one" security model - hence the tagline!
Structure
There's only one OneLake per tenant. It's a little like a storage account you might provision in Azure, where Fabric workspaces are the file systems (/containers, if you prefer) and individual artifacts that store data (e.g. lakehouses) are top level folders. However, unlike a storage account in Azure, these file systems can theoretically be in different regions, and access control for one workspace is totally independent from that of the next workspace, satisfying the data residency and security requirements you may have. So, to continue the analogy, I like to think of OneLake as a logical suite of Azure storage accounts, which is being presented as a single storage account to the end user. Think of it as "infrastructure virtualization" over internal storage accounts. SaaS FTW.
What this also means is that, theoretically there should be no hard limits on the storage account w.r.t. capacity or throughput (you'll probably note that there's nothing in the docs on this either). The main determining factor for performance will likely be on the compute side, which is a better problem to have.
Within certain artifact types (e.g. Lakehouses), you'll notice there are two automatic sub-folders. These are "Files" and "Tables". "Files" are just that - files. You can upload anything here, but generally it's where you'll store your raw data files, in whatever format they arrive. From then on you'll generally create managed tables using Spark/SQL Warehouses, the output from which will end up in the "Tables" folder, stored in the aforementioned Delta format.
This additional layer of organization provides a clear separation between the raw data and Microsoft Fabric managed data. Everything in the "Tables" folder is scanned by Fabric, and so long as it conforms to the known table format, it will automatically be made available in other Fabric artifacts, like Lakehouses (and, as a consequence, default Power BI datasets).
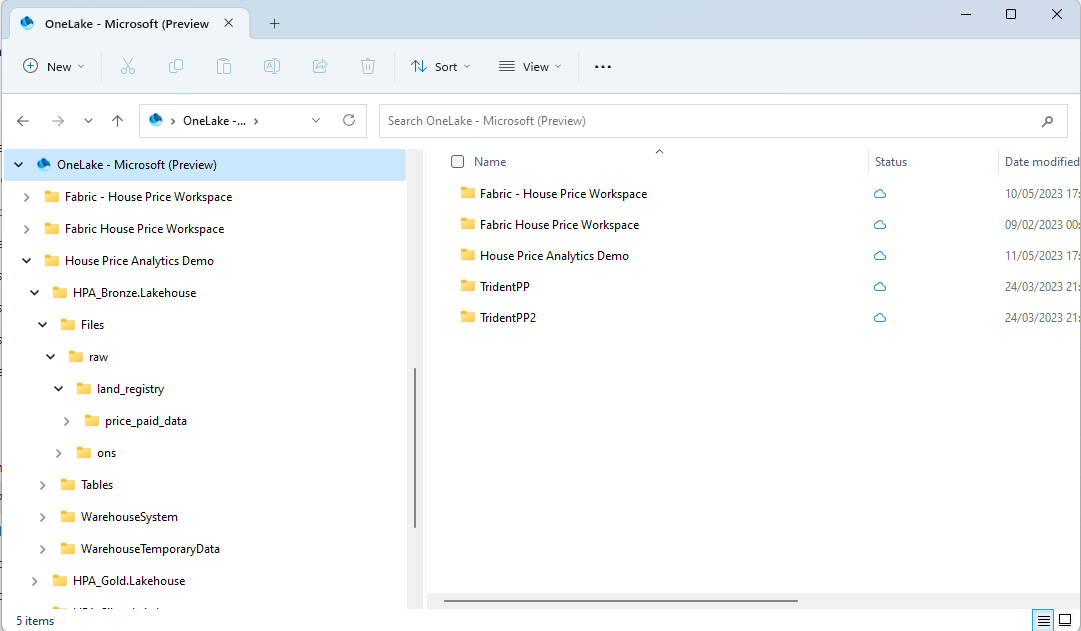
Exploring OneLake
Lakehouse view
This is viewed within the Fabric UI. Tables and Files can be browsed using a familiar folder structure, as per the below screenshot. Certain file types can be previewed (like CSV/JSON), other file types can't (e.g. parquet (boo)).

Azure Storage Explorer
You can browse your OneLake workspaces within Azure Storage Explorer. You need to use the "ADLS Gen2 Container or Directory" connection type, and therefore you'll be connecting at the workspace level.

OneLake File Explorer
A very cool feature that's been released is the OneLake File Explorer. This mounts your OneLake to your Windows file explorer, just like the OneDrive File Explorer. This makes it easy to upload/browse/interact with files locally. Note that files won't be automatically downloaded locally. If you need to interact with a file, then you must double click it to have it downloaded. This is a good thing, especially if you're working with large datasets!
ADLS vs OneLake
Which should you choose? Well, it's not really comparing apples to apples. But here are a few points:
- OneLake comes with Microsoft Fabric, so you're kinda forced to use it if you're already using Fabric.
- But if you have existing data platforms outside of Fabric which use and manage data in ADLS, you'll still need to have that external storage account
- The beauty of OneLake is that we can create Shortcuts to that data if we did need to consume the same data in Fabric
- This could be part of a migration path: e.g. Synapse Spark external tables stored in ADLS -> Shortcut in OneLake -> Fabric native files/tables
Other, more functional points:
- With ADLS being PaaS, you have more control over how data is secured and structured
- You may have instances where ADLS is being used as plain old object storage for non-analytical systems (e.g. an operational web app). Storing non-analytical data in Fabric doesn't make much sense.
Key benefits and drawbacks of OneLake
Benefits
- No infrastructure to manage (since it's SaaS)
- All organizational data stored in same, logical storage account
- Each worksapce can have its own admins/access policies/region assignment
- Unified governance policies easier to enforce
- Compatibility with most ADLS Gen2 APIs (and a subset of blob storage APIs)
- OneLake File Explorer
- Interoperability (enabled by using the Delta open table format)
Drawbacks
- Less configurable than ADLS (but that's SaaS for you!)
- One OneLake per tenant might make strict multi-tenanted Fabric scenarios harder to sell to the security team. A separated OneLake would require a separate AAD tenant (just like Power BI).
To conclude
OneLake simplifies the management of data while encouraging the sharing and distributed ownership of data. Certain features like Shortcuts are very exciting, which enable no-copy data virtualization across clouds. The embracing of Delta Lake as a table format opens up huge opportunities for integration across tools across the data ecosystem.
However, it is still very early days with OneLake and Microsoft Fabric in general. Will the shift to SaaS storage be a step too far for some storage Admins? Will it come with the perception of a "loss of control"? Will there be enough knobs and dials for Enterprises to fine-tune their networking and security set-up from one workspace to the next. Lots of things remain to be seen, but after having been on the private preview for 6 months, we're very excited with the direction of travel, and you should be too.



