Spark dev containers: writing tests


In this third post in my series on improving feedback loops for Spark development I'll show how we enable repeatable, local automated testing of Spark code that will ultimately run in a hosted environment such as Microsoft Fabric, Databricks, or Azure Synapse.
The gap
The normal way to use Spark from Python in a hosted system such as Databricks or Microsoft Fabric is via a notebook. When you create a new Python notebook in these systems, they make a spark variable available that you can use to access the Spark cluster that these environments supply. But they typically don't provide an obvious way to write and run automated tests.
When writing Python locally in a development environment, we can use a test framework such as behave to write tests. If we're using VS Code, it offers testing functionality that lets us run tests and view the results (or you can just run tests from the command line like in the olden days). This requires the code under test to be in .py files on our local machines.
But you can't just load up a .py file into a notebook. These are two different ways of writing Python code. If I write a local .py file so I can test it locally, how am I then going to run the same code in a hosted environment such as Fabric or Synapse, which expects my Python code to live in a notebook?

In fact there are a couple of ways we can deploy .py files to a hosted environment. The approach I'm going to show in this series is to put the code into a .whl package. We can then load that into Synapse, Databricks, or Fabric, after which you can invoke the code it contains from a notebook. (Another option is to create a Spark Job Definition. This can be more complex to set up, but it can be faster. That's because it avoids the package deployment step, described in the next blog, which can be quite slow.)
So our hosted notebooks do not contain any critical logic. They just invoke methods in these packages. During development, we run those same .py files locally, typically talking to a local Spark instance as discussed in an earlier post.
In this post, I'll show how we go about creating and running the tests locally, and in the next post I'll show how to deploy this tested code to a hosted environment.
A local Spark test
The simple example I'm about to walk through uses the Spark devcontainer set up last time as the starting point. (Not only will you need the devcontainer.json and Dockerfile, you will also need to have run the pip install pyspark==3.5.0 command.)
First, here's the code I will be testing—this is the actual application logic, and it will go into a heights.py file. For now I'll put this in my workspace's root folder, although when I get to package creation in this next blog in this series, I'll add some more directory structure, and this will move. But for now, putting this in the root folder will work:
from pyspark.sql import DataFrame, functions as F
def get_average_height(df:DataFrame):
return df.agg(F.mean('HeightInCm')).collect()[0][0]
def get_max_height(df:DataFrame):
# Note the deliberate error
return df.agg(F.mean('HeightInCm')).collect()[0][0]
These methods perform some very simple analysis over a table containing height information. The crucial feature is that this code gets Spark to do all the work. (I've also left a mistake in there, so I can check that the tests I'm about to write do actually work.)
I'll need a testing framework. At endjin, we are fans of BDD, so I'll install the behave package, which supports this style of testing:
pip install behave
There's a Behave VSC extension for VS code that we find useful for writing and running BDD tests, so I've also installed that. (Really, I should be updating my .devcontainer/devcontainer.json file so that this gets installed automatically, but that's out of scope for this post.)
By default, the Behave VSC extension expects us to put tests in a folder called features. So I'll create that and then create a file called features/heights.feature with this content:
Feature: statistical analysis of heights
Background: Load height data
Given I have loaded height data from the local CSV file 'data.csv'
Scenario: mean height
When I calculate the mean height
Then the calculated height is 106.0cm
Scenario: maximum height
When I calculate the maximum height
Then the calculated height is 183.0cm
In case you've not seen it before, this is a Gherkin file. Barry's blog describes some of the benefits in detail, but here, the most important point is that this .feature file describes the tests I'd like to perform.
The lines beginning with Given, When, and Then are steps, and the Behave test framework expects us to supply code that implements these steps. Conventionally these go in a folder called steps, which I'll create under features. I can then supply an implementation for these steps with this features/steps/height_steps.py file:
from behave import given, when, then
from behave.runner import Context
from heights import get_average_height, get_max_height
@given(
"I have loaded height data from the local CSV file '{csv_file}'"
)
def setup_loaded_height_csv(context: Context, csv_file: str):
context.height_df = context.spark.read.option("header", True).option("inferSchema", True).csv(csv_file)
@when("I calculate the mean height")
def calculate_mean_height(context: Context):
context.calculated_height = get_average_height(context.height_df)
@when("I calculate the maximum height")
def calculate_mean_height(context: Context):
context.calculated_height = get_max_height(context.height_df)
@then("the calculated height is {height_cm}cm")
def the_calculated_height_is(context: Context, height_cm: str):
assert context.calculated_height == float(height_cm)
Note that each of the methods here has been annotated with either @given, @when, or @then, which is how Behave knows which method to execute for each step.
The setup_loaded_height_csv method here loads data from a CSV file—it is invoked by this part of the .feature file:
Background: Load height data
Given I have loaded height data from the local CSV file 'data.csv'
Because I've described this as Background, it gets execute before each Scenario. In other words, both of the tests that this particular .feature file defines will be begin by executing this step that loads the data.csv file.

The data.csv file it refers to is in my root project folder, and it looks like this:
Id,Name,Hobby,HeightInCm
1,Ian,Lindy Hop,183.0
2,Buzz,Falling with Style,29.0
Notice that all of the methods in my height_steps.py file refer to context.spark. Behave supplies this context object. It passes it to each step, enabling a step to put things in the context that can be used by subsequent steps. The step that loads data puts it in context.height_df. The steps that invoke the actual methods under test retrieve that context.height_df, and then store their results in context.calculated_height, which in turn is inspected by the final @when step.
But where did that context.spark object used by my initial @given step come from? Behave doesn't know anything about Spark, so it won't put that there. I need to add some code to populate that with a Spark Context.
Inside my features folder I can create a file called environment.py, which gives me a place to put code that can set up my test environment. Here's my features/environment.py:
from behave.runner import Context
from pyspark.sql import SparkSession
def before_feature(context: Context, feature):
context.spark = SparkSession.builder.getOrCreate()
def after_feature(context, feature):
context.spark.stop()
That before_feature method name is special: Behave looks for a method with this name, and if it finds it, it will execute it before running the steps in each .feature file. Likewise, after_feature gives us a chance clean up after all scenarios in the feature file have been executed. In this case I shut down the Spark context, because you're not meant to create multiple contexts in a single process. (Behave also recognizes before/after_scenario and before/after_all so you can run code once for each scenario, and once for the entire test run.)
I now have all that I require. Because I installed the Behave VSC extension, VS code will be showing this flask icon on the column of buttons at the left of the window to indicate that there are tests:
![]()
If I click that, the Testing panel shows me my two test scenarios:

At the top, the third button (which looks like a double 'play' icon) will run all the tests. I had already done that by the time I took this screenshot, which is why you can see that the first test succeeded (it has a green tick by it) but the second failed (shown by a red cross). If I click on the failing test, it goes to the corresponding Scenario in my .feature file, and shows the details of the failure:
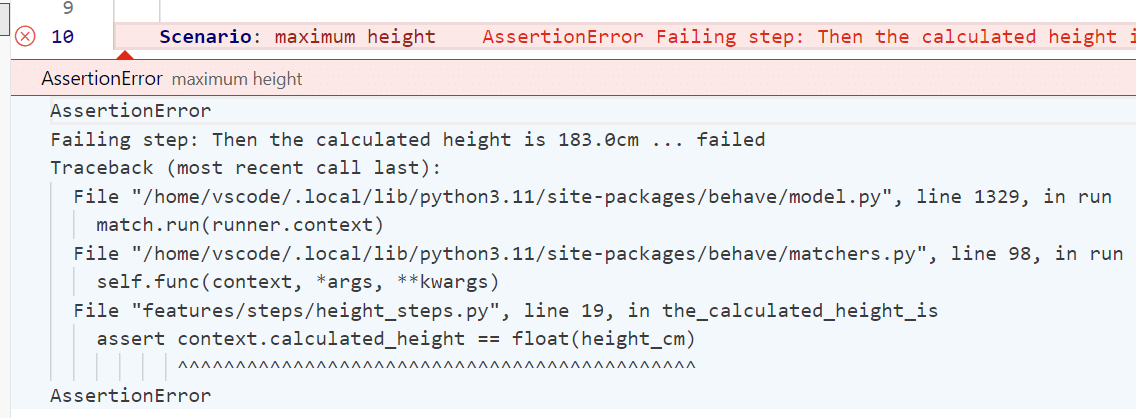
We can see the Python assert statement that has failed. In an ideal world I'd be able to double click that to be taken to the source file in question, but that doesn't happen with the current version of Behave VSC. It has told me that the failure is at line 19 of features/steps/height_steps.py.
I expected this error. It's because of the deliberate mistake I made in the code under test, repeated here:
def get_max_height(df:DataFrame):
# Note the deliberate error
return df.agg(F.mean('HeightInCm')).collect()[0][0]
I can fix this by using the correct Spark function in this aggregation (max instead of mean):
def get_max_height(df:DataFrame):
return df.agg(F.max('HeightInCm')).collect()[0][0]
When I run the tests again after this change, they all pass.
Wait, who started Spark?
I discussed this briefly last time, but it's worth re-iterating, because access to a Spark instance from tests is very much the point here, and yet it's not completely obvious how the Spark instance starts up.
It turns out that when you create a new PySpark context with SparkSession.builder.getOrCreate(), if you don't tell it exactly how to connect to Spark it choose 'local' mode, meaning it will actually launch a local Spark instance for you.
This works, although it isn't always the fastest way to run tests. My colleague Liam and I have recently been systematically investigating all of the different ways of creating Spark contexts for testing, to work out how to optimize the dev inner loop. We will be reporting our findings at some point in the near future.
Conclusion
I now have a test suite that checks the behaviour of code that relies on Spark to implement its logic. I'm able to run this locally, meaning I don't need to get access to a Spark cluster just to run my tests.
Next time, I'll show how to package up the application logic code (the get_average_height and get_max_height methods) so that we can take the code we just tested locally and run the exact same code up in our hosted Spark environment.



