What is a Lake Database in Azure Synapse Analytics?


If you navigate the official Microsoft docs, you'll get the impression that a Lake Database is just what's created when you use the Database Templates designer in Synapse Studio. Well, that's true. But it's not the only type of Lake Database, but this isn't made very clear in the existing documentation.
So what exactly is a Lake Database?
If we go by what appears under the "Lake Database" dropdown in Synapse Studio, a Lake Database is one of three things:
- A database created through the Database Template designer (see our blog series on this topic)
- A replicated database associated with a Spark database utilizing the shared metadata model (see What is the Shared Metadata Model in Azure Synapse Analytics, and why should I use it? for an example of this)
- A database associated with Synapse Link for Dataverse connections
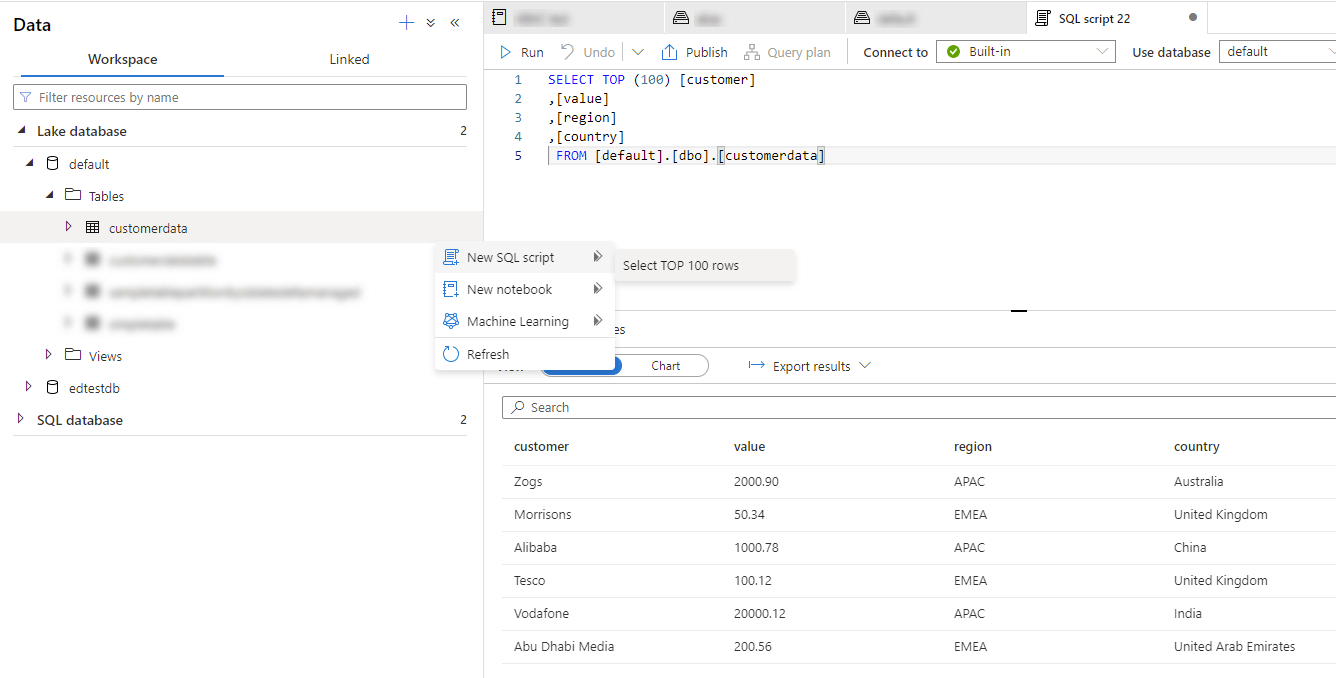
In all the above cases, underlying files of data are stored in your data lake. But they have been generated in such a way that registers the logical "tables" of data (associated with the underlying files) to the Synapse shared metastore (/shared metadata model), which allows them to be queried via database objects, instead of having to use the OPENROWSET command to query the underlying files.
So Lake Databases are effectively Database definitions over data in your data lake. These databases contain external table definitions, along with table location information, schema information, partition information (where applicable) etc. This provides the structure that allows you to query the external tables as if they were "normal" database objects in a "normal" SQL Server instance.
What are the differences between Lake Databases and SQL Serverless databases?
At face value, they're very similar. They're both means by which you can query data in your data lake. However, Lake Databases are special in that they're synchronized between the Spark and the SQL Serverless engines in Synapse. This functionality (albeit amazing) reduces the scope of what Lake Databases are capable of doing.

The feature set of SQL Serverless databases can be thought of as much more like that of a traditional Azure SQL Database/Dedicated Pool (formerly SQL DW). Of course, there are a number of things you can't do due to the nature of SQL Serverless databases (in that they query over data stored in a data lake, rather than stored on disk on the SQL Server machine). But many of the same operations work, including catalog views, certain system stored procedures, creation of objects like EXTERNAL TABLEs, VIEWs, STORED PROCEDUREs etc, the GRANTing of object level permissions to a granular level, the creation of EXTERNAL DATA SOURCE and CREDENTIAL objects, and so on.
Lake Databases, however, are more constrained. Under the covers, a Lake Database is a metadata-only replicated SQL database, containing a handful of EXTERNAL TABLE objects corresponding to the data you've defined in one of the above sources when generating the Lake Database. Up until recently Lake Databases were read-only, with the only type of object you had any "write" control over being the EXTERNAL TABLEs, but even these had to be managed through one of the aforementioned means (Database Templates, Spark code or Dataverse) - nothing on the database could be edited directly.
However, the read-only nature of these databases has now changed, with the new ability to define custom objects in Lake Databases. This expands the scope of objects you can create in the Lake Database, to include VIEWs, STORED PROCEDUREs, iTVFs, USERs and ROLEs. Certain custom objects can't be created from the SQL side, like non-synchronized EXTERNAL TABLEs.
When should I use a Lake Database?
The primary benefit of Lake Databases is the interoperability between the different compute engines (Spark and SQL). For example, you don't need to duplicate tables of data if you have created a database in Spark and want to be able to query that same data via T-SQL in SQL Serverless. Similarly with Synapse Link for Dataverse - you don't need to manually export the Dataverse data and manually create a new SQL Serverless database in Synapse just to be able to query that data.
If you want to query the data using SQL Serverless, you can do that (and performance characteristics will be largely identical to the equivalent query in a normal SQL Serverless database). If you want to query the data using Spark code, you can do that too, and the Spark engine will be used.

To be clear, here are the main scenarios where Lake Databases are a good fit:
- You want to easily query tables of data from both the SQL engine and the Spark engine
- You want to utilize the clicky-clicky-draggy-droppy Database Templates designer to generate a "database" structure over files in your lake
- Note - you can now point Database Templates at existing files in your lake and have it create a table definition from those files.
- You want to easily query your Dataverse data
Otherwise, you should just use a normal SQL Serverless database, with its much more rich feature set.*
*It's worth noting that the number of SQL Serverless databases you can provision is currently limited to 20. In contrast, the number of Lake Databases you can have is unlimited.
Limitations/considerations of Lake Databases in Azure Synapse Analytics
- It is a one-way sync. That is, you can't modify tables of data via T-SQL (within SQL Serverless) and have the changes sync back to the underlying source (be it Spark/Dataverse/Database Templates).
- Lake Databases have a more limited feature set than SQL Serverless databases (e.g. can't create custom
EXTERNAL TABLEs,EXTERNAL DATA SOURCEs directly in the replicated DB) - The only supported query authentication mechanism is Azure Active Directory (AAD). This can be an App/User/Group. You can't currently override this to use a SAS token/Client ID + Secret, for example.
- Therefore, as ever, the users would need to have necessary permissions to the underlying files in the data lake
Lake Databases - easy sharing of data across platforms and compute engines
Lake Databases in Azure Synapse Analytics are just great. If you're starting on a new Synapse Analytics project, chances are you can benefit from Lake Databases. Whether you need to analyze business data from Dataverse, share your Spark tables of data with SQL Serverless, or use Database Templates to visually design and define your standardized/semantic analytical data model, there's a use-case for you.