Customizing Lake Databases in Azure Synapse Analytics


It is now possible to create custom objects in Lake Databases. This means you can create objects like VIEWs, STORED PROCEDUREs, iTVFs (amongst other objects) on top of tables that are contained within your Lake Database.
Before we get any further, if you don't know what Lake Databases are, then take a look at my previous blog: What is a Lake Database in Azure Synapse Analytics?
Embelish your core data with some business/semantic logic
This feature allows you to add your business/semantic logic alongside the underlying tables they refer to.
Suppose you're using parquet-backed files and your column names therefore aren't very user-friendly (because you can't have whitespace). You ideally want to change these for end-users to incorporate whitespace (to make them more readable), as well as applying any semantic meaning to those names. Suppose you also have calculated columns incorporating business logic that you'd like to add to your underlying tables. This is where custom objects can help.

For example, you could create VIEWs which:
- Have more appropriate names/formatting for downstream consumption
- Have more explicit data types than those inferred by SQL Serverless
- Contain a subset of core columns while potentially creating calculated columns
JOINacross multiple of the core tables
You could even create a STORED PROCEDURE (like that mentioned in James' blog Managing schemas in Azure Synapse SQL Serverless) which, for example, contains some dynamic SQL to create VIEWs on the fly.
Before this feature, you had to generate a separate SQL Serverless database to create these custom objects. This was an issue because:
- You're now having to create a (largely unnecessary) additional database, when all you want to do is apply a wrapper over the core table. This effectively duplicates objects, and duplicates the number of things you need to manage, give USERs access to etc
- The number of SQL Serverless DBs you can create is capped (currently at 20)
So having to create an additional SQL Serverless DB was far from ideal. Additionally, up until this feature, it wasn't possible to give users access to a subset of Lake Databases - it was either all or nothing. This has now changed - read my article on Sharing access to synchronized Shared Metadata Model objects in Azure Synapse Analytics for more information.
"Default" Lake Database objects
Let's take the example I used in the What is the Shared Metadata Model in Azure Synapse Analytics, and why should I use it? blog, which created a simple, partitioned Spark table:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([
StructField("region", StringType(), False),
StructField("country", StringType(), False),
StructField("customer", StringType(), False),
StructField("sales_value", IntegerType(), False),
])
df = spark.createDataFrame(
[
("EMEA", "United Kingdom", "Tesco", 100),
("EMEA", "United Kingdom", "Morrisons", 50),
("EMEA", "United Arab Emirates", "Abu Dhabi Media", 200),
("APAC", "China", "Alibaba", 1000),
("APAC", "Australia", "Zogs", 2000),
("APAC", "India", "Vodafone", 20000),
],
schema
)
outputPath = "abfss://<filesystemName@<accountName>.dfs.core.windows.net/CustomerData/"
df.write.option("path", outputPath).partitionBy(["region", "country"]).mode("overwrite").saveAsTable("CustomerData")
The saveAsTable() command ensures that the table is registered in the corresponding Spark DB in the Hive metastore, which is synchronized with SQL Serverless. This is the shared metadata model in action, and is one of the methods by which you can create a Lake Database.
This CustomerData table can now be seen in the UI and queried as if it were a "normal" SQL database object:
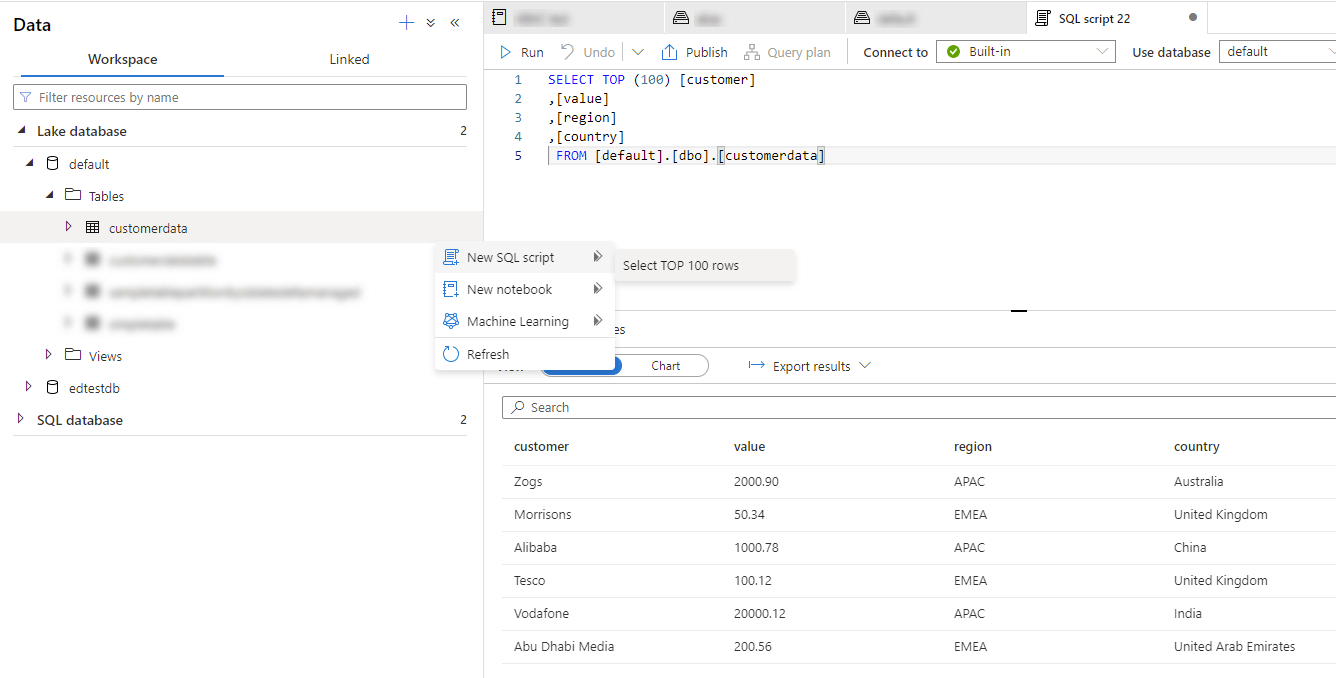 .
.
So, Spark tables (managed or external) are queryable in the Lake Database. Spark views unfortunately aren't available to query via SQL Serverless, since they require the Spark engine to process the query.
Custom Lake Database objects
You can now define the following custom objects:
- SCHEMA
- VIEW
- STORED PROCEDURE
- iTVF
- USER (see Sharing access to synchronized Shared Metadata Model objects in Azure Synapse Analytics)
- ROLE

Unsurprisingly, the dbo schema is not possible to customize - this is where the automatic synchronisation of objects happens from the various sources (Spark/Dataverse/Database Templates). So to create some custom VIEWs, for example, you'd first need to create a user-defined SCHEMA in which we'd define the VIEWs. For example:
CREATE SCHEMA [custom]
So that's one custom object already, albeit a bit of a boring one. Let's take a look at something more interesting.
The external table I've created above has the columns region, country, customer and sales_value. For some specific reporting purposes, I would like to make these columns more display-friendly and apply some semantic meaning to the names. Namely, I'd like to change:
region,countrytoRegionandCountrycustomertoClientsales_valuetoSales Amount
So how would that look in a query? Well, let's create a VIEW to encapsulate that logic:
CREATE VIEW [custom].[vw_reporting] AS
SELECT
[customer] AS [Client]
,[region] AS [Region]
,[country] AS [Country]
,[value] AS [Sales Amount]
FROM [db1].[dbo].[customerdata]
Unfortunately the Lake Database UI doesn't show these custom objects yet. But if you connect to the database in SSMS/Azure Data Studio, these objects are visible.
Let's suppose that we'd also like to cast some data types and generate a new column. We can now, of course, just do this:
CREATE VIEW [custom].[vw_reporting] AS
SELECT
CAST([customer] AS VARCHAR(30)) AS [Client]
,CAST([region] AS VARCHAR(50)) AS [Region]
,CAST([country] AS VARCHAR(50)) AS [Country]
,[value] AS [Sales Amount]
,[value] / 1.2 AS [Sales Amount no VAT]
FROM [db1].[dbo].[customerdata]
With the results:
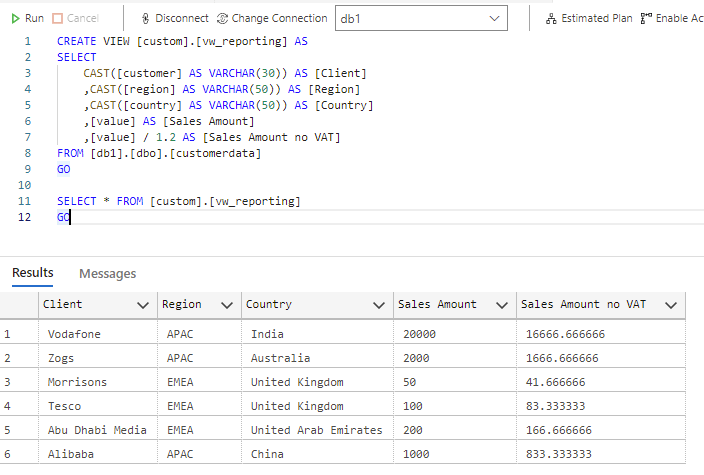
Hopefully you can see the utility here. No need for an additional SQL Serverless database just to contain simple logic layered on top of the underlying tables.
Limitations/considerations of Custom Objects within Lake Databases in Azure Synapse Analytics
I listed a series of generic limitations/considerations of Lake Databases in the previous blog What is a Lake Database in Azure Synapse Analytics?. However, those relevant to custom objects are as follows:
- Only custom
SCHEMA,VIEW,STORED PROCEDURE,iTVF,USERandROLEobjects are supported- For example, custom
EXTERNAL TABLEs (and thereforeEXTERNAL DATA SOURCEs) aren't supported. And therefore custom authentication isn't supported.
- For example, custom
- While
USERs can be created, more granularGRANTstatements can't be specified - only relevant Database Roles can be assigned. - The schema has to be different than
dbo(that's reserved) - As ever, the users need to have necessary permissions to the underlying files in the data lake
- As of October 2022, these custom objects don't appear in Synapse Studio
Custom Objects in Lake Databases - to conclude
Custom Objects are a perfect way to colocate your business and semantic logic. I think it's a shame you can't currently override the default authentication, nor create custom EXTERNAL TABLEs, but who knows - that may come in the future. But for now, this feature is a very welcome addition to the "swiss army knife" that is Azure Synapse Analytics.



