What is the Shared Metadata Model in Azure Synapse, and why use it?


It's a lesser spoken about area of Azure Synapse Analytics, hence this blog. Synapse has the capability to automatically synchronize tables created via Synapse Spark with objects you can query via the usual SQL Serverless endpoint. Synapse calls this the "Shared Metadata Model", though I've also seen it referred to as the "Shared metastore", so I'll use those interchangeably in this blog.
If you're creating Spark dataframes and writing data back to the lake, but want that data to be queryable via T-SQL, there's no need to manually create VIEWs over the top of that data in the data lake. Just swap .save() to .saveAsTable() and the table will be added to the (invisible) Hive metastore, whose metadata is then replicated behind-the-scenes to allow objects to be automatically queryable by SQL Serverless. This works for managed & external standard Spark tables, written in CSV or Parquet format. If you're using Delta tables, these aren't currently fully supported in the shared metastore (though hopefully that won't be the case for long!)
Example of the Shared Metadata Tables in action
Let's open a Spark notebook and create an external Spark table, partitioned by region and country:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([
StructField("region", StringType(), False),
StructField("country", StringType(), False),
StructField("customer", StringType(), False),
StructField("value", IntegerType(), False),
])
df = spark.createDataFrame(
[
("EMEA", "United Kingdom", "Tesco", 100),
("EMEA", "United Kingdom", "Morrisons", 50),
("EMEA", "United Arab Emirates", "Abu Dhabi Media", 200),
("APAC", "China", "Alibaba", 1000),
("APAC", "Australia", "Zogs", 2000),
("APAC", "India", "Vodafone", 20000),
],
schema
)
outputPath = "abfss://<filesystemName@<accountName>.dfs.core.windows.net/CustomerData/"
df.write.option("path", outputPath).partitionBy(["region", "country"]).mode("overwrite").saveAsTable("CustomerData")
Note the saveAsTable() command as opposed to just save(). This ensures the table is registered in the Hive metastore, which is synchronized with SQL Serverless. Functionally, that's the only thing it's doing differently to save(); it's still writing the underlying data files to the corresponding area of the lake.
Tip - Various ways to read Spark tables
This also means that within Spark, you can now query the data you've just written using Spark SQL (as well as the normal
spark.read.parquet("<path>")syntax):%%sql SELECT * FROM customerdata
or
spark.sql("SELECT * FROM customerdata")or even
spark.table("customerdata")
Now we've written that Spark table, we can pop over to SQL Serverless and query our newly created Spark table using T-SQL (and without requiring a Spark cluster). Navigating to the "Data" tab and then "Workspace", we see two dropdowns. "Lake database" and "SQL database".
Since we've created our table from Spark and without explicitly specifying a database, our table appears under the "Lake database" dropdown, in the default database, and under Tables. We can then right-click on the table (or hit the ellipsis), then select "New SQL script" > "Select TOP 100 rows", which will auto-generate a corresponding SQL query for us. It's worth noting that we're still using the SQL Serverless compute engine here, despite going through the "Lake Database" UI to generate the query.
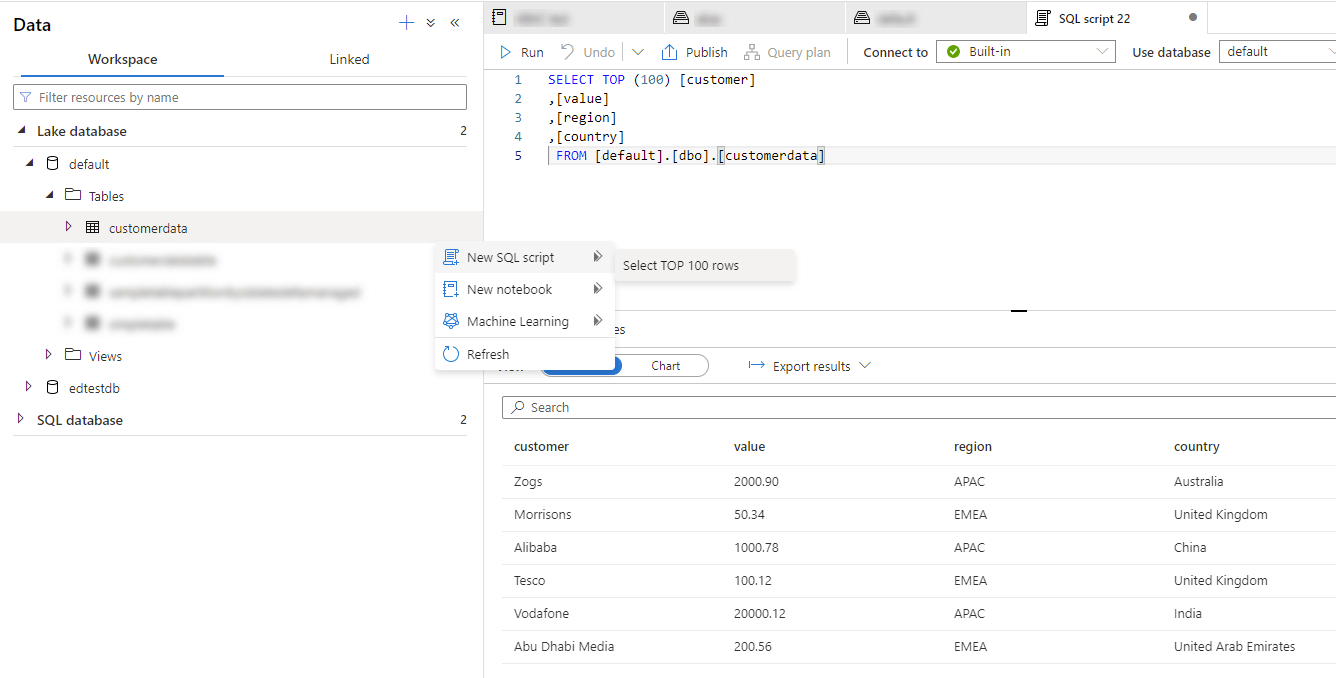
Et voilà. We are now querying the Spark table via SQL Serverless without having to create a VIEW.
A note on lake databases and SQL databases in Synapse:
- Lake databases are those written to the Hive metastore in one form or another. This could be via Spark Notebooks, Spark Job Definitions or Database Templates. A
defaultSpark database is available in every Azure Synapse workspace - this is used if you don't explicitly reference a different database when creating database objects within Spark.- SQL databases are those associated with dedicated pools or the SQL Serverless pool in your Synapse workspace.
The alternative - SQL Serverless query over underlying Spark table files
If you're interested, this is what the corresponding SQL Serverless query would look like:
SELECT
r.filepath(1) AS [region],
r.filepath(2) AS [country],
[customer],
[value]
FROM
OPENROWSET(
BULK 'abfss://<filesystemName@<accountName>.dfs.core.windows.net/CustomerData/region=*/country=*/*',
FORMAT = 'PARQUET'
) [r]

which could easily be turned into a VIEW. This query may not look very complex, but having to deal with URLs and partition extrapolation is a largely unnecessary undertaking here for what's effectively the same query.
Benefits and tradeoffs of the Shared Metadata Model in Synapse Analytics
The overwhelming benefit of this approach is that there's no duplication of objects. You create the object once in Spark, and it usually becomes available to query from SQL Serverless almost instantly (worst case within a matter of minutes). Note though that this isn't the case the other way round - i.e. VIEWs created in SQL Serverless don't get added to the Hive metastore, and therefore are not synchronized with Spark.
On the flip side, access management to the shared metadata tables can be a little fiddly (unless those accessing are already Synapse Admins). I'll share more about this in a separate blog.
Also, data types are inferred from the Spark table types. For types like integers and decimals, this is fine - 1-1 mappings exist from Spark to T-SQL types. But for StringType()s in Spark (varchars in T-SQL) for example, because Spark doesn't provide a way to specify the character length, these generally get inferred as varchar(max) in SQL Serverless queries, which is potentially sub-optimal when querying large amounts of data. In this scenario, you might be forced to create a VIEW over the shared metadata table anyway, so you can apply a more tailored schema using a WITH clause in your query. Though given a new update in SQL Serverless, applying specific data types to your queries may be less important than it once was (watch out for a separate article covering this!).
Wrapping up
The shared metadata model is certainly one of the hidden gems in Azure Synapse Analytics. There is no need to manually create and maintain VIEWs over underlying files in the lake for tables written by Spark - those tables will already be queryable through the shared metadata model. Less duplication, less maintenance.