What are Synapse Database Templates and why use them?


TLDR; in this five part blog series, we discover that Database Templates can provide a useful "contract" between those who are specifying a semantic models for downstream consumption and those working upstream to generate them. In this first part, we introduce Database Templates and explore the benefits that they are seeking to deliver.
Database Templates are a new feature recently added to Azure Synapse Analytics. We first heard about Database Templates at SQL Bits in London earlier this year (see my conference blog) where Vanessa Araújo (a Data Solution Architect at Microsoft) provided an introduction.
We got quite excited about the opportunities this new feature unlocks. Specifically, up until database templates became available, we have specified semantic models outside Synapse, using tools such as an Excel template or Visio diagrams. Database templates provide an opportunity to bring the specification of semantic models inside Synapse enabling a range of benefits that we explore in this blog.
What are database templates in Synapse?
Database Templates are metadata. They enable you to introduce structure to your Azure Data Lake Storage, allowing it to appear more like a relational system than a file system.

Database Templates are managed using a visual designer within Synapse Studio where schemas can be specified and evolved over time.
Behind the scenes, Database Templates are maintained within the Shared Metadata Model (an implementation of the Hive Metastore) within Azure Synapse Analytics. If you synchronise your Synapse environment with Git, a proprietary JSON definition of the Database Templates is stored alongside all of the other Synapse artefacts.
Database Templates comprise the following components:
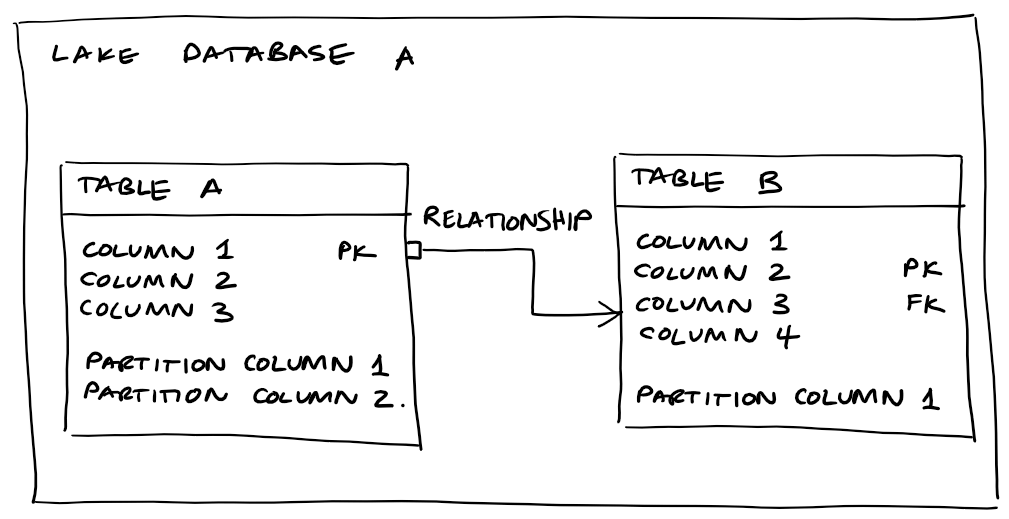
Lake Database - is a collection of tables, when you create a new database you also specify the location in the data lake where the underlying data should be maintained. You also specify how the data should be stored. At the moment, the options are delimited (CSV) or parquet format. We understand Delta will be added as an option at some point in the future.
Tables - a tabular data structure consisting of one or more columns. Tables are given a name and a description.
Columns - used to store data of a particular type such as string, integer, date of floating point number. You can also create "partition columns". These are columns with a suitable level of cardinality that can be used to partition the data in the data lake. Columns are given a name and description.
Relationships - captures primary key to foreign key relationships between tables
A data lake is typically seeded by raw data that is ingested from upstream operational platforms. Data which is extracted from operational systems is not typically "business friendly" or structured in a manner which makes it easy to analyse it downstream. Database templates can meet that challenge by bringing data together in a semantic form enabling it to be more easily consumed and understood, and for higher order activities such as analytics, machine learning and AI to be applied to it.
Synapse Analytics database templates can play a key role in enabling you to extract value from your data lake.
We believe Database Templates will deliver most value where they are used to specify the schemas to be adopted in the presentation layer of the data lake, this is illustrated in the diagram below:
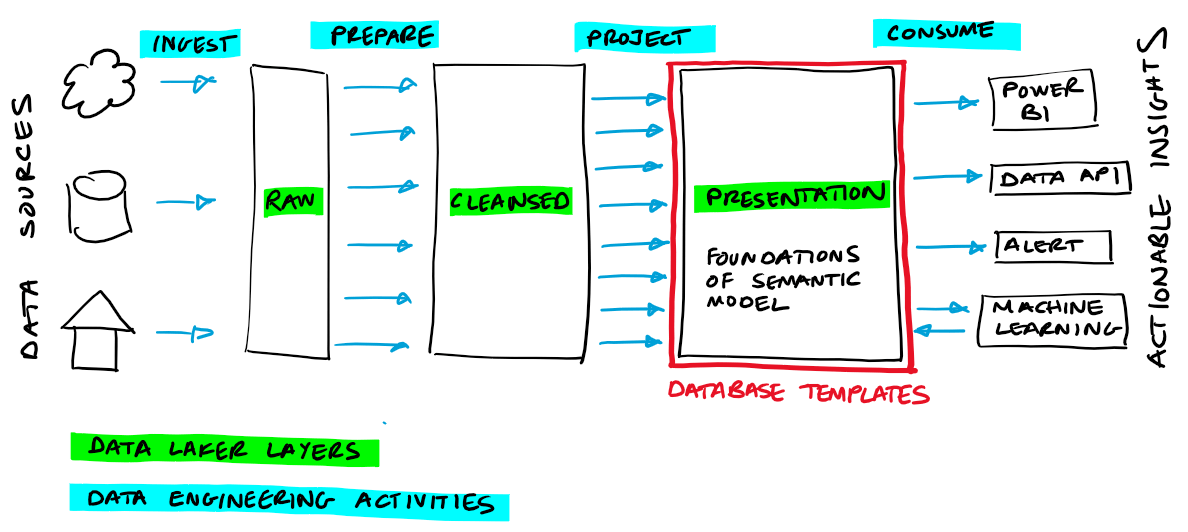
Under the hood, database templates are registered in the shared metadata model within Synapse. This means that they are first class citizens for both SQL serverless and spark workloads in Synapse. My colleague Ed Freeman provides a deeper insight into the shared metadata model in his article What is the shared metadata model in Azure Synapse Analytics, and why should I use it?.
What are the industry models?
Microsoft are making a big play of the "shrink wrapped" industry models which are provided along with the database templates functionality. These industry models have been prepared based on the experience gained over many projects across a number of common industry verticals. They are comprehensive and abstract in nature.
The majority of our customers work in industry sectors that aren't covered by the industry models. Even where there is a fit, we believe that many organisations will shy away from full adoption, perhaps using them as a reference point, or selectively choosing which elements to adopt and tailoring accordingly.

We also fear that the industry templates could distract organisations away from delivering value early. The industry templates may tempt them back to a more traditional approach which involves populating a large centralised model. This tends to prolong time to value and results in a model where compromises have to be made in order to achieve a "one design fits all needs". We think of them more as fully fleshed out examples of how to build domain specific templates, that could inspire you to model your own domain, rather than an off the shelf template you could use and adopt.
Finally, many organisations will lack the data literacy to successfully adopt an industry template on day one.
Our consultants prefer to think of the industry templates as something that organisations could perhaps "grow into" once they have built a critical mass of data in the lake, delivered actionable insights over this data data and have started to get a better understanding of the strategic challenges they face around topics such as master data and governance. At this point they will be in a much better position to understand the role that an industry model could play in supporting their strategic goals.
Why should you use database templates?
Database templates in Azure Synapse Analytics promise the following benefits:
Integrated tooling - by providing a tool that is integrated into Azure Synapse Analytics that enables you to design and publish the canonical form for a specific business domain, including the relationships between tables. This provides a non-technical way of defining semantic models, i.e. you don't need to know how to code for this part of the process. It also takes the friction out of designing semantic models outside of Azure Synapse Analytics, by removing the risk that the design and implementation will diverge. Ultimately, it gives a much broader set of people within an organisation the opportunity to become involved in specifying (and owning) the semantic models.
Collaboration - providing a single place to define the target semantic model which then generates the technical artefacts that engineers can use in development, you will open up opportunities for greater collaboration around the design and ongoing evolution of these schemas.
Schema enforcement, versioning and evolution - providing a single place in which to define the schema provides opportunities to enforce it and manage ongoing change, this includes consolidation of common elements (master data, conformed dimensions) and tooling such as source control to manage the DTAP lifecycle
Abstraction - allow data to be consumed using a logical database and table name which is decoupled from its physical location in the data lake. Allowing a common entry point across technologies used in Azure Synapse Analytics (SQL, Spark, Power BI, Mapping Data Flows and other ODBC compliant connections). This optimises the value chain (both upstream and downstream) by enabling the solutions to be simplified.
Discoverability - allowing data entities to be published for consumption and to have accompanying metadata that aid both discovery and successful consumption. This includes integration with Microsoft Purview (we will explore this in more depth in a future blog).
Power BI integration - a new Power BI Synapse workspace connector (in preview) that understands the model, including the relationships between entities, enabling easy and successful adoption of data that has been published for downstream analysis in Power BI.
Integration into DevOps (or DataOps) - if you synchronise your Synapse environment with Git, Database Templates are stored as JSON files alongside all other Synapse artefacts. So this enables them to be a first class artefact in your Azure DevOps pipelines. This allows you to apply change control, branches, pull request reviews to Database Templates alongside all of the other related artefacts (upstream and downstream) within Azure Synapse Analytics such as SQL scripts, notebooks, pipelines and mapping data flows.
Sounds great, does it work?
In a nutshell, yes it does work pretty well! But there are a few gotchas to be aware of. The best way to bring all of this to life is to step you through a worked example so we will do this over the next three blogs in the series:
- Part 2 - How to create a semantic model using Synapse Analytics Database Templates - steps through the process of using Database Templates to create a new semantic model from first principles
- Part 3 - Techniques for populating a Synapse Analytics Database Template - describes the different "upstream" methods that are available to populate a Database Template
- Part 4 - How to consume data that has been published in a Synapse Analytics Database Template - explores the different ways in which a Database Template can be consumed "downstream"
We will use this practical example to highlight the key features, technologies, limitations and considerations.
In the final blog Part 5 - Lessons learned from applying Synapse Analytics Database Templates. We will sum up everything we have found and make some recommendations.