Creating a semantic model with Synapse Database Templates


TLDR; in this second of a four part blog series, we explore the different methods that are available to create a semantic model using Database Templates in Azure Synapse Analytics.
In this blog, we will use a real world scenario to illustrate how Database Templates can be used to design a semantic model as core component in a modern data & analytics pipeline.
The scenario is concerned with delivering analytics to a housing development company that will enable it to choose the optimal locations to build new homes so that it can grow the business profitably.
The scenario picks up at the point in the lifecycle after a goal driven, persona orientated Insight Discovery process has been completed. In other words, the business centric analysis has been completed to specify the actionable insight and the data that needs to be provided to support it.

This blog picks up from the next stage in the process: which is concerned designing the semantic model that will enable the actionable insight to be delivered. A high level view of the semantic model has been sketched out as follows which adopts the star schema pattern as a data model which is optimal for downstream reporting in Power BI:
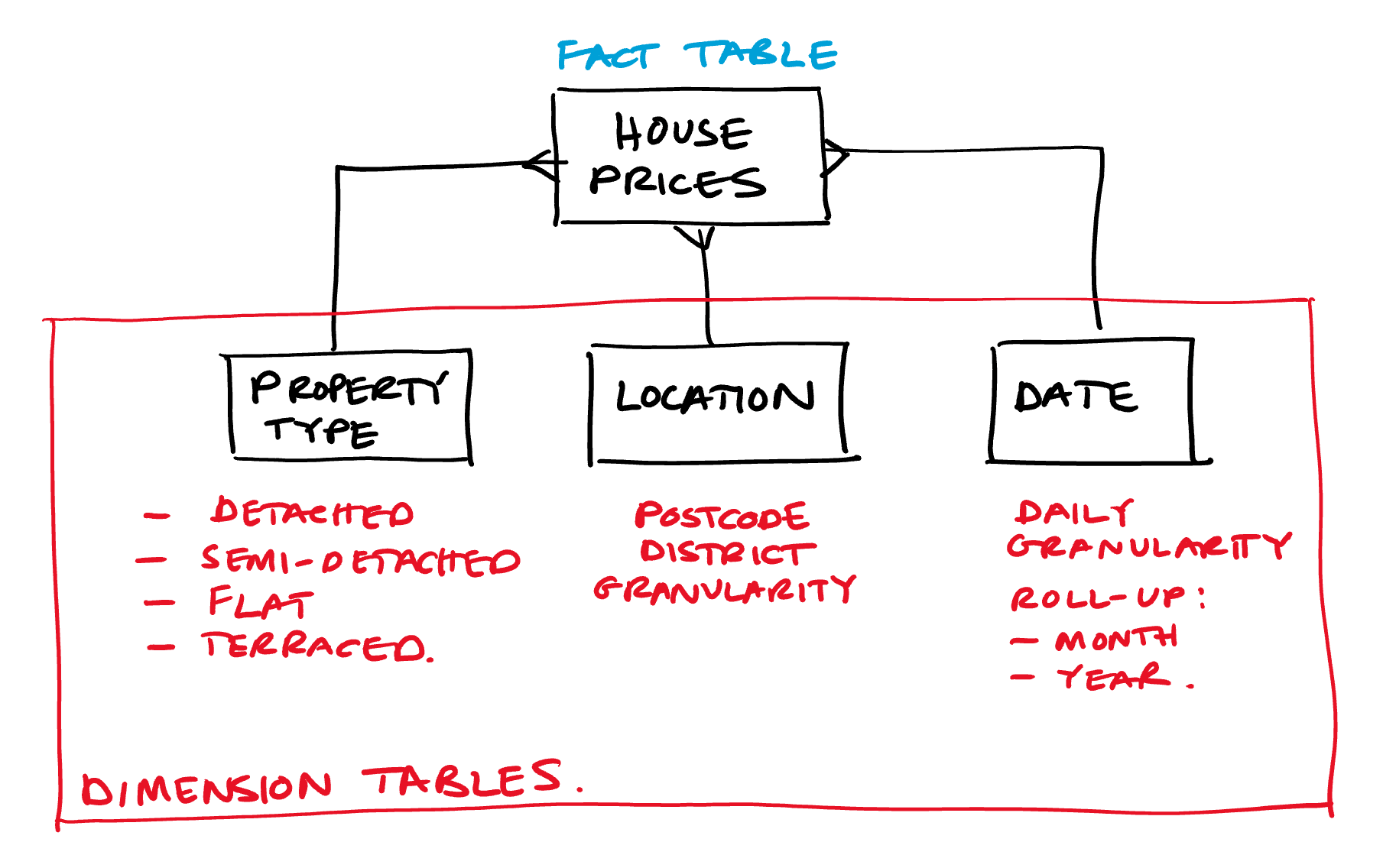
We are at the point in the process where we need to turn the conceptual high level design above into a concrete schema for the semantic model (tables, columns and relationships). We turn to the new Database Templates within Azure Synapse analytics complete this task.
The benefits of taking this approach to designing a semantic model are:
- Integrated tooling - Database Templates are integrated into Azure Synapse Analytics removing the risk that the design and implementation will diverge
- Collaboration - Database Templates provide a single source of truth around which a broad set of people within the organisation can collaborate to specify semantic models
- Schema enforcement - Database Templates encapsulate the target schema for your semantic model, allowing it to be leveraged during development and enforced at runtime
- Integration into DevOps (or DataOps) - if you synchronise your Synapse environment with Azure DevOps source control, Database Templates are stored (and versioned) as JSON files alongside all other Synapse artefacts, making ongoing change management slicker
We will explore five different methods that are available to do this:
- Method 1 - Create custom database template using user interface
- Step 1 - Create a new Lake Database
- Step 2 - Add table definition
- Step 3 - Add columns definitions to table
- Step 4 - Create relationships
- Step 5 - Check artefacts in source control
- Method 2 - Create database template from industry templates
- Method 3 - Create custom database template from files in the data lake
- Method 4- Create custom database template using Pyspark
- Method 5 - Create Database Templates using Synapse REST API
- Lessons learned
- Conclusions
We then round up with:
Method 1 - Create custom database template using user interface
Step 1 - create a new Lake Database
The start is to create a new Lake Database as follows:
- Log into Azure Synapse Studio
- Navigate to the Data menu
- Choose the + icon and select Lake Database
- You can now set up the new database as follows:
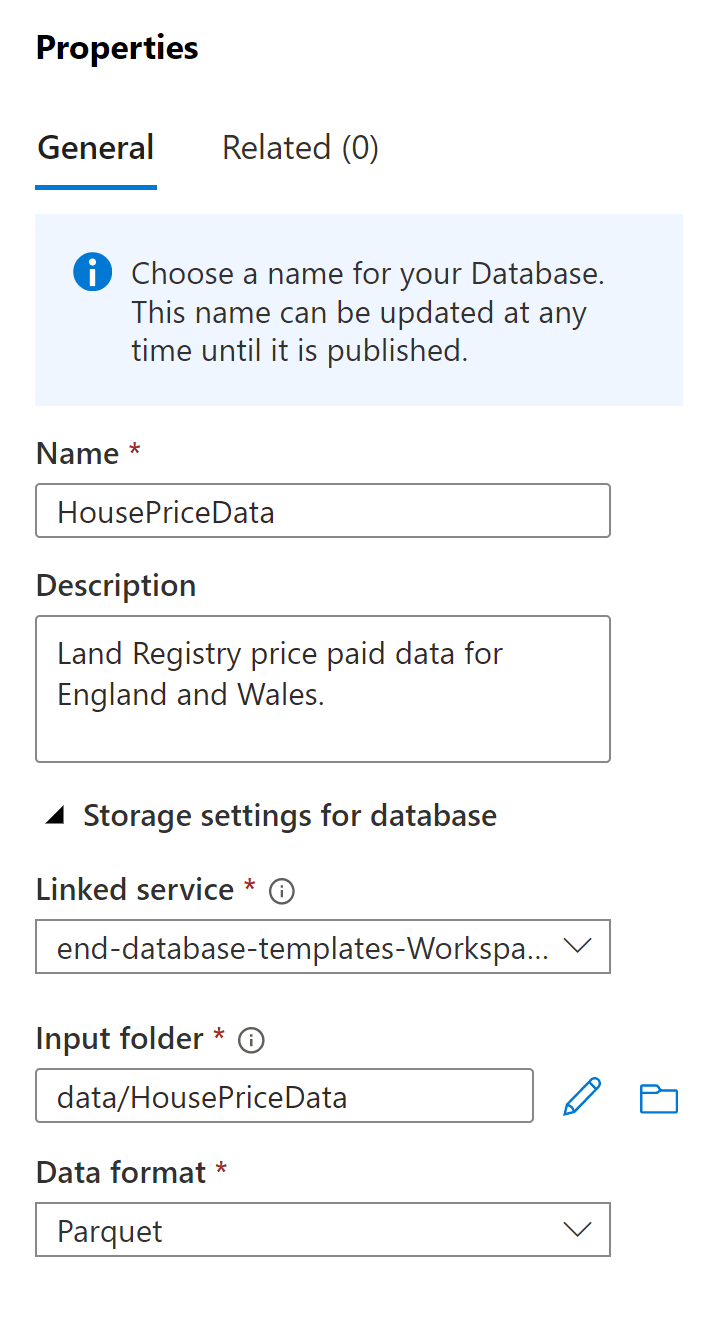
Note that there are currently only two data format options currently available: delimited (CSV) and parquet. It would be good to see delta added as an option!
Step 2 - add table definition
With the database created, you are now able to use the new database templates features to add custom table definitions. To do this:
- Select the + Table menu
- Choose the Custom option
- Set the name and provide a description of the table as follows:
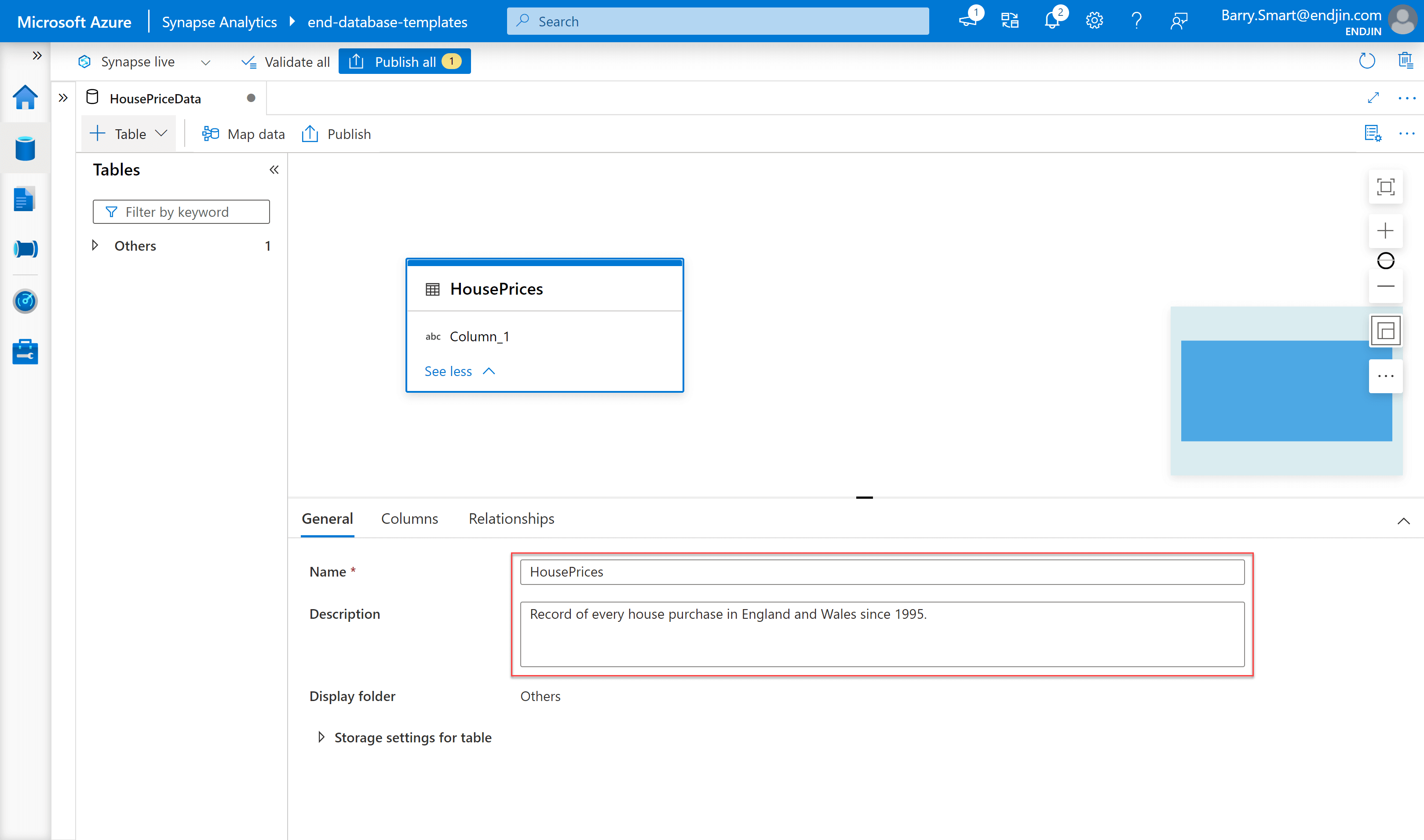
Step 3 - add columns definitions to table
With the table created, you can now select the Columns tab and start to add columns.
For each column, you define the following:
- Name - you are limited to upper and lower case letters and underscores. It would be preferable to use spaces in column names to reflect business terminology, but this is most likely a limitation of the underlying technology being used.
- Keys - indicates whether the field is a primary key (this locks the nullable option as False)
- Description - provide useful context for the column including providing some examples
- Nullability - indicates whether the column can contain
NULLvalues or not - Data type - the data type for the column, there is an extensive list of available options
- Format / length (only relevant for string and date types) - is used to define the length of a string column or the format of date column
Using this approach results in the following design for the HousePrices table:
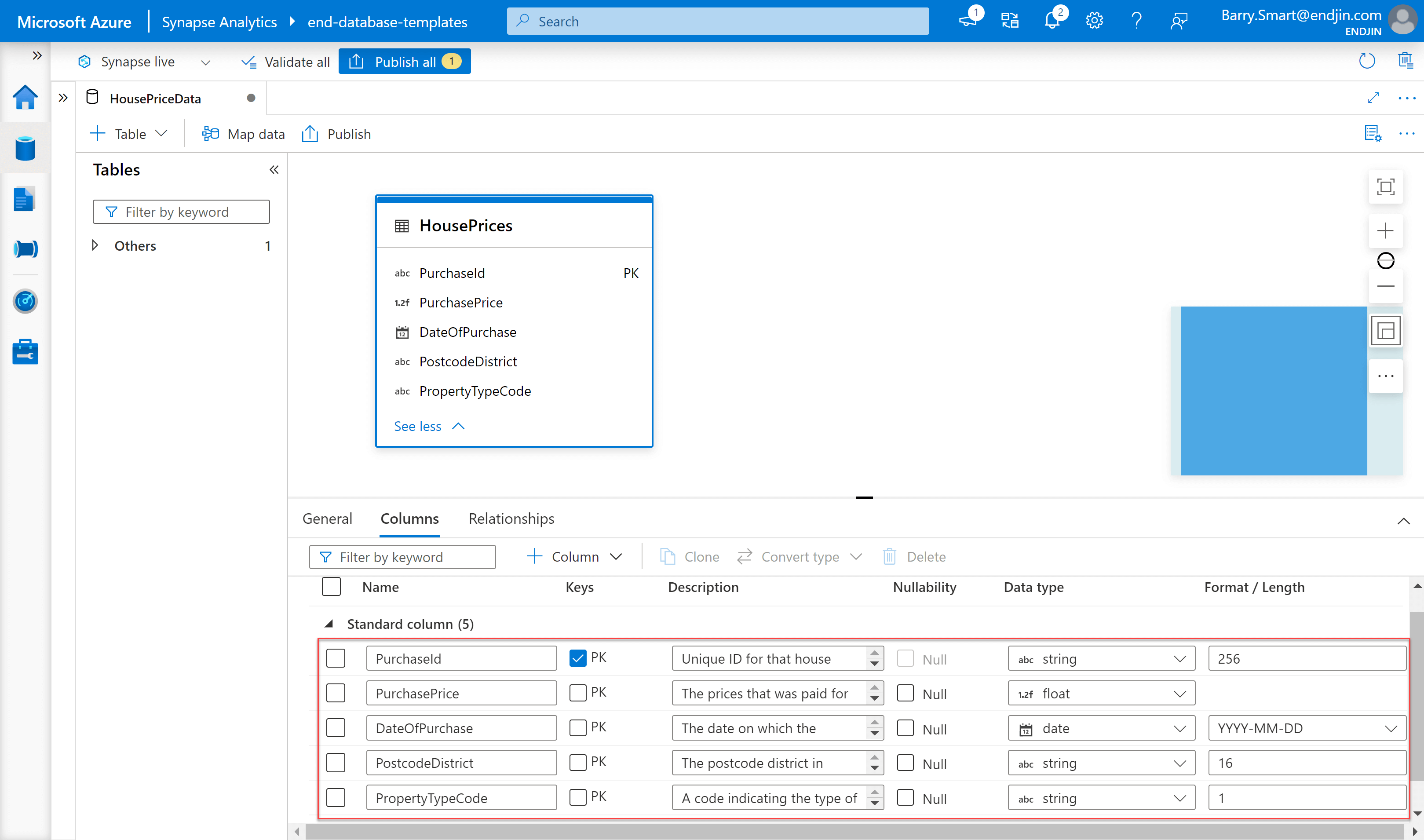
There is an annoying bug when using the user interface to create new columns. It seems to be triggered when you type fast, and it leads to the focus being dropped from the column name field so that further key strokes don't get captured. Hopefully Microsoft will address this soon!
Step 4 - create relationships
Repeat steps 2 and 3 above to create further tables as required.
Once you have more than one table in your database design, you can start to add relationships as follows:
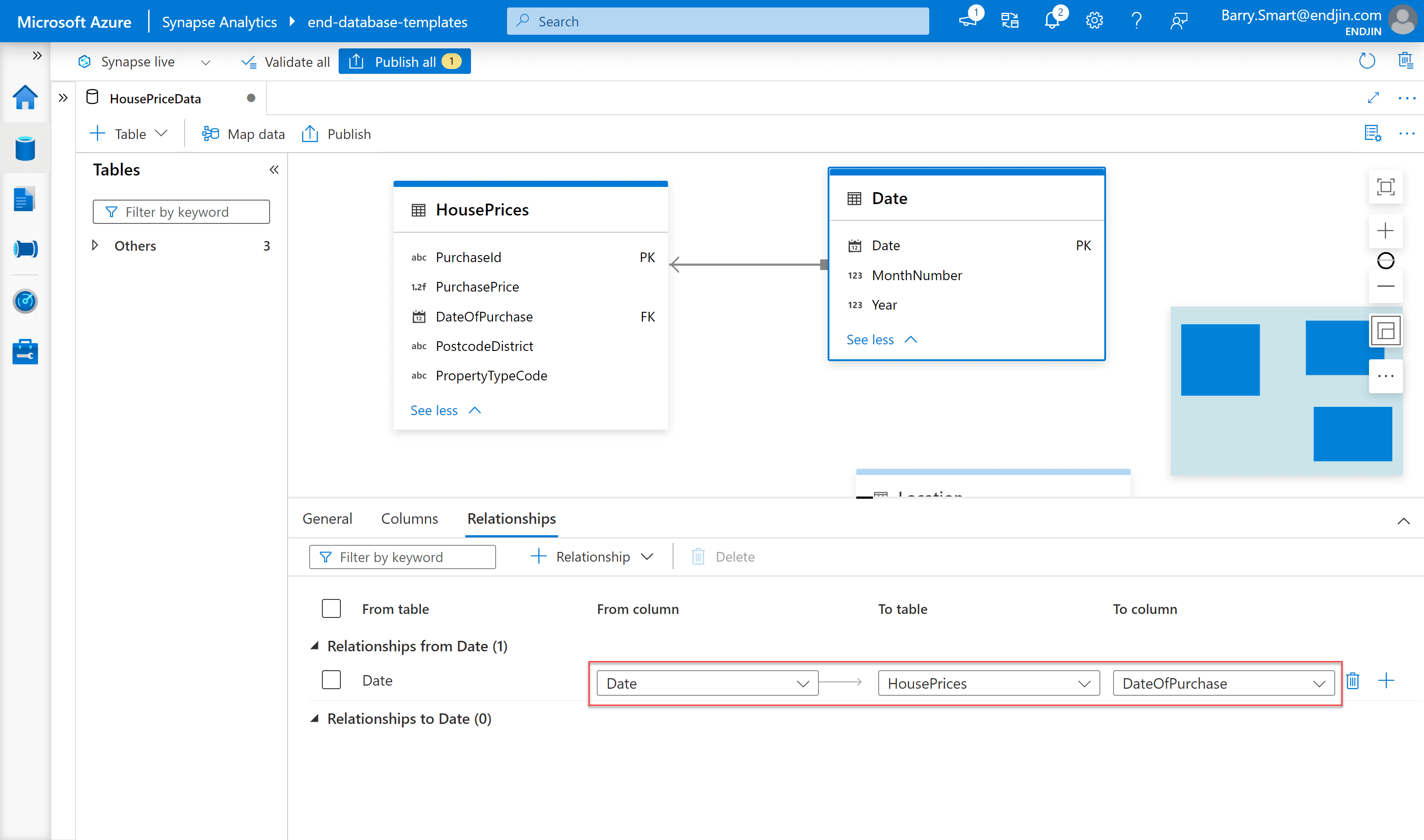
The terminology is based on "from" and "to". The best way to think of this is as the "from" side being the table with the primary key (the dimension table in this example) and the "to" side being the table with the foreign key (the fact table in this example). These appear to be limited to just "1 to many" relationships, you can't specify other types of relationship such as "1 to 1" or "many to many".
Once you have added all the tables, columns and relationships, you can observe the final model in Synapse:
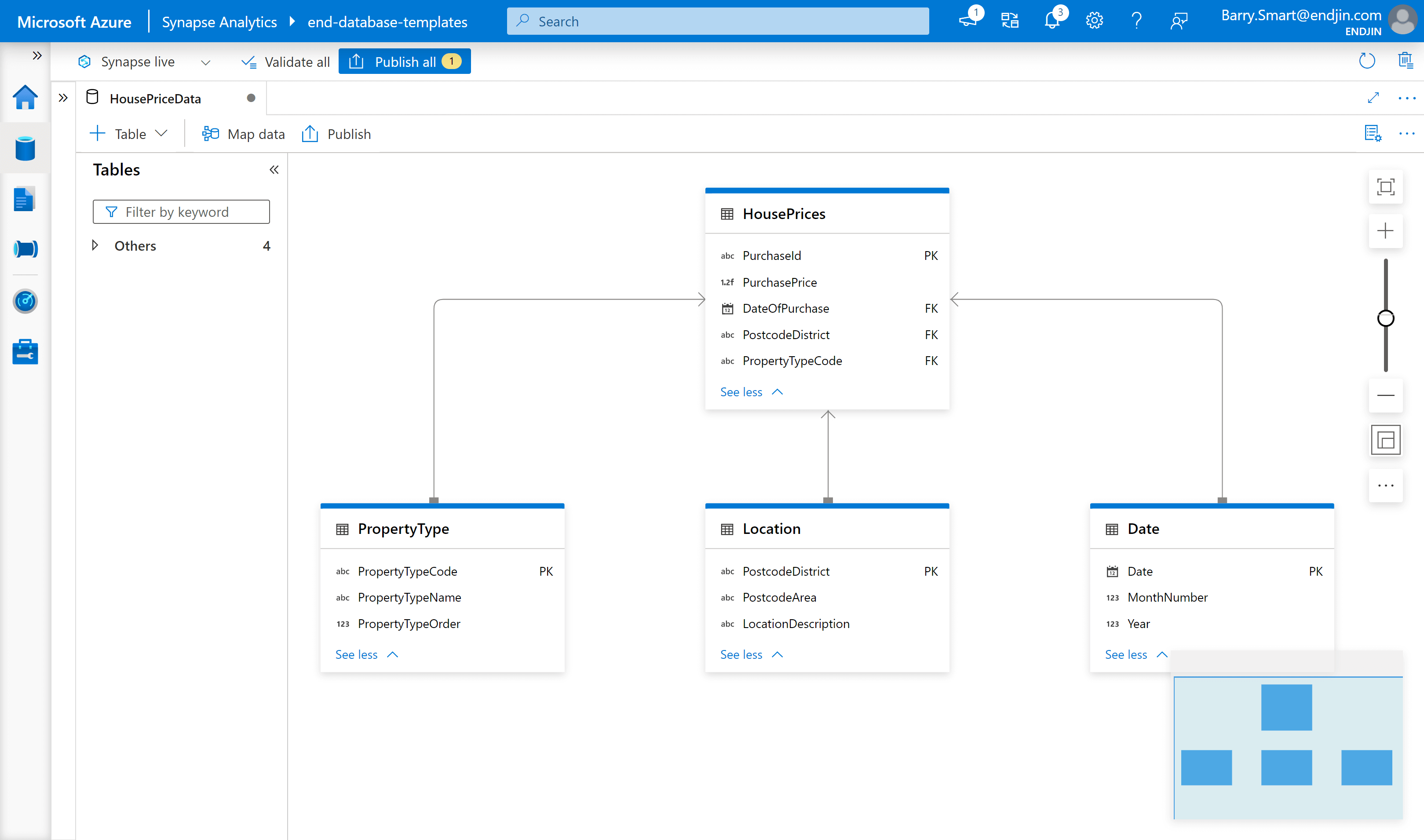
Step 5 - check artefacts in source control
Another major feature of working in Synapse is that all of the artefacts, whether they be notebooks, SQL scripts or pipelines can be managed as code using Git.
Database templates are no different. By syncing to a Git repository we can see clearly that the Lake Database configuration is stored in JSON format in a standard location ./database/<name of lake database> where two sub folders relationship and tables are used to capture the Database Template definition:
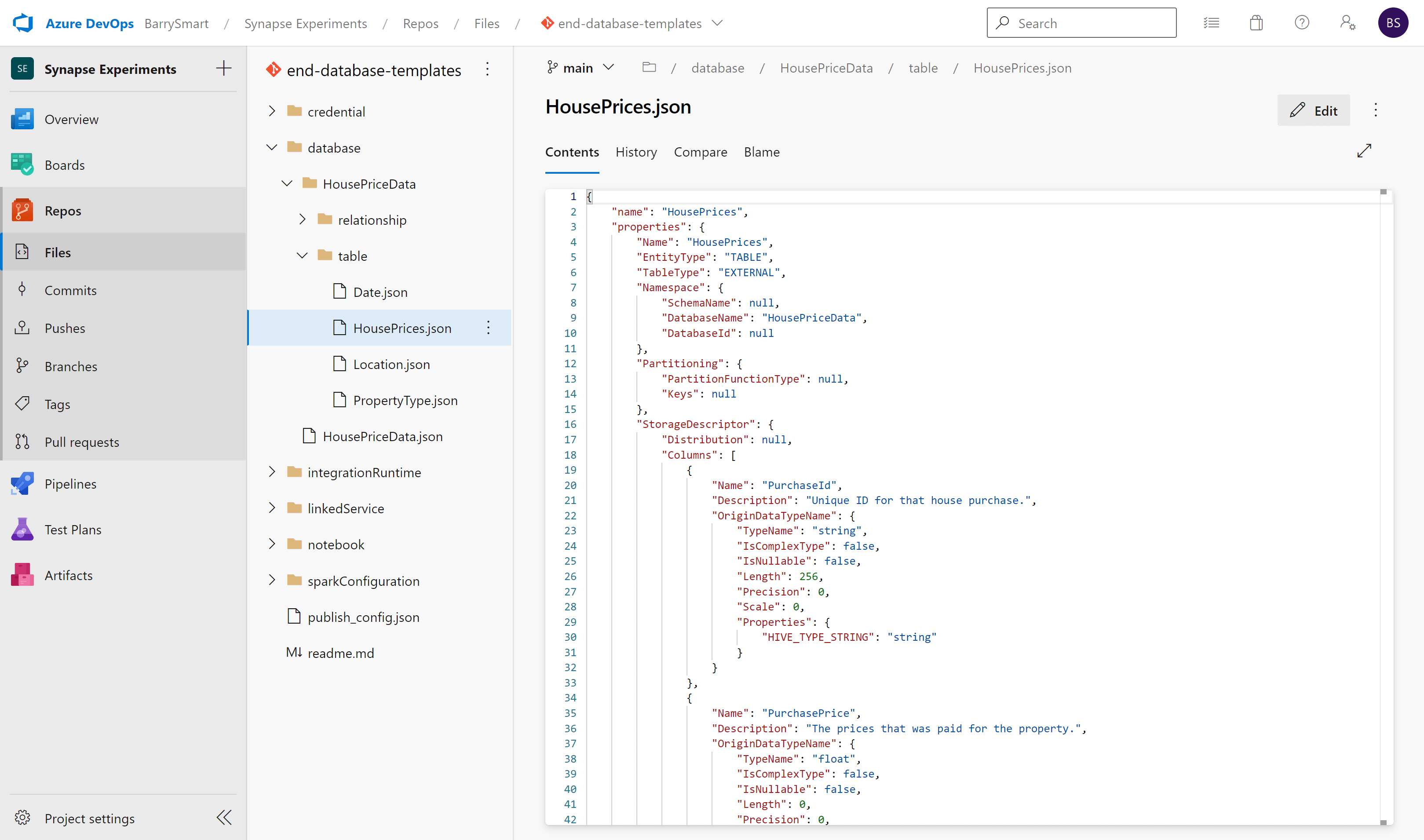
The JSON files are in a proprietary format, but they are simple to open, read and edit as required.
This provides the opportunity to take advantage of features in Git such as branches and pull requests to manage the lifecycle of the database templates along side all of the other upstream and downstream artefacts that have a dependency. This alone is a significant step forward as it allows the design of the target semantic model to be managed along with the Synapse pipelines, SQL scripts, Spark notebooks, data APIs and Power BI reports to which is is related. This enables the design to be propagated as first class citizen in DevOps pipelines through development, test, acceptance and into production (the DTAP lifecycle).
Method 2 - Create database template from industry templates
From within the database templates user interface choose the + Table menu and from that select From template:
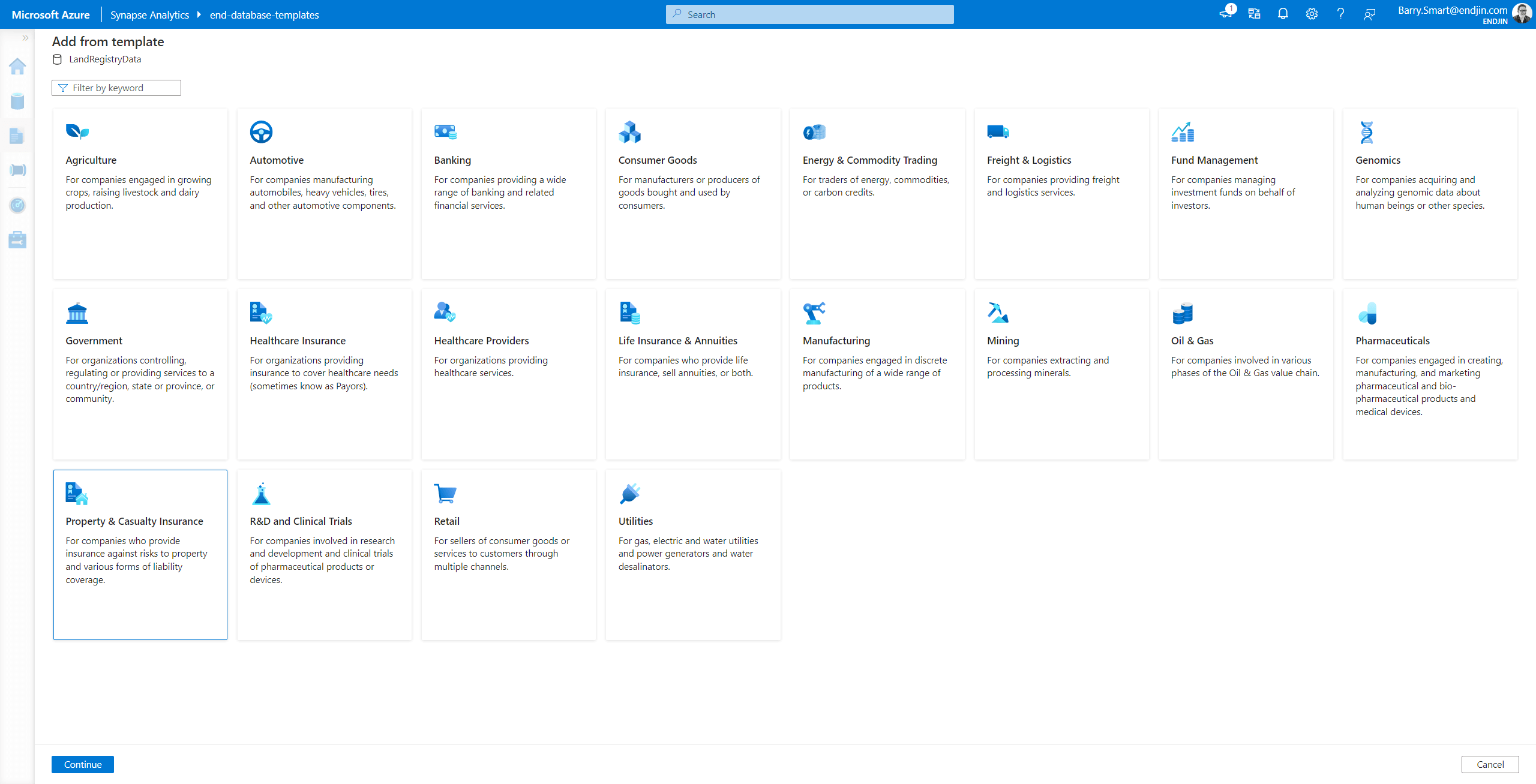
These industry models have been prepared based on the experience gained over many projects across a number of common industry verticals. They are comprehensive and abstract in nature. For example, the Property and Casualty Insurance model seems to be the closest fit to the specific scenario we are working with as it includes tables designed to hold property data. This industry model contains over 3,000 tables. Looking at the Property table, we can see that it has been designed to provide a high degree of flexibility so that it can be used to model many different types of property:
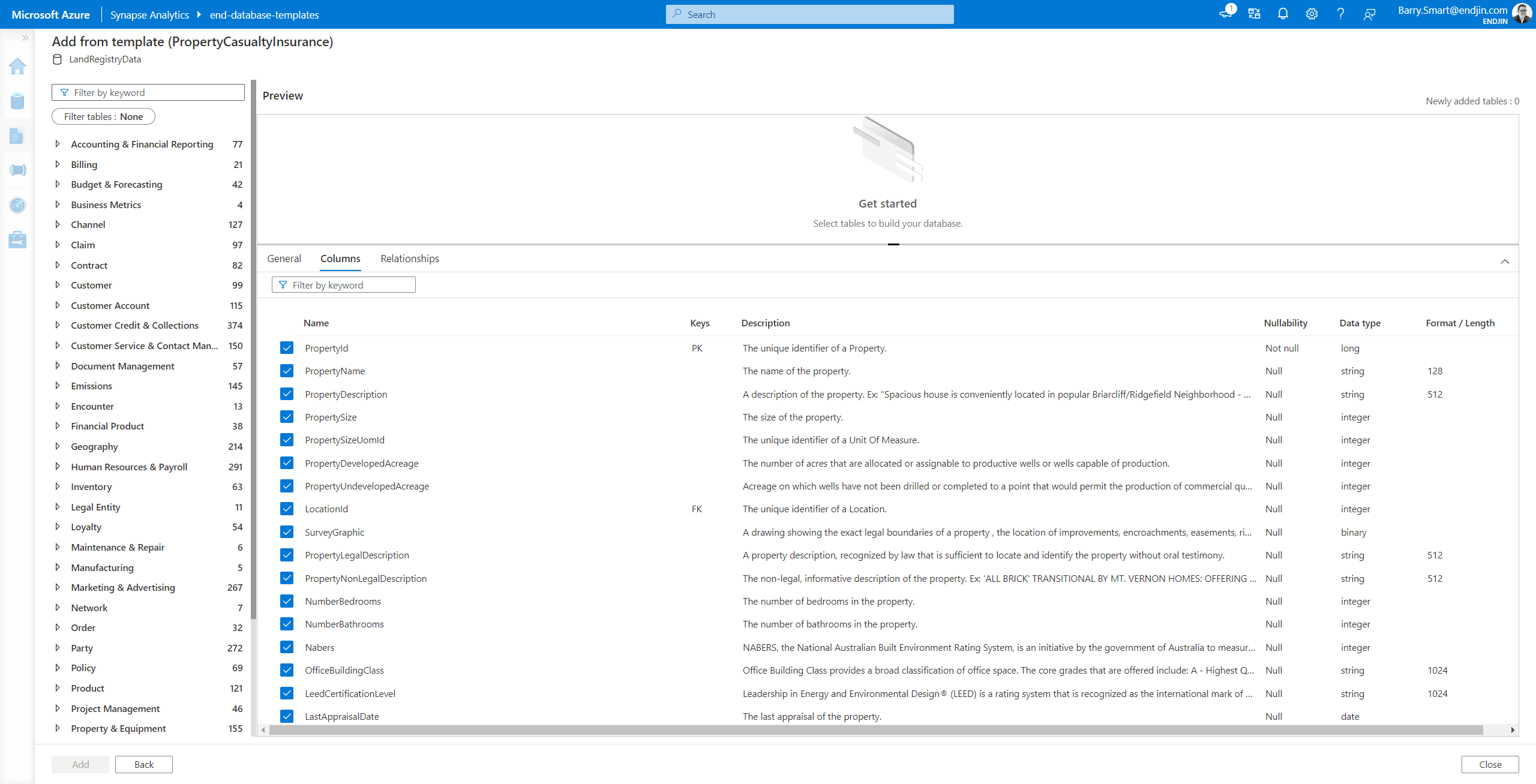
In this specific example, these templates feel heavy weight. We don't want to get drawn into figuring out how we can adapt it to support this specific problem. We are focusing on a specific actionable insight and want to deliver the semantic model that will support it. So in this scenario we don't proceed further with the template based approach.
As explained in the first blog in this series, our consultants prefer to think of these industry templates as something that organisations can "grow into" once they have built a critical mass of actionable insights over their data and have a better understanding of the strategic challenges they face around topics such as master data and governance.
See Microsoft's documentation How-to: Create a lake database from database templates for more information about these templates.
Method 3 - Create custom database template from files in the data lake
This approach reverse engineers the database template from files that already exist in the data lake. This is not a solution that meets the scenario we are considering. We are designing "right to left" here, defining a semantic model that is required to support a business goal driven actionable insight.
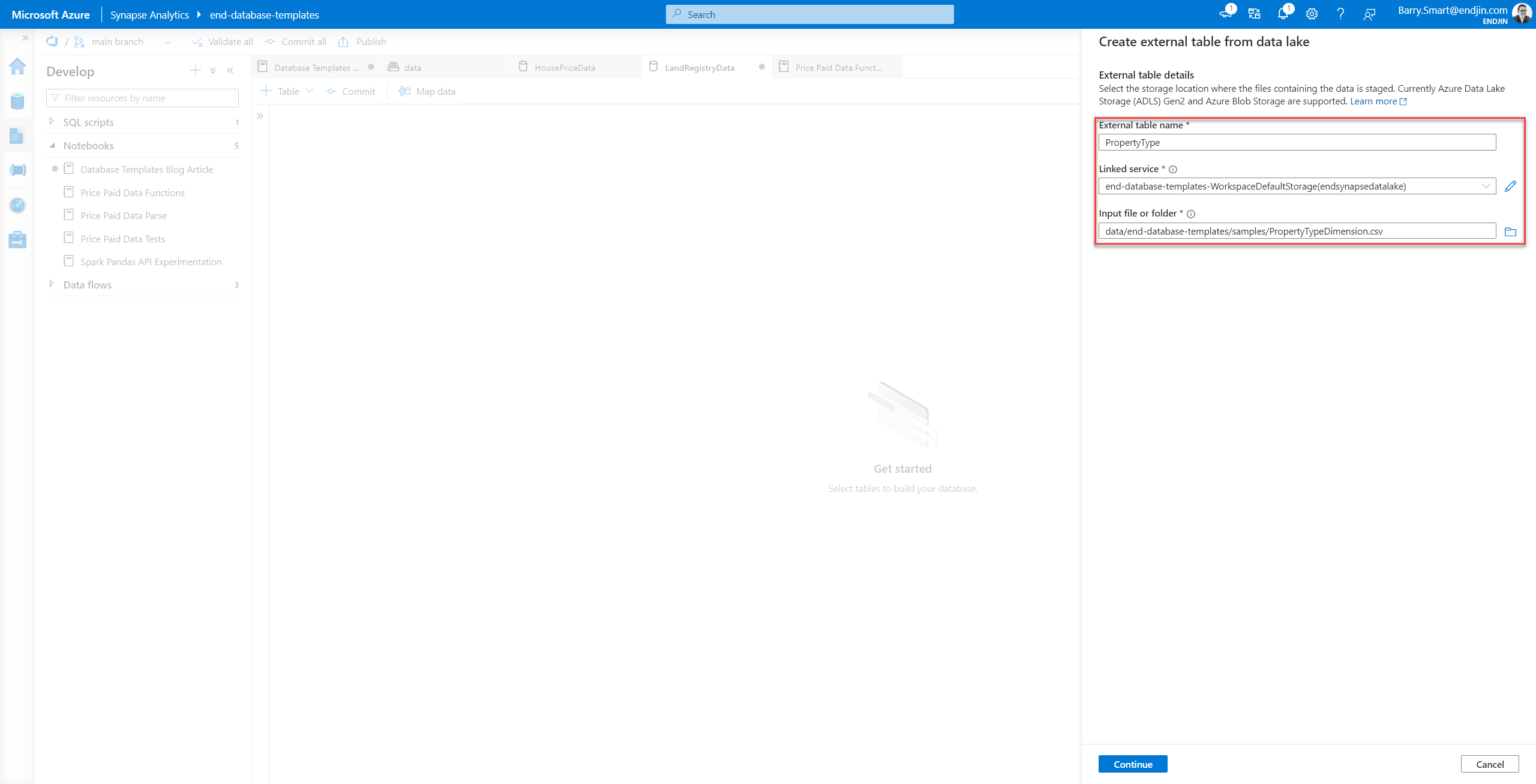
From within the database templates user interface choose the + Table menu and from that select From data lake.
This allows you to navigate via a linked service to data files that already exist in the lake. The first step is to locate the file (or folder) that you want Synapse to scan to detect the schema:
Once the file has been scanned, you can alter the file parameters and visualise the data:
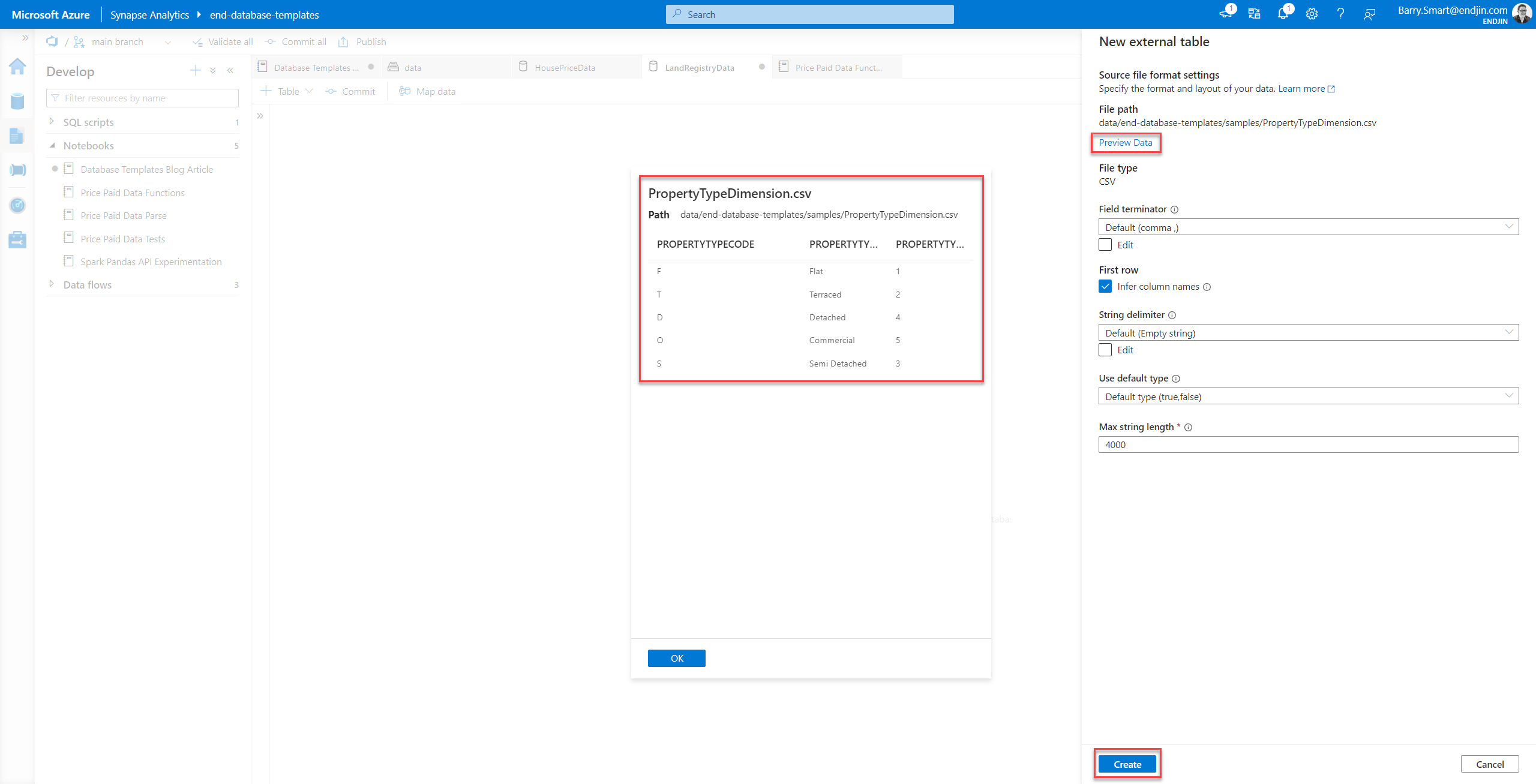
Once you are happy with the results, you can select Create and the table will be added to the database template:
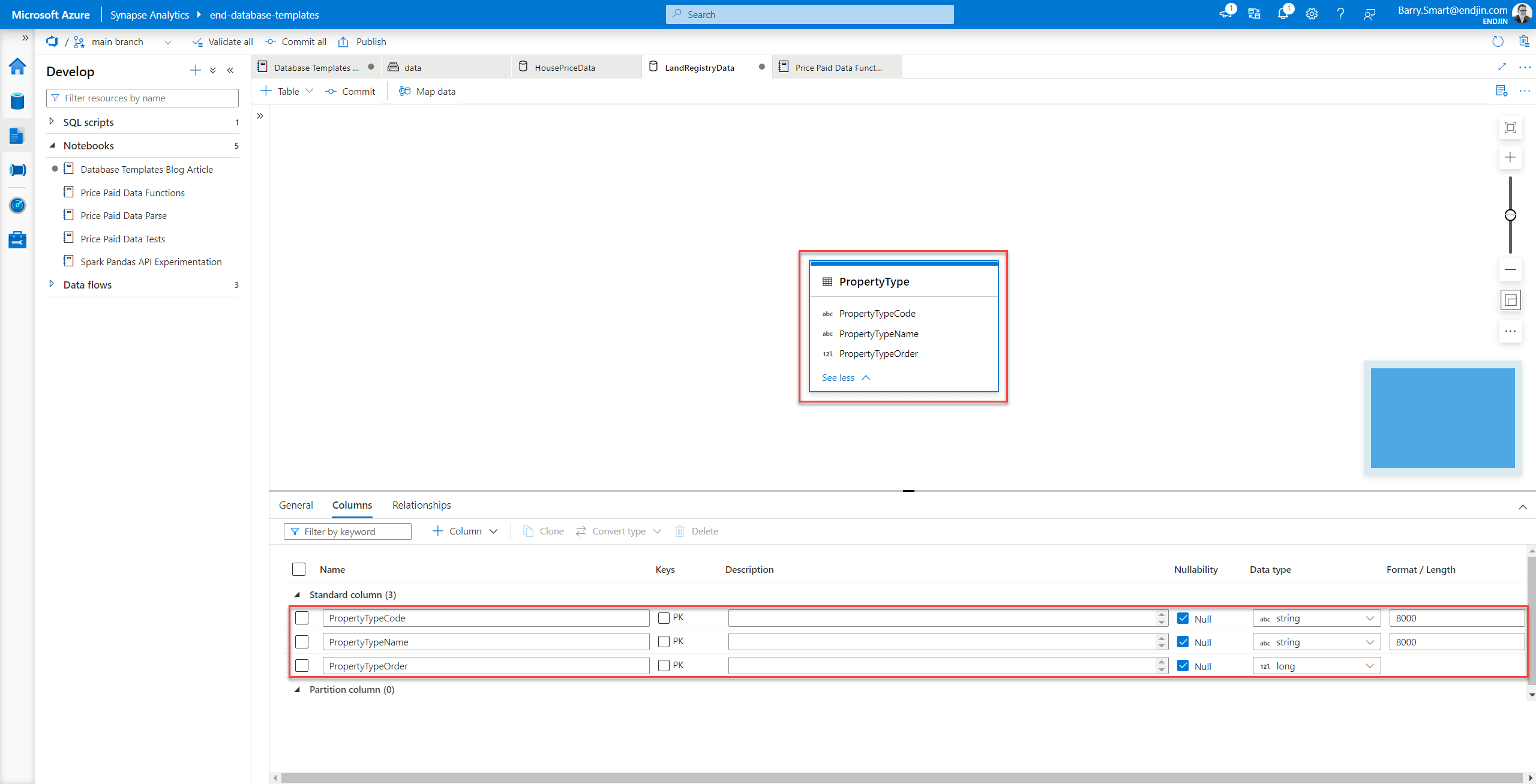
Note - by default, this table is backed by the data lake file or folder that you used to detect the schema. You can leave this configuration, in which case this remains an external table.
However you can also modify the location as follows:
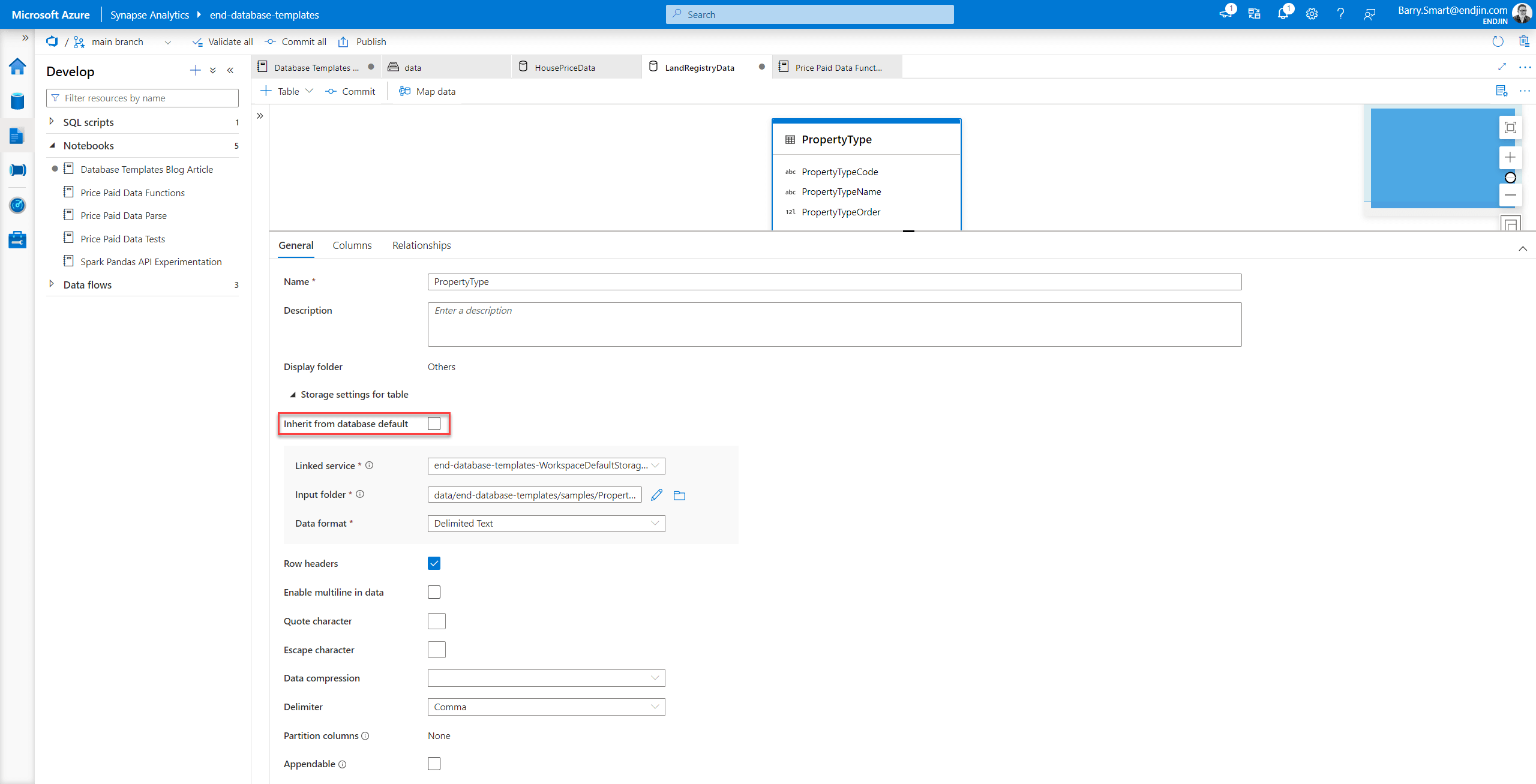
If you choose the Inherit from database default this will create an empty database schema back in the lake database, in the location and using the storage options you chose when you created the lake database.
This is a neat trick for creating an new empty database template from sample files that you may have created as prototypes. This creates a useful shortcut getting the key information about new database template tables into Synapse Analytics.
Method 4- Create custom database template using Pyspark
You can create a Database Template from a Synapse notebook using the saveAsTable method on a dataframe as follows:
# Create simple dataframe with 3 columns and 5 rows of data
property_types = spark.createDataFrame(
[
('F', 'Flat', 1),
('T', 'Terraced', 2),
('D', 'Detached', 4),
('O', 'Commercial', 5),
('S', 'Semi Detached', 3),
],
["PropertyTypeCode", "PropertyTypeName", "PropertyTypeOrder"]
)
# Write dataframe to lake as a table
property_types.write.saveAsTable("HousePriceData.PropertyTypeFromPyspark", mode="overwrite")
# Now read the results back from the table
spark.read.table("HousePriceData.PropertyTypeFromPyspark").show()

This results in the following output:
+----------------+----------------+-----------------+
|PropertyTypeCode|PropertyTypeName|PropertyTypeOrder|
+----------------+----------------+-----------------+
| S| Semi Detached| 3|
| O| Commercial| 5|
| D| Detached| 4|
| T| Terraced| 2|
| F| Flat| 1|
+----------------+----------------+-----------------+
You can also observe the outcome of the Pyspark commands above by inspecting the data lake - the data we wrote to the table is created in the lake in the location we would anticipate:
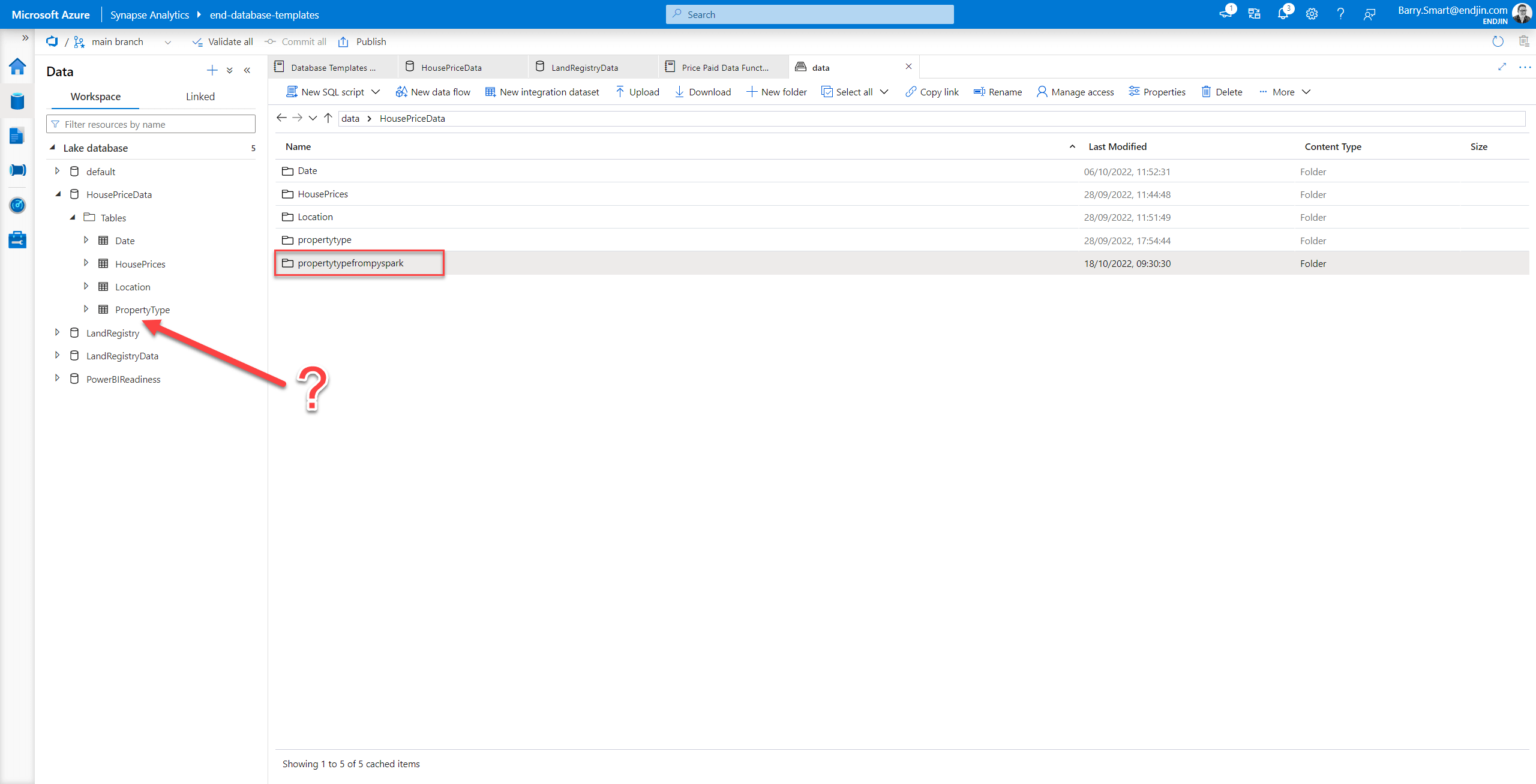
However, as indicated by the arrow above, the new table does not appear in the Synapse user interface.
It would be good to resolve this, because it would be really useful to be able to create tables in lake databases created by the new database templates functionality in Synapse.
Method 5 - create Database Templates using Synapse REST API
The final method we investigated for creation of Database Templates, was the Azure Analytics REST API. We use this API extensively at the moment to overlay DevSecOps processes over Azure Analytics. The REST API has a powerful set of endpoints to manage all of the Azure Synapse artefacts such as notebooks, SQL scripts and pipelines. Unfortunately, at the time of writing this blog, no end point was available for Database Templates. So we were unable to explore this further.
Lessons learned
By exploring these different methods of creating a semantic model using Synapse Analytics Database Templates, We have learned a few important lessons that we will describe in more detail below, but in summary these are:
- Names of tables and columns don't allow spaces
- Source control uses bespoke JSON schema
- Pyspark tables do not appear in Synapse
- Delta tables are not yet supported
- Frustrating glitches in Database Templates UI
- No Database Templates end point in REST API
Names of tables and columns don't allow spaces
One limitation of database templates is that the names of tables and columns CANNOT contain spaces. This is likely due to the limitations of the underlying parquet format used to store the data.
This means that you may need to add an additional layer of abstraction downstream in tools such as Power BI to achieve the true "semantic model" that end users are seeking. For example renaming the "PropertyTypeCode" column into "Property Type Code" so it is more easily consumed in reports generated from the data.
We recommend that you adopt a clear convention for table and column names. In this blog we used Pascal Case as the standard, but it may be more appropriate to use underscores to separate words as these can be more easily parsed downstream into spaces.
Source control uses bespoke JSON schema
The database templates are checked into the source control in JSON format. This is a adopts a proprietary syntax rather than a more widely adopted schema definition language.
The database template definition JSON also contains other meta data which means that you have to navigate a lot of ancillary information in the source file to get to the core definition of the database schema.
This also inhibits the ability to plug in other 3rd party tools and packages over the database template.
Pyspark tables do not appear in Synapse
We discovered that it is possible to create a new table in a lake database that has been created by the new Database Templates feature using the .write.saveAsTable() Pyspark method. However this is table does not become visible in the Synapse Database Templates interface.
Note: if we use the same method to create a table in the Default lake database, it DOES appear in Synapse. This seems an odd discrepancy in behaviour.
If it is technically feasible, it would be good to resolve this. It would be a useful feature to be able to create new tables programmatically using Pyspark and for them to appear in the new Database Templates UI in Synapse.
Delta tables are not yet supported
Currently, tables created using Database Templates can only be created as delimited (CSV) or parquet format. We hope that Delta format is supported in the near future.
Frustrating glitches in UI
When creating new rows in custom tables using the Database Templates UI, the field used to specify the name of the column has a "glitch" which means it looses focus when you are typing in the column name. This seems to be associated with client side logic that is validating the column name as you type.
This is a frustrating glitch when you are trying to set up a new table with lots of columns, because you are constantly having to stop and click the mouse to put focus back in the field.
Hopefully Microsoft that can fix this issue quickly.
No Database Templates end point in REST API
Unlike other artefacts such as notebooks, SQL scripts and pipelines, there is no end point available in the Synapse REST API to manage Database Templates.
This is a significant omission. This API is a powerful feature of Synapse as it gives users the ability to build their own operational processes. This means that Database Templates cannot share the same DevSecOps lifecycle as other artefacts in Synapse.
Conclusions
We've demonstrated that Database Templates have all of the features you need to use Synapse Analytics to design new semantic models. In doing so we have highlighted some of the benefits of this approach:
- Integrated tooling
- Collaboration
- Schema enforcement
- Integration into DevOps (or DataOps)
This is a big step forward for organisations seeking to streamline their processes for creating and managing modern data pipelines using Synapse Analytics.
In the next blog in this series we will move into the next phase of the development lifecycle - exploring the methods available to us to populate this semantic model with data.
See also Microsoft's documentation about database templates: