Computer Networking Essentials for Developers: the Web - Part 1


We're using computer networks and the Internet all the time. Here at endjin, much of our work is done in Azure – a cloud platform that we communicate with over the internet and have some degree of control over the internal networking that our cloud-based applications depend on. The vast majority of the workings of networks are abstracted away from us, however considering we use them so much and are so dependent on them, especially as software engineers, it seems reasonable that we should have at least some understanding of how it all works.
The aim of this series of posts is to give an introduction to computer networks, the Internet and the Web, at a scope that is relevant to the software developer. Based on my brief foray into networking, it's obvious that it is a massive and complex subject, with many layers of details – many of which I will not cover (and do not understand) in order to keep things relevant.
In my previous post I described the infrastructure that enables packets of information to be sent over the Internet.
In this post I'm going to talk about the major application that utilises all of that infrastructure and is often considered (falsely) synonymous with the Internet – the World Wide Web (WWW).

The WWW, or the Web for short, is an application that sits on top of the Internet infrastructure described in the previous post. It is the actual thing that people are usually referring to when discussing the Internet, in fact the two terms are often used interchangeably, but they're not the same thing. This application layer of the whole Internet stack is probably the most relevant to software developers; in this post I'll cover the essential details.
Clients and Servers
The words "clients" and "servers" are ones you have likely come across. Network applications are based on the client-server model; this is a simple but key concept to understand when discussing communication over networks.
A network application consists of a server and one or more clients. A server is called such as it provides some service to its clients. The server provides the service by managing a resource, which it manipulates on behalf of its clients. For example, a Web server might manage files on disk storage that it fetches and gives to the client.
At a high conceptual level, I think it's fine to think of clients and servers as individual computers. However that mental model only gets you so far since it's in fact possible to have multiple clients on a single machine, multiple servers on a single machine, and multiple clients and servers on one machine. A single client or server is actually a program running in the context of a single process on a machine, hence the aforementioned possibilities.
Requests and responses
Clients and servers communicate with requests and responses: to get a service from a server, a client sends a request to the server; the server processes the request and sends a response back to the client; the client processes the response. This sequence of steps is called a transaction.

The Web
What is the web?
As I mentioned, the Web is an application that sits on top of the Internet. I.e. it uses the Internet's infrastructure which enables packets of information to be sent between Internet hosts. The Internet provides the facility for sending content, which the web uses to send content types that it cares about.
Clients and servers on the web
The Web is a network application and therefore follows the client-server model, which I gave a general description of. Servers on the web are called web servers, clients are called web clients. Typically a user accesses the Web through a browser, in which case the browser is the web client.
So, a web transaction goes as follows: A browser (the client) requests some content – perhaps a web page – from a web server; the server processes the request – perhaps it fetches the web page file from the disk drive that it manages – and sends a response back to the browser; the browser receives the response and processes it, which, in the case of a browser, means displaying the content on screen.
The Web page
The Web page is a type of Web content and is foundational to the Web. The key feature of web pages, and the thing that makes them foundational, is the hyperlink, which is a pointer to another resource (e.g. another Web page) on another Internet host.
We're all familiar with hyperlinks, we know that when we click one in a browser we get a new Web page on screen – this is as a result of the browser requesting the resource that the hyperlink represents from the server on whatever Internet host it lives on. The result is an interconnection between web pages (and other web content) living on Internet hosts all over the world, forming a web of resources, hence the name World Wide Web.
The most basic web page is a text file containing hyperlinks; the combination of plain text and hyperlinks has its own name – hypertext. Therefore web pages are a type of hypertext document.
The URL
Given that the resource that the URL identifies lives on some Internet host, we need the address of that Internet host in the URL, i.e. the Internet host's IP address or domain name needs to be in the URL. We also need the port number that the server is listening on so that the packet containing the request gets to the right place on the host. And finally, the file path of the resource on the server needs to be in the URL.

The figure above illustrates the structure of an example URL. This URL can be interpreted as saying: "I represent a file called index.html on Internet host www.google.com, that is managed by a Web Server listening on port 80".
In this example the port number is not really needed; the scheme, HTTP, at the start of the URL indicates that the resource is associated with a web service, which is a well-known service; each well-known service corresponds to a well-known port, which is 80 in the case of the Web. In short, the presence of ‘HTTP' at the beginning of the URL indicates that the resource can be requested from a server listening on port 80.
HTML
As I mentioned, a web page is essentially a text file containing hyperlinks. So, we need a way of specifying what's a hyperlink in the text file - what's referred to as marking-up the plain text with hyperlink elements. For this we have the Hypertext Markup Language (HTML).
HTML marks-up the text with instructions – known as tags – that instruct the browser to do certain things, like create a hyperlink, make text bold, make text a title, and more.
HTML example
<h1> Hello all! </h1>
My name is Liam and I'm an apprentice engineer at <a href = "https://endjin.com/"> endjin.</a>

The <h1></h1> tag instructs the browser to display the contained text as a header. The <a></a> tag – known as the anchor tag – instructs the browser to display and highlight the text endjin, and make it a hyperlink pointing to the endjin website home page, represented by the URL https://endjin.com/.
HTTP
The Hypertext Transfer Protocol (HTTP) is the language that web servers and clients use to communicate with one another. In other words, since we've established that servers and clients use requests and responses, HTTP defines the format of requests and responses on the Web. And, as the name suggests, HTTP is used for sending HTML files.
HTTP requests and responses are simply lines of text sent in TCP packets over the Internet.
HTTP Requests
A HTTP request has the following format: request line, followed by optional request header lines, followed by an empty line (indicating the end of the request headers), followed by an optional request body (which can be over multiple lines).

Request line
The request line is the heart of the request, the figure below illustrates their structure. The request method conveys what the client is requesting of the server; HTTP has a number of request methods (sometimes referred to as verbs), such as GET, POST, PUT; each is interpreted differently by the server and are therefore used for achieving different things. The above example uses the GET method, which is the most common of all and basically does as it reads – tells the server to return the resource represented by the Uniform Resource Identifier (URI).

The URI is the section of the corresponding URL after the domain name, it identifies the resource upon which the request is being made. Finally, the HTTP version is the version of HTTP that the request follows.
Request headers
Request headers allow the client to pass additional information about the request or the client to the server, they have the format header-name: header-value. A common example is the Accept header, which allows the client to tell the server the content type it is willing to accept. Request headers are also used extensively for passing information to the server related to authentication.
Request body
The request body is for sending data to the server. It's commonly used with the HTTP POST request to send the contents of the request body to the server. For example, when you're filling out a form on a website and hit save, internally this will typically be a POST request with your form inputs being in the body of the request. The request body in the example shown is empty since this is typically the case with GET requests.
HTTP responses
HTTP responses follow a similar format to requests: a response line, followed by optional response header lines, followed by an empty line, followed by optional request body lines.
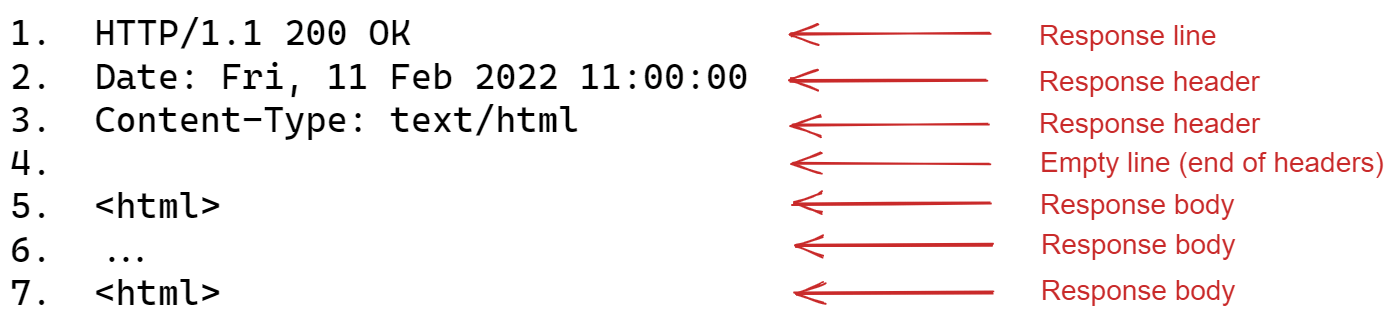
Response line
The response line conveys the nature of the response. As the figure below shows, it contains an HTTP version (indicating the version of HTTP the response follows), a status code and a corresponding status message.
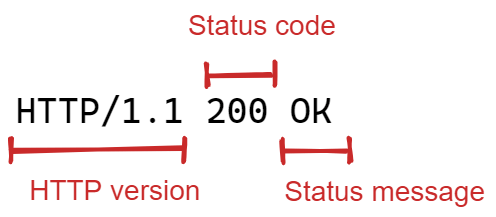
The status code, and corresponding message, informs the client of the general result of its request. They are three-digit integers beginning with either 1,2,3,4, or 5, and are grouped into categories according to the first digit. 1xx – informational response; 2xx – successful, e.g. 200 OK; 3xx – redirection (the client must take some additional action to complete the request); 4xx – client error (error and it's the client's fault), e.g. 404 Not Found – meaning the resource in the request could not be found; 5xx – server error (error and it's the server's fault), e.g. 500 Internal Server Error.
Response headers
The same idea as request headers – they allow for additional information to be conveyed, this time from the server to the client. A common response header is content-type, which indicates the content type of the response body. In the example above this has value text/html since the response body contains HTML.
Response body
Again, similar to the request body – contains the content sent from the server to the client. As in the example above, in the case where the client requests a web page, the HTML that makes up the web page will be sent in the body of the HTTP response (given that the request has been processed successfully).
Conclusion
This post started with a general description of the client-server model, to which the Web conforms. Next, I covered the core technologies that make up the Web. In short: the Web is an application that employs the Internet's capability of sending packets of information between Internet hosts for sending content types it is concerned with; the most important of these content types is the web page, which are programs written in HTML that mark-up plain text with instructions to be interpreted by a browser and used to display the web page; a client requests a web page (and any other web content) from a server, and the server subsequently responds, using the language of HTTP; and every piece of content that can be accessed over the Web is uniquely identified by a URL.
So, if you could somehow magic-up all of the technology discussed here and in part 1, you would have the ability to send/receive web pages and have them displayed in a browser; you would be able to click hyperlinks in web pages, which your browser would dutifully obey by fetching the web page represented by the URL in the hyperlink. But these web pages would be pretty basic – organised text containing hyperlinks. What about images, videos, colours, fancy styling, and dynamic web pages? Producing those requires some more stuff, such as CSS and JavaScript, and will be discussed in the next post.