Azure Synapse SQL Serverless: connect Data Lake and Power BI


As more and more organisations move towards a data-driven and cloud-first approach, they are faced with many decisions around where to store and how to surface their data. These decisions are based on a lot of factors, functional requirements, familiarity, performance and cost being just a few.
In undertaking this journey, the cost of storing a large amount of data in SQL-based Azure offerings can turn out to be prohibitive. And, in a lot of these cases, organisations will revert back to an on-premise data storage solution, which is then connected into a cloud-based mechanism for delivering insights. However, this solution brings its own challenges around operational complexity, maintenance, and maintainability.
Luckily, there is another option.
Azure Data Lake Store (Gen2)
Azure Data Lake is built on Azure Blob Storage, which is a part of the Azure Storage offering (along with Table, Queue, and File storage). It is an extremely cost-effective storage solution, where data can be stored in a file-system like hierarchy (unlike blob storage, where data is stored in totally flat structure).

Data Lake allows you to store a huge amount of data, for extremely little cost.
It also provides support for a huge amount of fine-grained permissions management. I won't go into this in detail, but if you want to know more about it then check out my blog post on building a secure data architecture on Azure Data Lake.
However, data stored and partitioned in this way is often thought to be more difficult to query than, say, a SQL server endpoint. This is where Azure Synapse comes in.
Azure Synapse
Azure Synapse is a comprehensive analytics solution. It provides the ability to load, manipulate, and analyse data. It comprises of a few different parts, which work together to form a coherent analytics platform.
Azure Synapse includes:
- Pipelines - for ochestrating data processing
- Data Flow - for carrying out data manipulation without writing any code
- Spark (Notebooks and Jobs) - for combining live code (using Python, Scala, .NET or Spark SQL), visualizations and text blocks
- SQL Serverless (SQL-on-demand) - for querying data using a SQL like syntax, without the need to deploy SQL infrastructure
- SQL Pools - for deploying a dedicated SQL DataWarehouse
- CosmosDB (via Synapse Link) - for working directly with data stored inside of Cosmos
Pipelines , data flows and notebooks are incredibly powerful tools for performing data manipulation and analysis. Alongside this, SQL pools and CosmosDB can be great if you need to stand up your own database. However, here I am going to focus on SQL serverless and how it can integrate with Data Lake to power downstream analytics, specifically... Power BI
Power BI
Power BI is Microsoft's business intelligence reporting tool which is used by millions to provide insight into data.
One of the most common ways that Power BI is used is to query data from a SQL Server endpoint.
The data that is retrieved from SQL can then be used to power visualisations which enable report consumers to get the insight that they need.
However, when we move out of the world of relational databases, and into one where data is split over multiple partitions or files, we need a new mechanism for serving these insights.
Now, Azure Synapse does actually support direct intragration with Power BI via a linked service. So, you might be asking, why not just use that? Why go via SQL Serverless at all?
At the time of writing, the Power BI integration can only connect to a single Power BI workspace. This might be all that you need, but if you read my last blog post on how to implement DevOps for Power BI, you'll see why being able to use multiple workspaces can be important!

Bringing it all together
So, consider a solution in which we are storing our data in cost-effective data lake storage. We will assume that we are storing this data in a parquet format (parquet is Apache's highly compressible, column-based, data format which can help reduct storage costs even further!).
We now need to be able to query the files in the data lake from our Power BI reports.
SQL Serverless allows you to query multiple files from Azure Data Lake using a SQL like syntax.
For example, say we had the following data stored in Azure Data Lake (here we are viewing the Data Lake contents from within Azure Synapse):
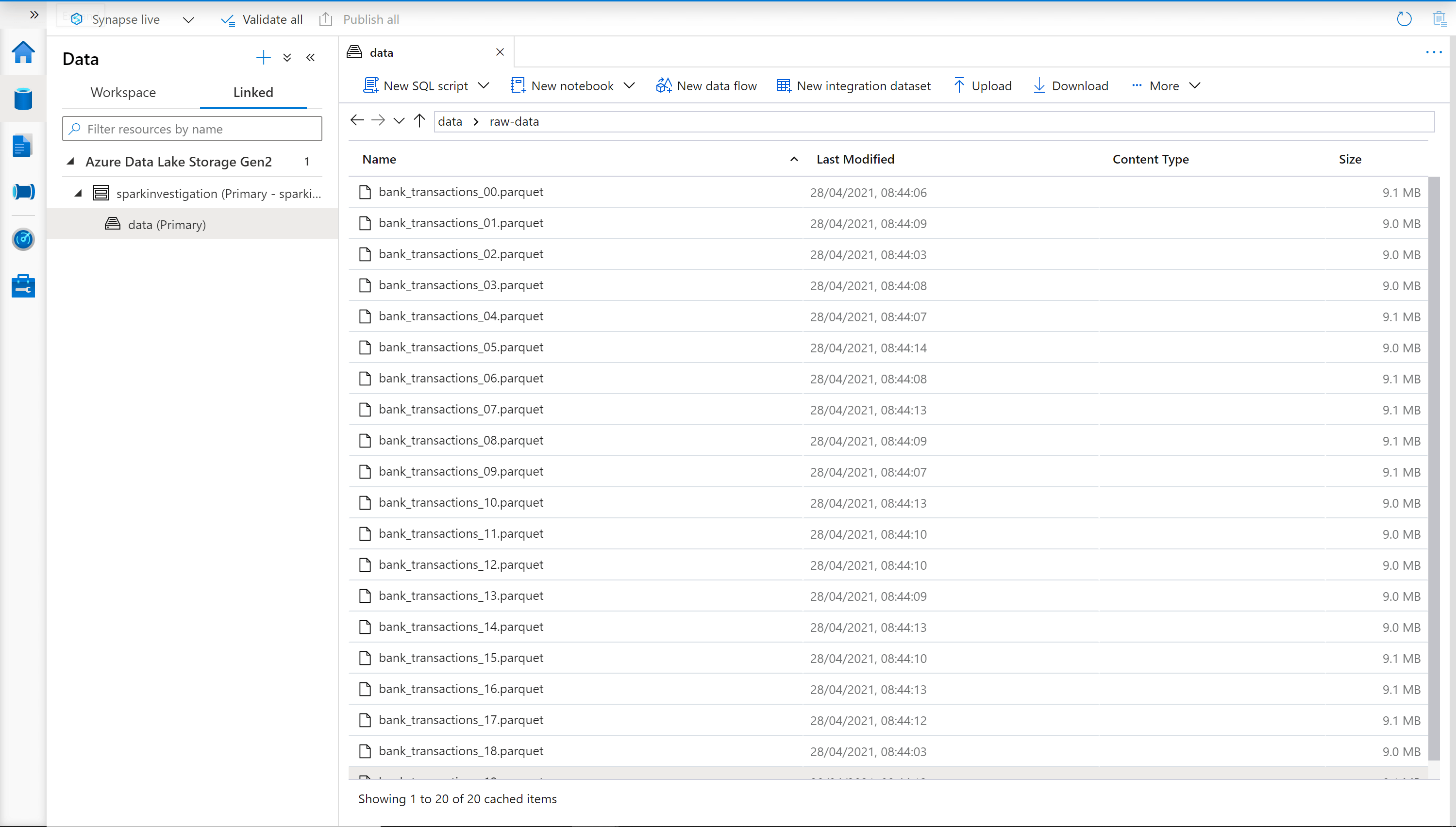
We can see that there are many parquet files within a single folder (this is often the case when parquet files are created using Spark a partitioning strategy will be applied by the cluster).
We can then create a new SQL script within the Synapse account, by viewing on one of the files within the data lake and creating a new script:
The script that is created will look like this:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://sparkinvestigation.dfs.core.windows.net/data/raw-data/bank_transactions_00.parquet',
FORMAT='PARQUET'
) AS [result]
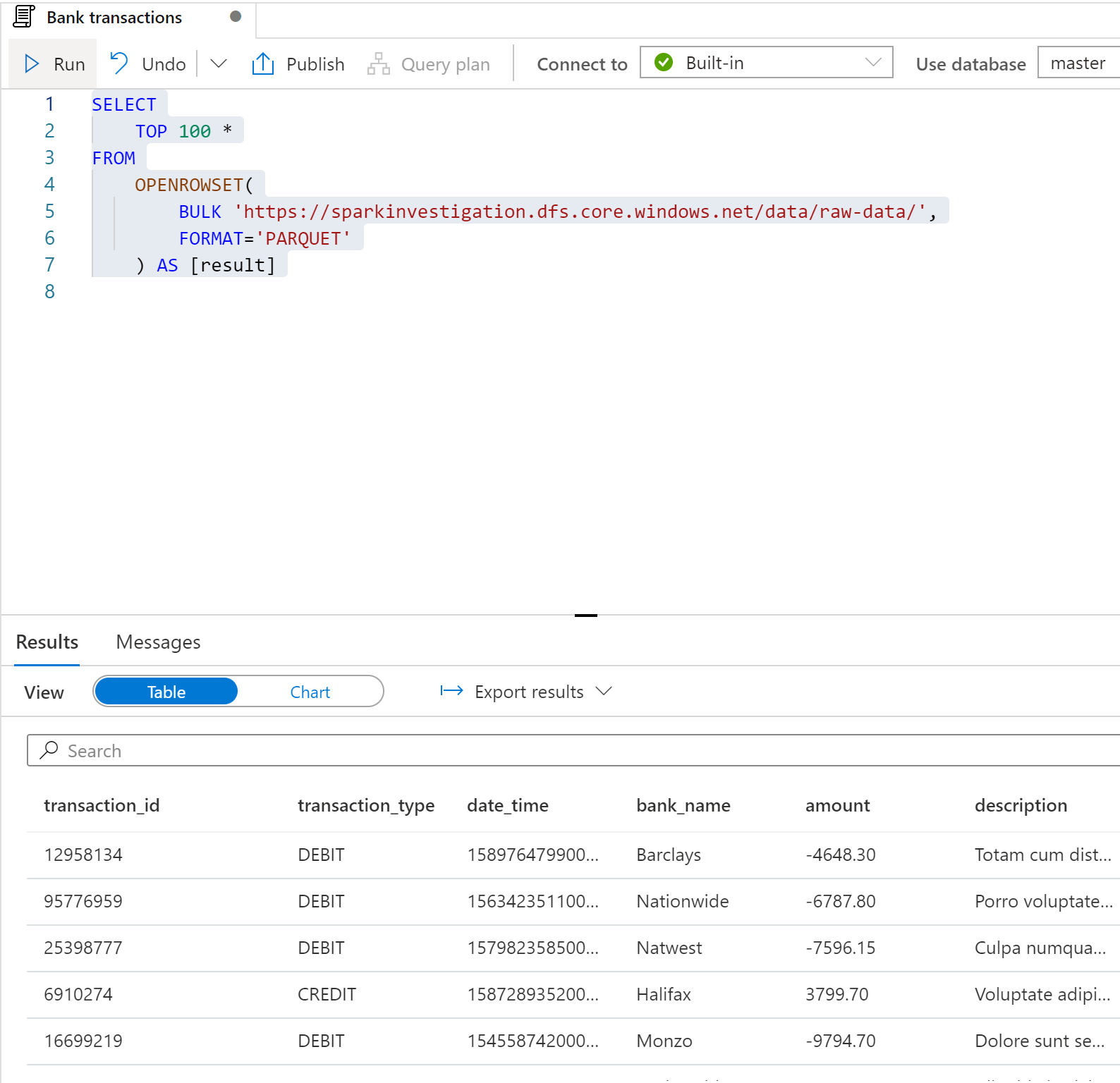
If we remove the file-specific part of the path:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://sparkinvestigation.dfs.core.windows.net/data/raw-data/',
FORMAT='PARQUET'
) AS [result]
And execute the query, we can then run the SQL query over the entire folder:
Now that we've established that we can query the data, we need to create a SQL Serverless view which we will then be able to query from Power BI.
First, we must create a SQL script for creating a new database within our Synapse account:
CREATE DATABASE "Reporting"
When we run this script, we will then be able to see the database:

Once we have created out database, we create a second SQL script, run within that database, which creates the view:
CREATE VIEW BankTransactions
AS SELECT
*
FROM
OPENROWSET(
BULK 'https://sparkinvestigation.dfs.core.windows.net/data/raw-data/',
FORMAT='PARQUET'
) AS [result]
We now have three SQL scripts within the Synapse workspace:

Once we have run the final script, we can see the view within the database:
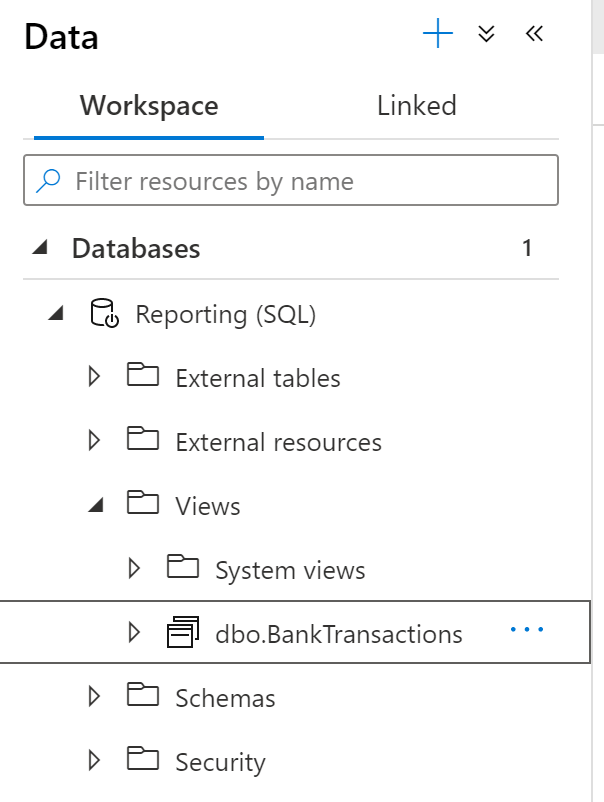
So, we now have a view within our database which we will be able to query from within Power BI!
So, if we now open Power BI desktop, and "Get Data" we are presented with a list of data sources. If we then select the Azure SQL Database option and enter {synapseWorkspaceName}-ondemand.sql.azuresynapse.net as the server to connect to, we will then be asked to authenticate. Here there are a few options, but the easiest is to log in using a Microsoft account.
Once this is done, we are able to connect to the server. Then, we should be able to view the databases which exist within the Synapse workspace:
And from there, we can view the data exposed via the SQL serverless view:

We can then load and transform that data, and it to produce visualisations within the report!

The solution
So overall we have three components:
- Azure Data Lake - for storing the data in parquet format
- Azure Synapse - for creating SQL serverless views over data stored in the data lake
- Power BI - for querying the SQL serverless views and creating visualisations over the data
Between these three components we are able to leverage cheap data storage, and produce insights over a large volume of data. There is also the option of extending the solution and performing further analytics using Synapse. But that's a subject for another post!



