Top Features of Notebooks in Microsoft Fabric


The notebook experience in Microsoft Fabric is similar to notebook experiences on other platforms - they provide an interactive and collaborative environment where you can combine code, output, and documentation for data exploration and processing. However, there are a number of key features that set Fabric notebooks apart. I'll walk through the top features of Fabric notebooks in this blog post.
Native Integration with Lakehouses
Fabric notebooks are natively integrated with your lakehouses in Fabric. You can mount a new or existing lakehouse directly into your Fabric notebook simply by using the 'Lakehouse Explorer' in the notebook interface. The Lakehouse Explorer automatically detects all of the tables and files stored within your lakehouse which you can then browse and load directly into your notebook. This direct integration with your lakehouses eliminates any need for manual paths / set-up, making it simple and intuitive to explore your lakehouse data from your Fabric notebook.
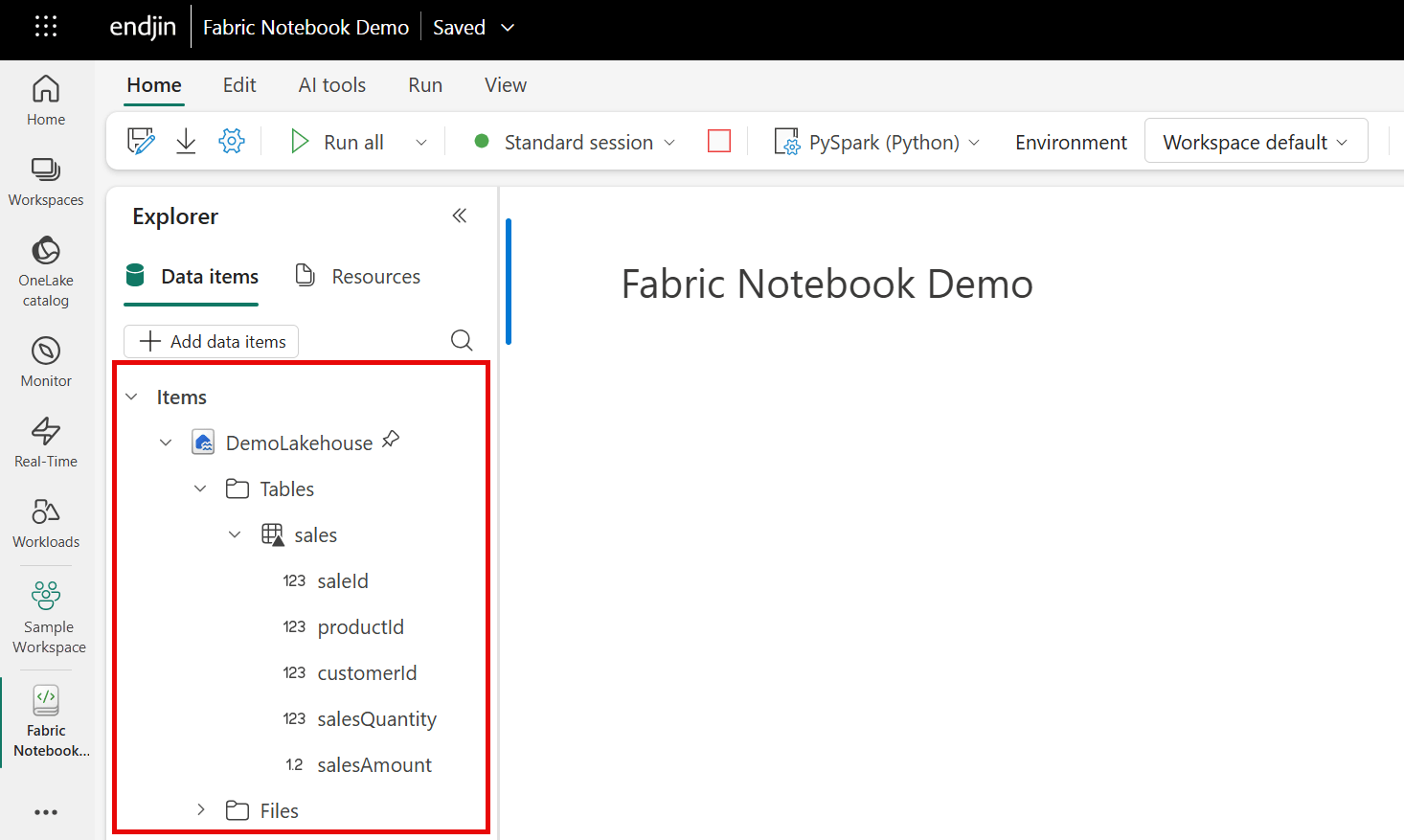
Built-in File System with Notebook Resources
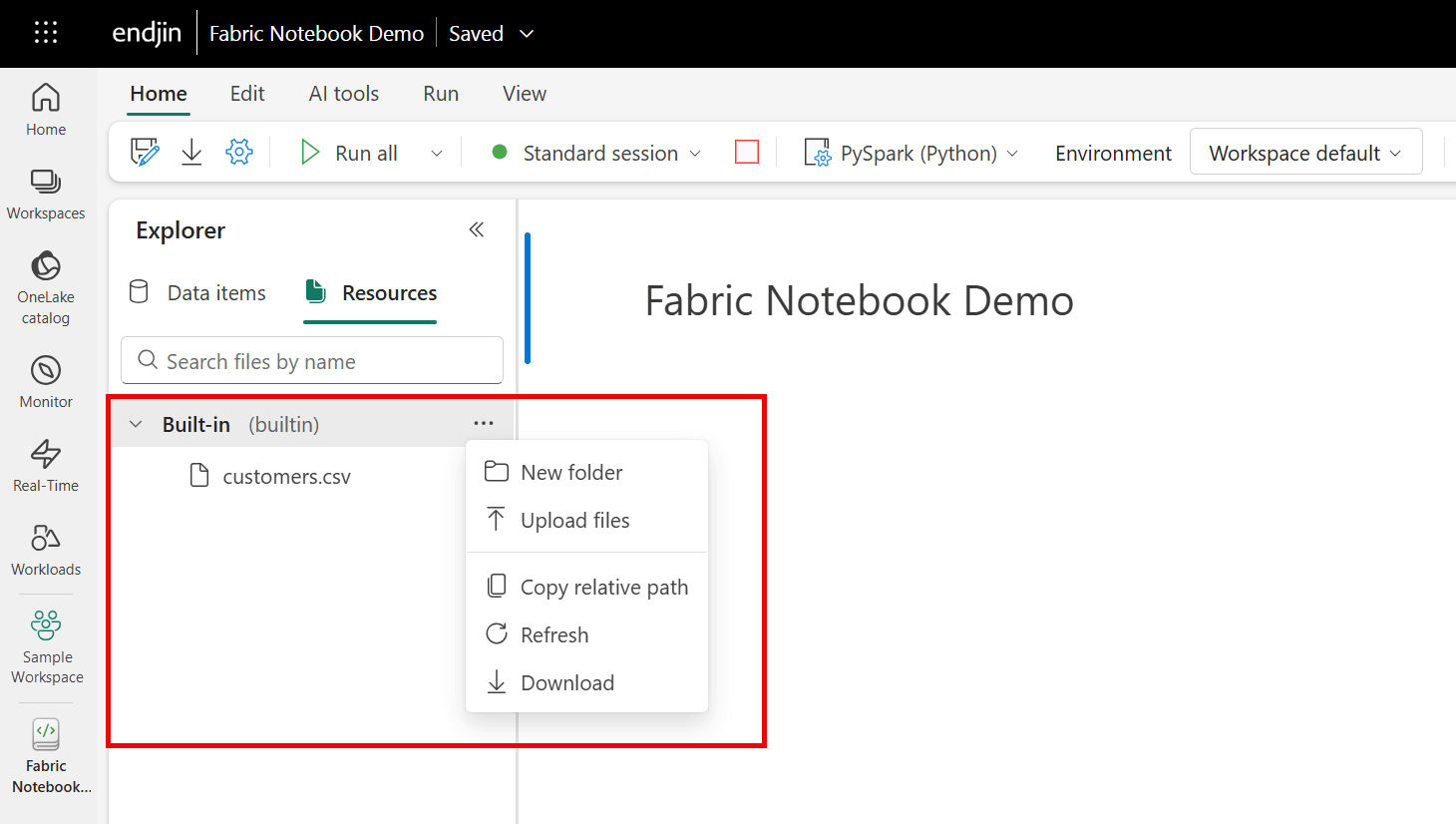
Fabric notebooks also come with a built-in file system called notebook 'Resources', allowing you to store small files - like code modules, CSVs and images etc. The notebook 'Resources Explorer' acts like a local file system within the notebook environment, you can manage folders and files here just like you would on your local machine. Within your notebook, you can then read from or write to the built-in file system. The files stored in the file system are tied to the notebook itself, and are separate from OneLake. This is useful for when you want to store files temporarily to perform quick experiments or ad hoc analysis of data / scripts. Or, if you want to just simply store notebook-specific assets.
Drag-and-Drop Data Exploration with Data Wrangler
Fabric notebooks also have a built in feature called the 'Data Wrangler' which allows you to use the notebook interface to drag-and-drop files from your lakehouse / in-built file system into your notebook and load the data, all without writing any code. After dropping the file into the notebook, the data wrangler autogenerates the code needed to query and load the data. This low-code experience, simplifies data loading and lowers the barrier to entry to get started with data exploration. You don't need any coding experience to simply just load your data into your Fabric notebook.
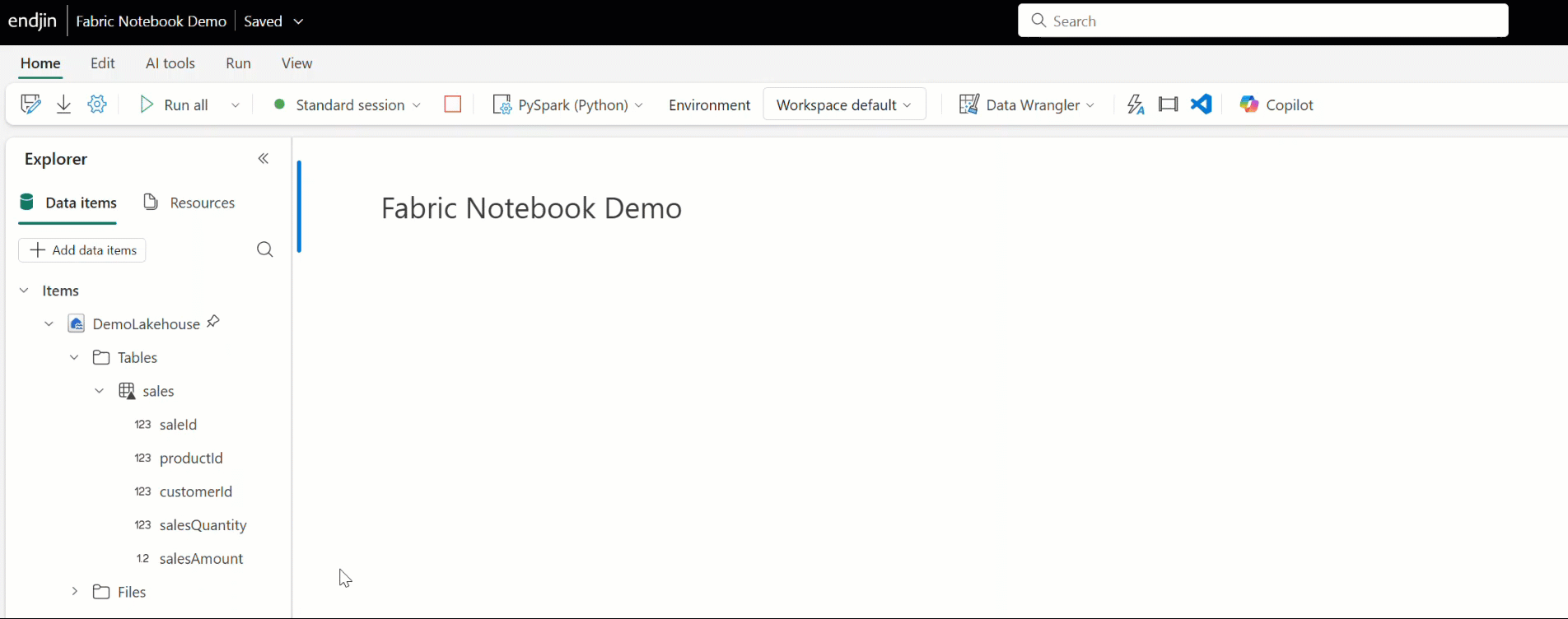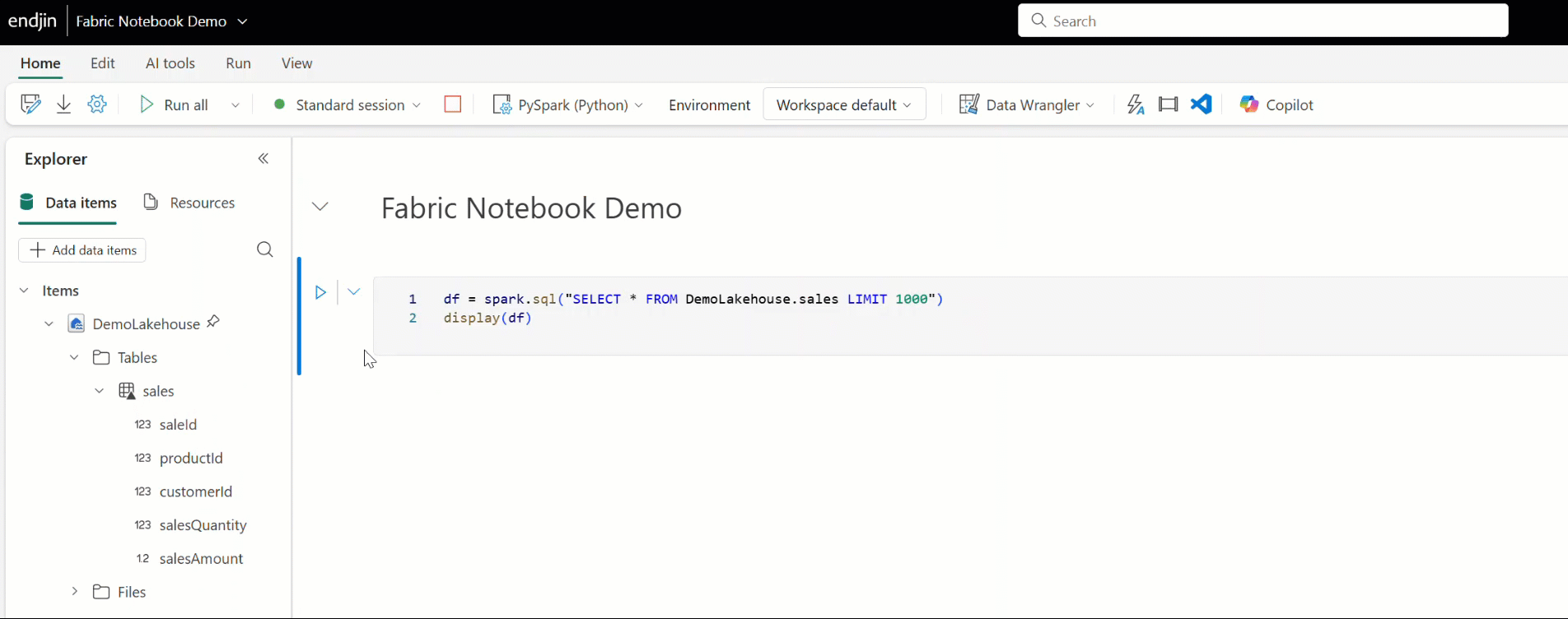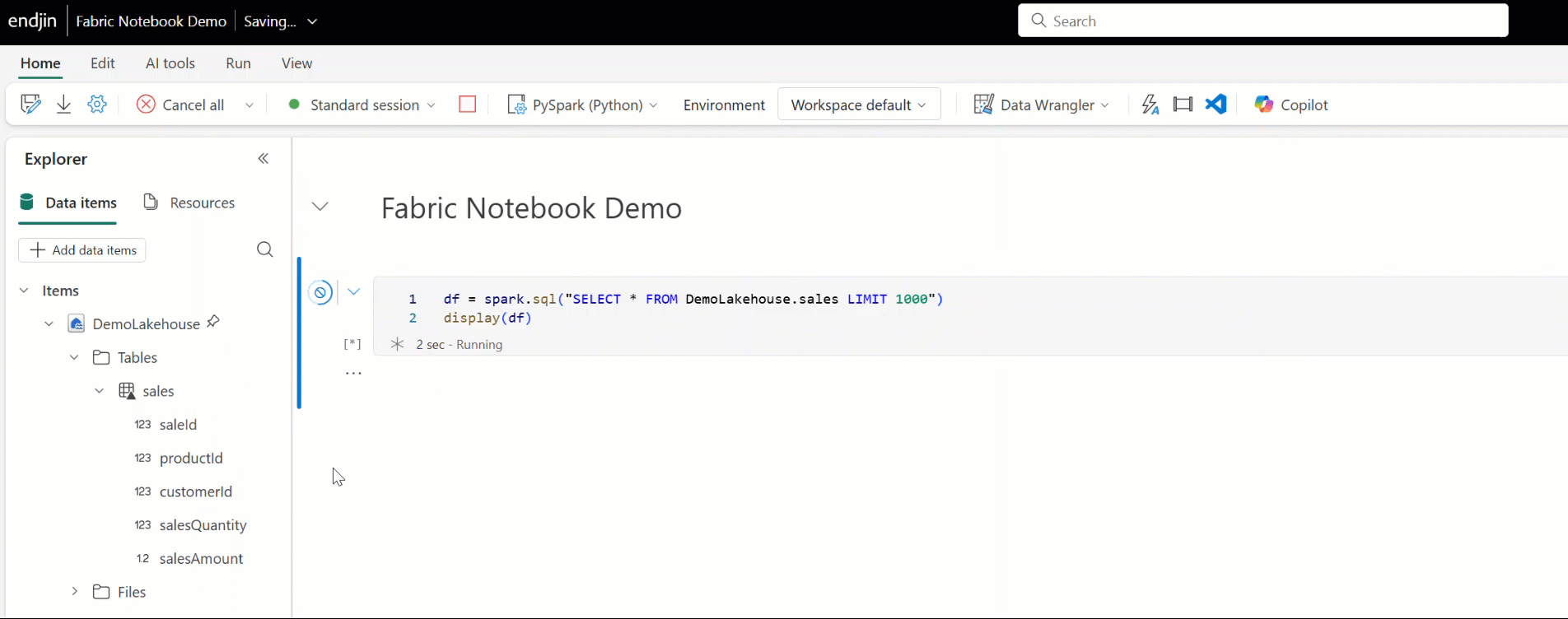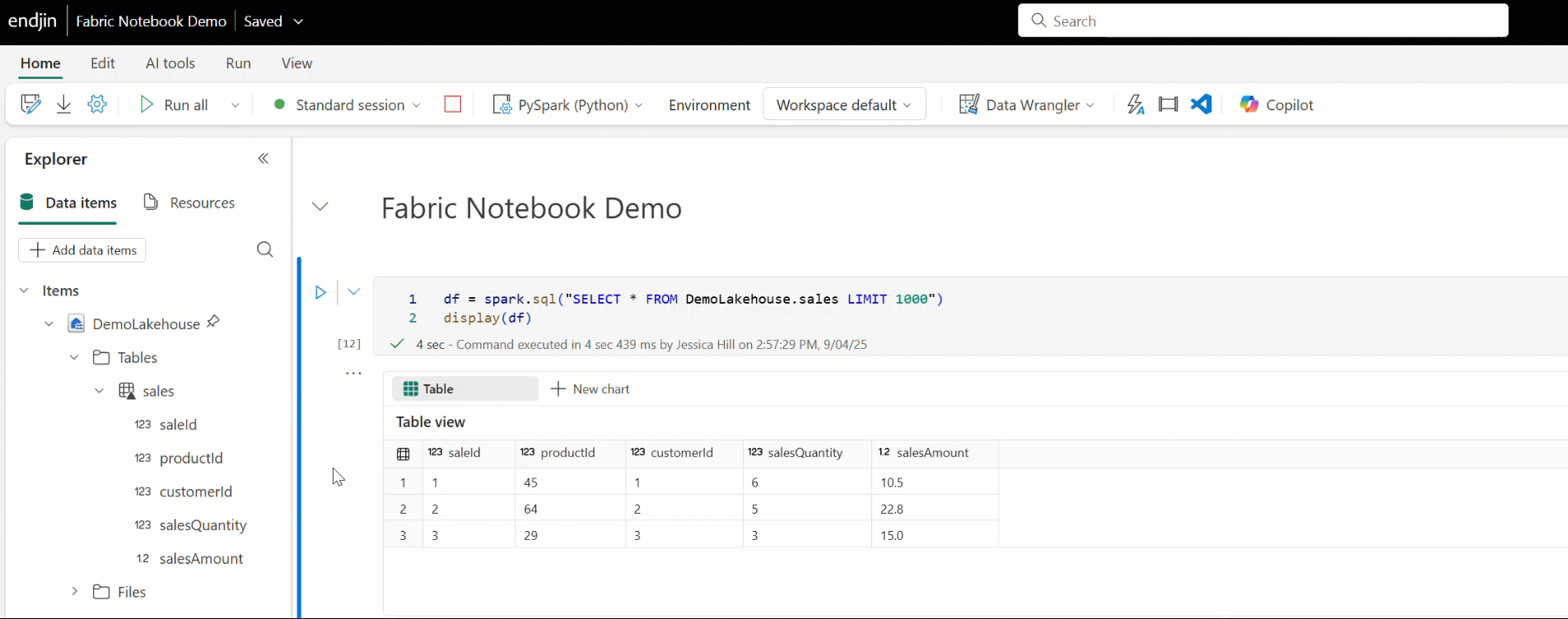
AI Assistance with Copilot
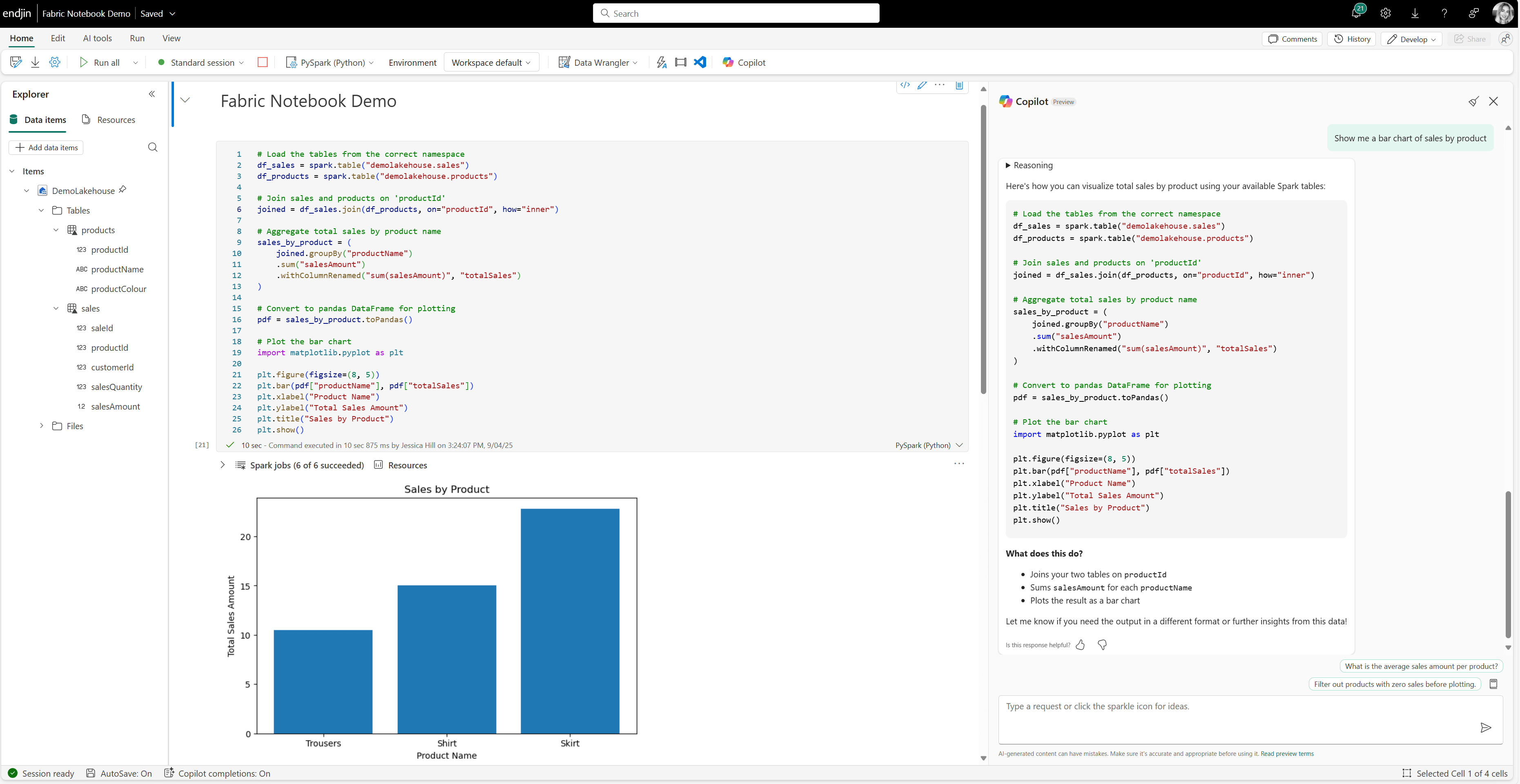
Copilot for Data Science and Data Engineering (Preview) is an AI assistant within Fabric notebooks that helps you to analyse and visualise your data. You can ask Copilot to provide insights on your data, generate code for data transformations or to build visualisations.
In Fabric notebooks, you can access Copilot by using the Copilot chat panel. Here you can ask questions like "Show me the top 10 products by sales", "Show me a bar chart of sales by product" or "Generate code to remove duplicates from this dataframe". Copilot will respond with either natural language explanations or will generate the relevant code snippets that you can copy and paste into your notebook to execute. You can also ask the Copilot chat to provide natural language explanations of notebook cells, and add markdown comments, helping you to understand and document your code. This makes data exploration more accessible, especially for those with a lower level of coding knowledge.
Alongside the Copilot chat, you can also interact with Copilot directly within your notebook cells by using the Copilot in-cell panel. Here you can make requests to Copilot and it will provide the necessary code snippet directly in the cell below.
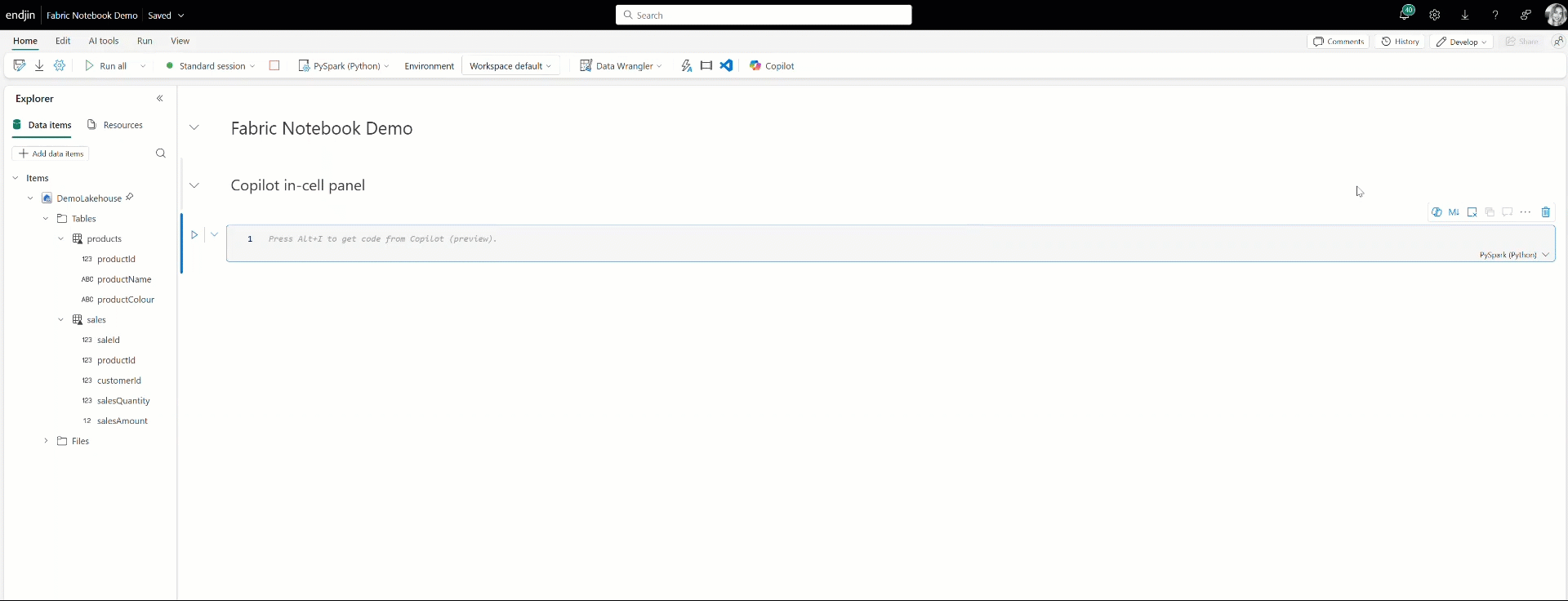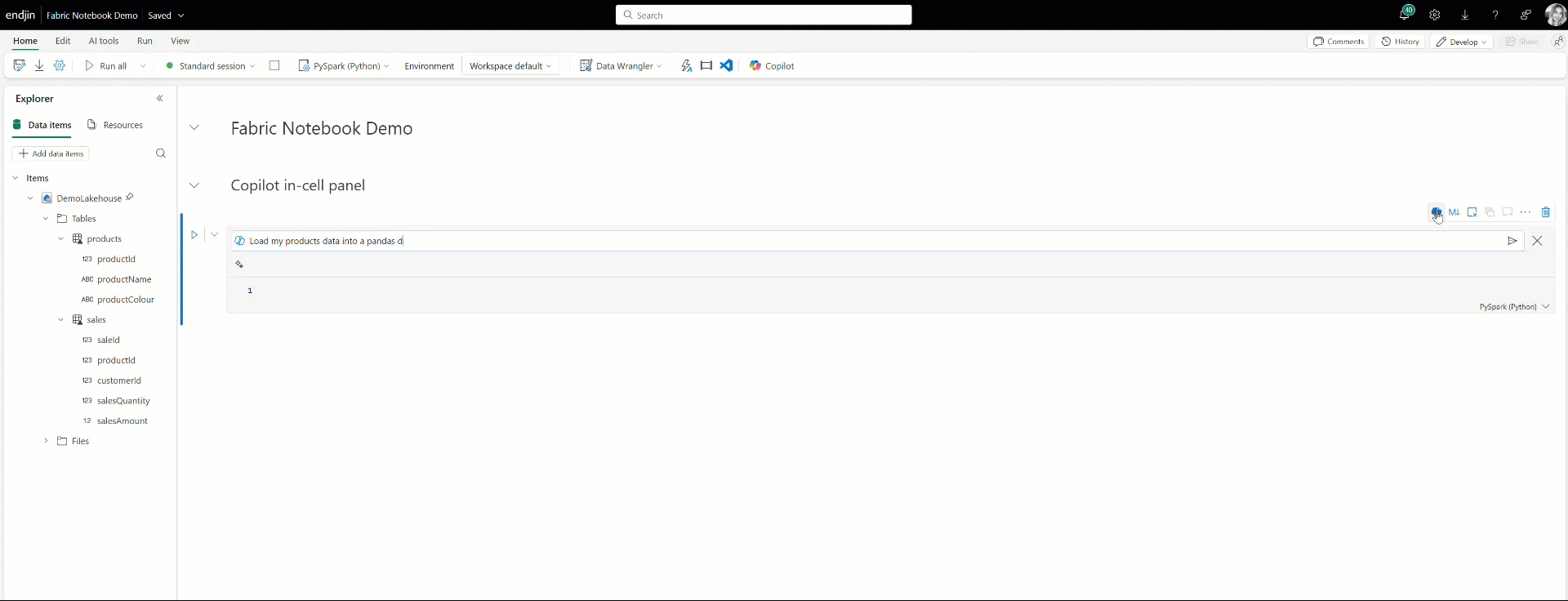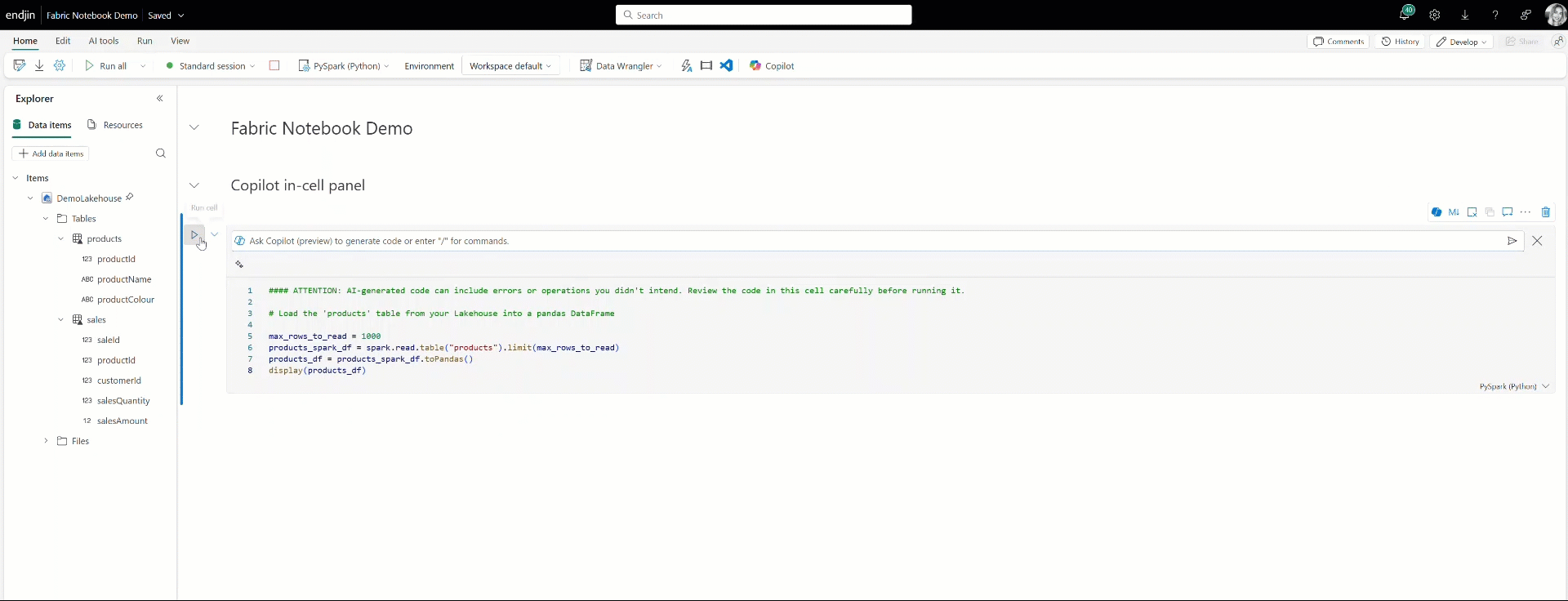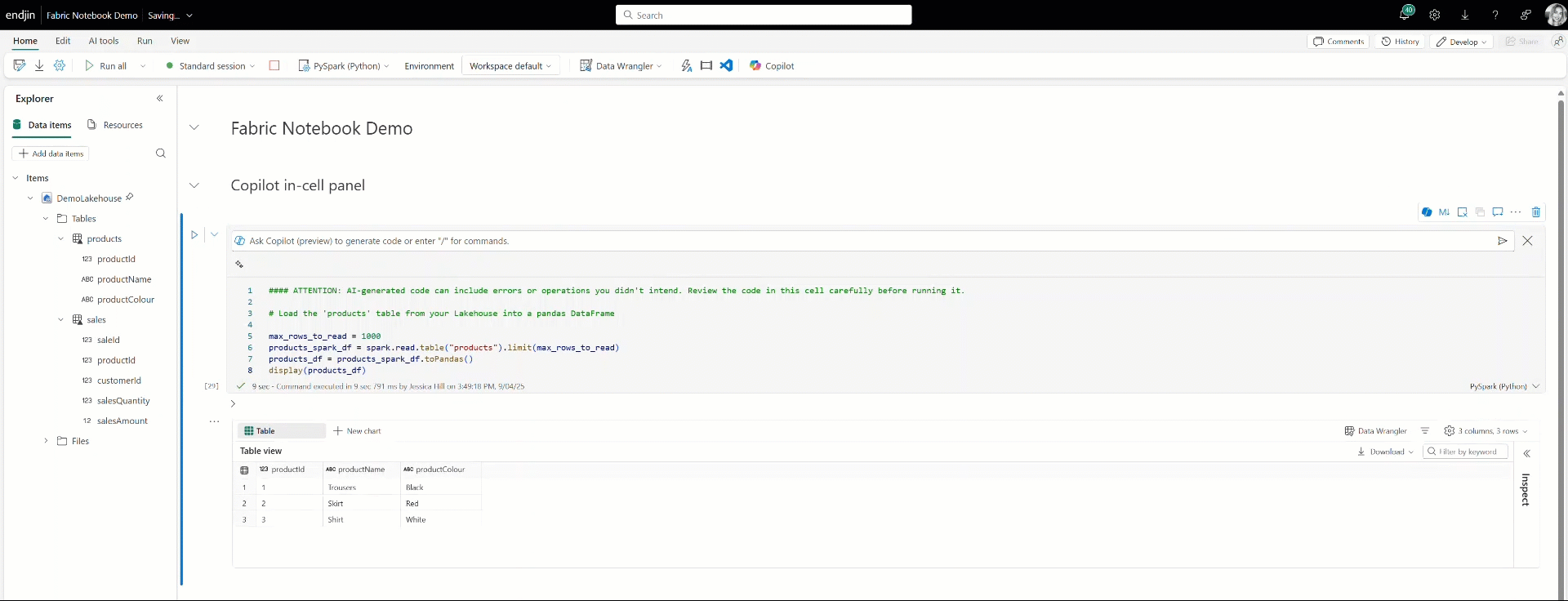
Also built into Fabric notebooks is Copilot's AI-driven inline code completion. Copilot generates code suggestions as you type based on your notebook's context using a model trained on millions of lines of code. This feature minimises syntax errors and helps you to write code more efficiently in your notebooks, accelerating notebook development.
You can also use Copilot to add comments, fix errors, or debug your Fabric notebook code by using Copilot's chat-magics. These are a set of IPython magic commands, that help you to interact with Copilot. For example, placing the %%add_comments magic command above a cell prompts Copilot to annotate the code with a meaningful explanation. Similarly, the %%fix_errors command analyses code and suggests corrections inline.
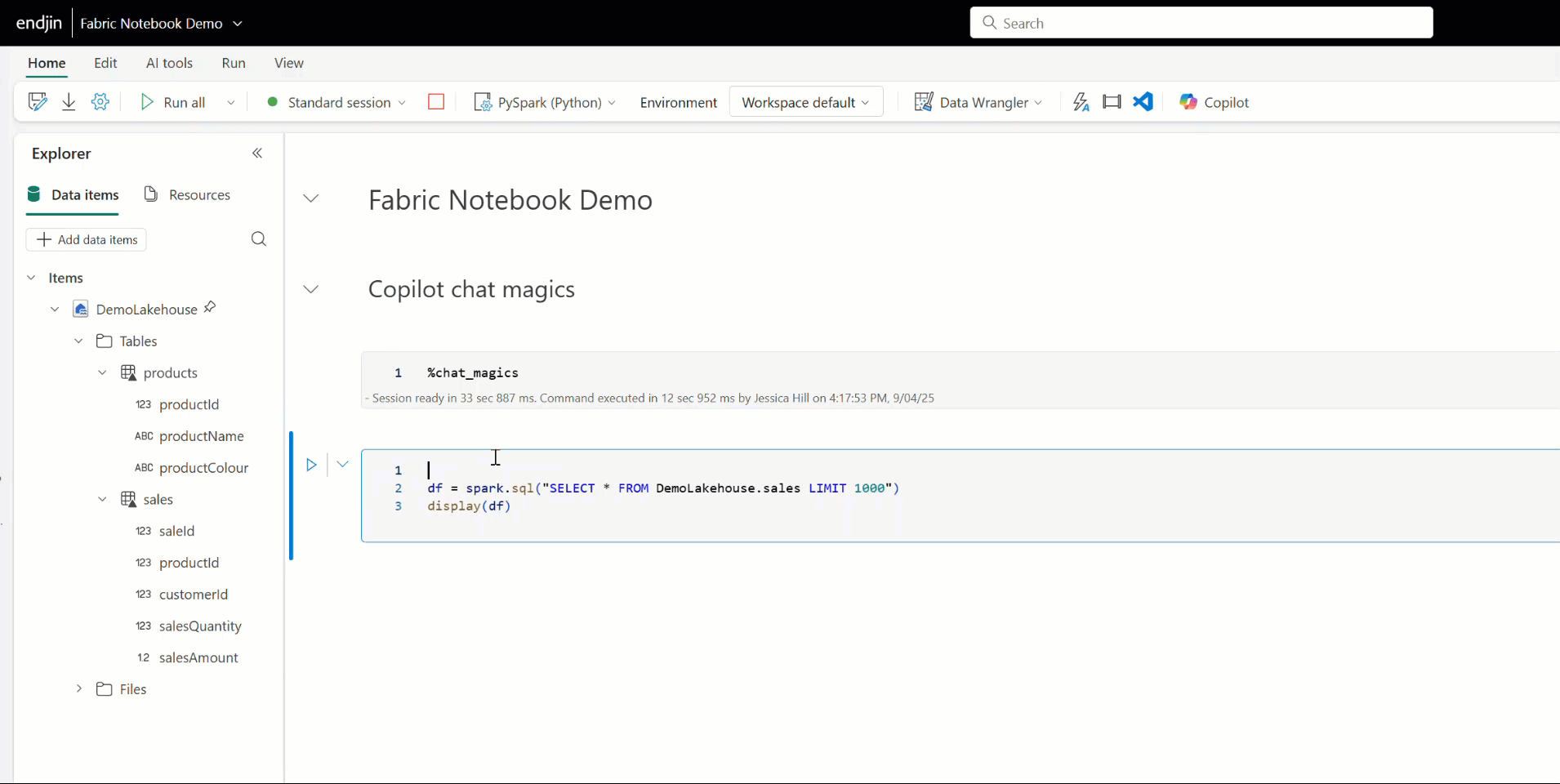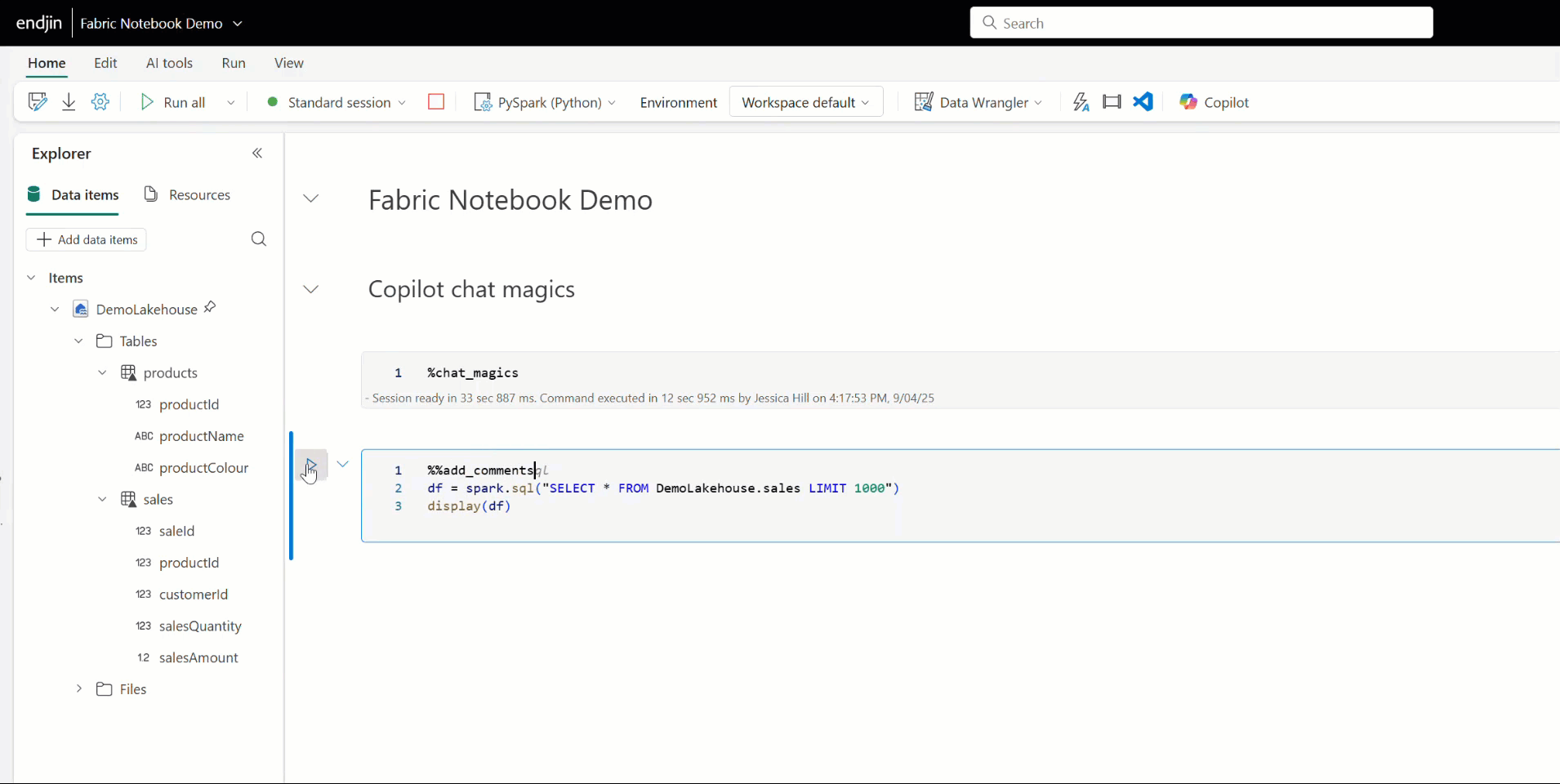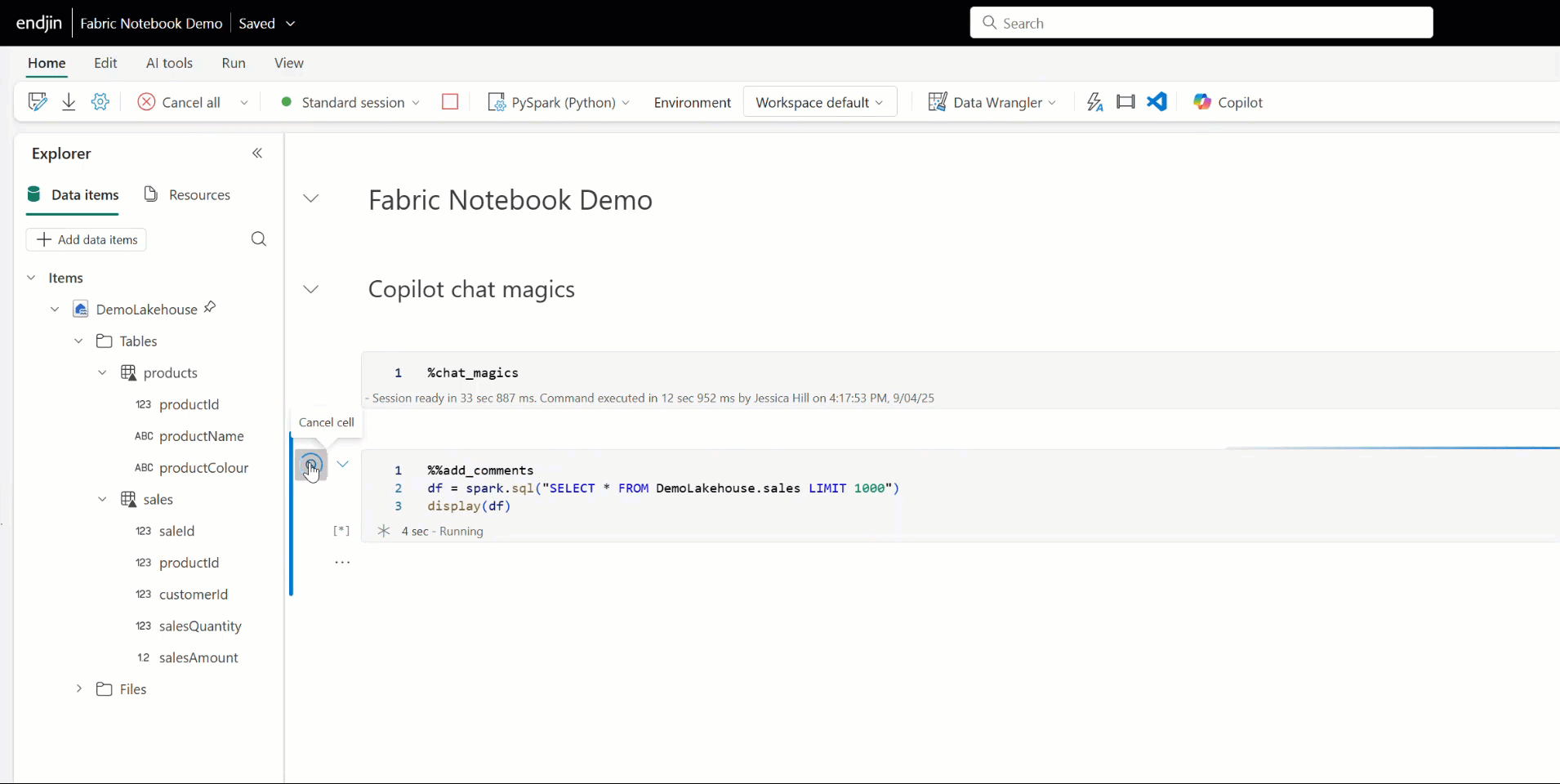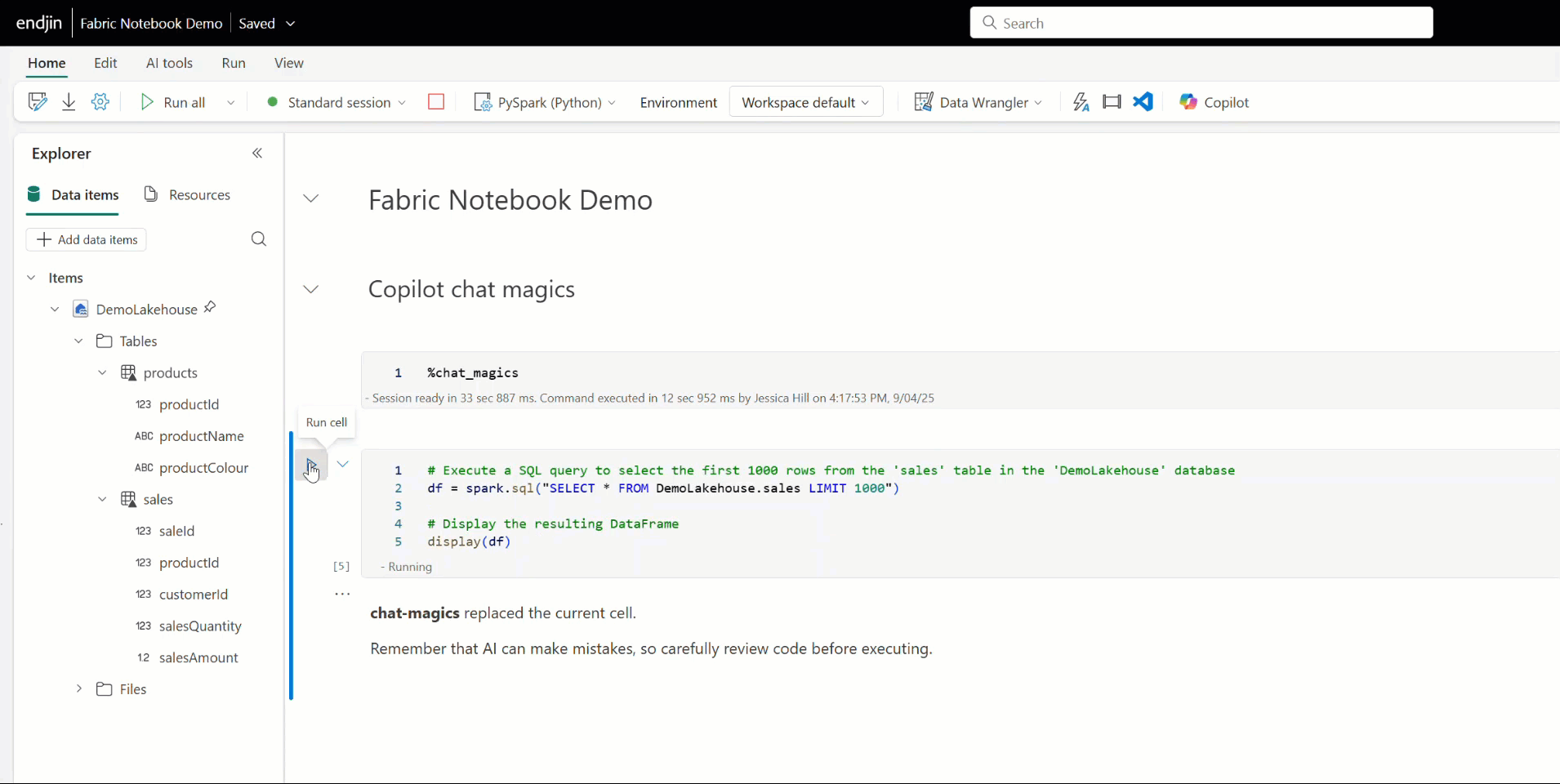
Having spent time working with Copilot in Fabric notebooks, I've found the main advantage is that is that it saves time. Even if the output needs tweaking, it saves time and effort upfront by doing the bulk of the ground work. This is especially true for tasks that don't require deep contextual understanding or complex decision-making, for example reading/writing data, creating schemas from dataframes, renaming columns, basic transformations etc. Or for tasks where is already a pattern in place within your code base, as you can ask Copilot to base its output on that, and it's generally accurate. I've also found that it's good at debugging your code and can spot things that are not always obvious, and it's pretty good at generating documentation too, all of which also saves time and effort.

However, Copilot doesn't always fully understand the context or intent behind your work. This is especially true for more complex tasks. Or, sometimes it might suggest code that is unoptimised. This is why you can't be fully reliant on Copilot's suggestions, you still need to review and refine what it generates. That said, even if the output isn't exactly what you need, it is often along the right tracks and can give you inspiration to get started. On the whole it's useful to get unblocked and speed up routine tasks, but it should be used as a tool to assist you, whilst you stay in control of the decision making behind your code. It is also worth noting that most of the Fabric notebooks Copilot features described above are currently in Preview.
Faster Spark Start-Up
With the Spark-based Fabric notebooks, it is generally very quick to spin up a Spark session. If you have ever used notebooks in Azure Synapse before, you will know it takes a few minutes to spin up a Spark session. However, with Fabric notebooks, it takes a matter of seconds. The fast start up times for Spark sessions is due to Fabric's starter pool model, which keeps a lightweight Spark runtime ready to serve new sessions. This means when you initiate a Spark job, it can attach your session to an already running pool and it doesn't need to provision a full cluster from scratch.
If you're running Spark sessions anywhere else in your tenant, the Spark runtime should start very quickly. This is because Fabric re-uses active sessions across the tenant. If any Spark session is already active within your tenant, your notebook can essentially piggyback on that runtime, allowing it to start in seconds. However, it is worth noting that if it's the first time you've run a Spark job in a while, it will take slightly longer to spin up a Spark session.
Python Notebooks
Python notebooks in Fabric offer a pure Python coding environment without Spark. They run on a single-node cluster (2 vCores / 16 GB RAM) making them a cost-effective tool for processing small to medium sized datasets where distributed computing is not required. Using the Apache Spark engine for small datasets can get expensive and is often overkill. Depending on your workload size and complexity, Python Notebooks in Fabric may be a more cost-efficient option than using the Spark-based notebook experience in Fabric.
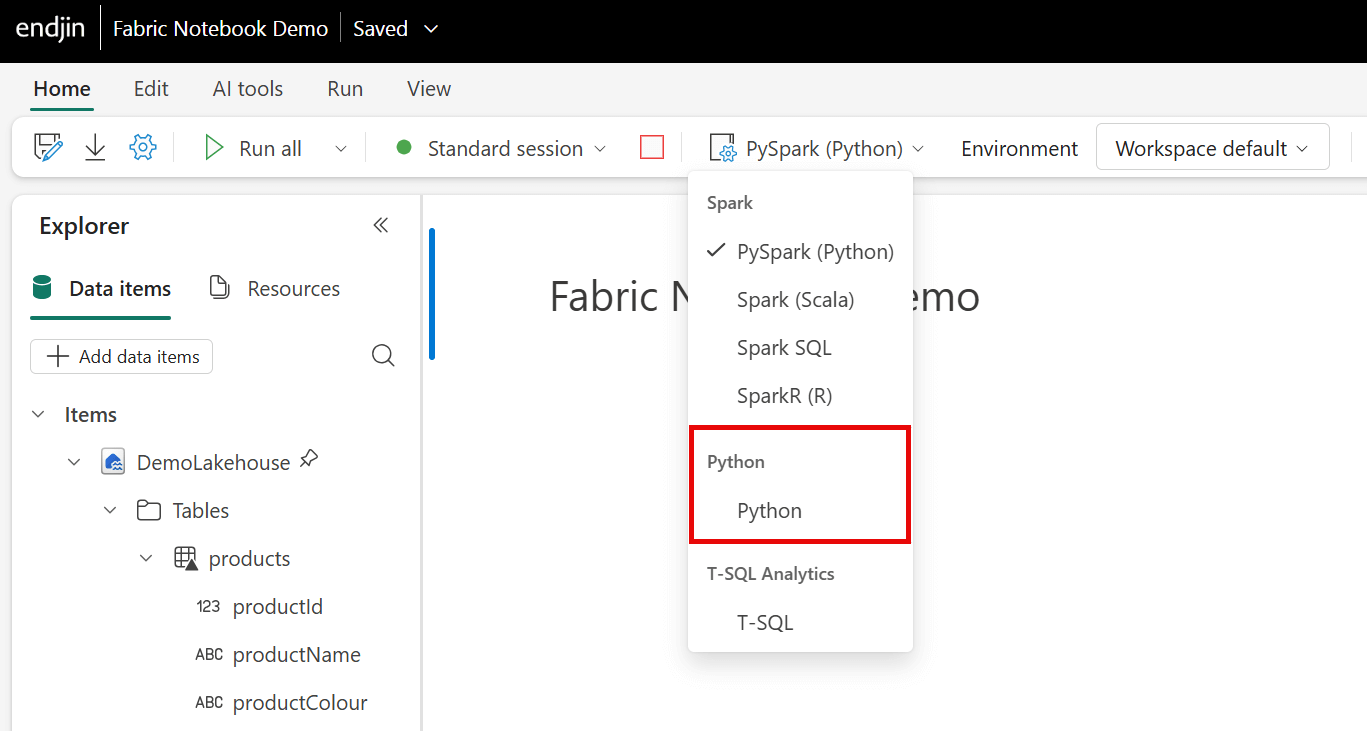
The Python notebook runtime comes pre-installed with libraries like delta-rs and DuckDB (See Barry Smart's 3-part series on DuckDB) for reading and writing Delta Lake data, as well as the Polars and Pandas libraries for fast, data manipulation and analysis. This environment is ideal for those who want to leverage these libraries without additional setup. These libraries are not available by default in PySpark notebooks in Fabric, meaning that you would need to manually install and configure them to access similar functionality. For workflows that benefit from these specific libraries, Python notebooks offer a more ready-to-go experience.
Integration with Power BI Semantic Models through Semantic Link
The final key feature of Fabric notebooks that this blog post is going to cover is their integration with Power BI semantic models through Semantic Link. Semantic Link is a feature in Fabric that connects Power BI semantic models with Fabric notebooks. It enables the propagation of semantic information - like relationships and hierarchies from Power BI into Fabric notebooks.

Fabric notebooks also have access to Semantic Link Labs, which is an open-source Python library built on top of Semantic Link, which contains over 450 functions that enable you to programmatically manage semantic models and Power BI reports all from within Fabric notebooks. You can do things like rebinding reports to new models, detecting broken visuals, saving reports as .pbip files for version control or deploying semantic models across multiple workspaces with consistent governance.
Python notebooks in Fabric also offer support for the SemPy library. This is another Python library built on top of Semantic Link that enables you to interact with Power BI semantic models using pandas-like operations (but it's not actually pandas under the hood). SemPy introduces a custom object called FabricDataFrame, which behaves similarly to a pandas dataframe but it is semantically enriched. This means it carries metadata from Power BI semantic models - like relationships, hierarchies, and column descriptions. SemPy supports operations like slicing, merging and concatenating dataframes whilst preserving these semantic annotations. This means that you can explore and transform your data, with semantic awareness maintained.
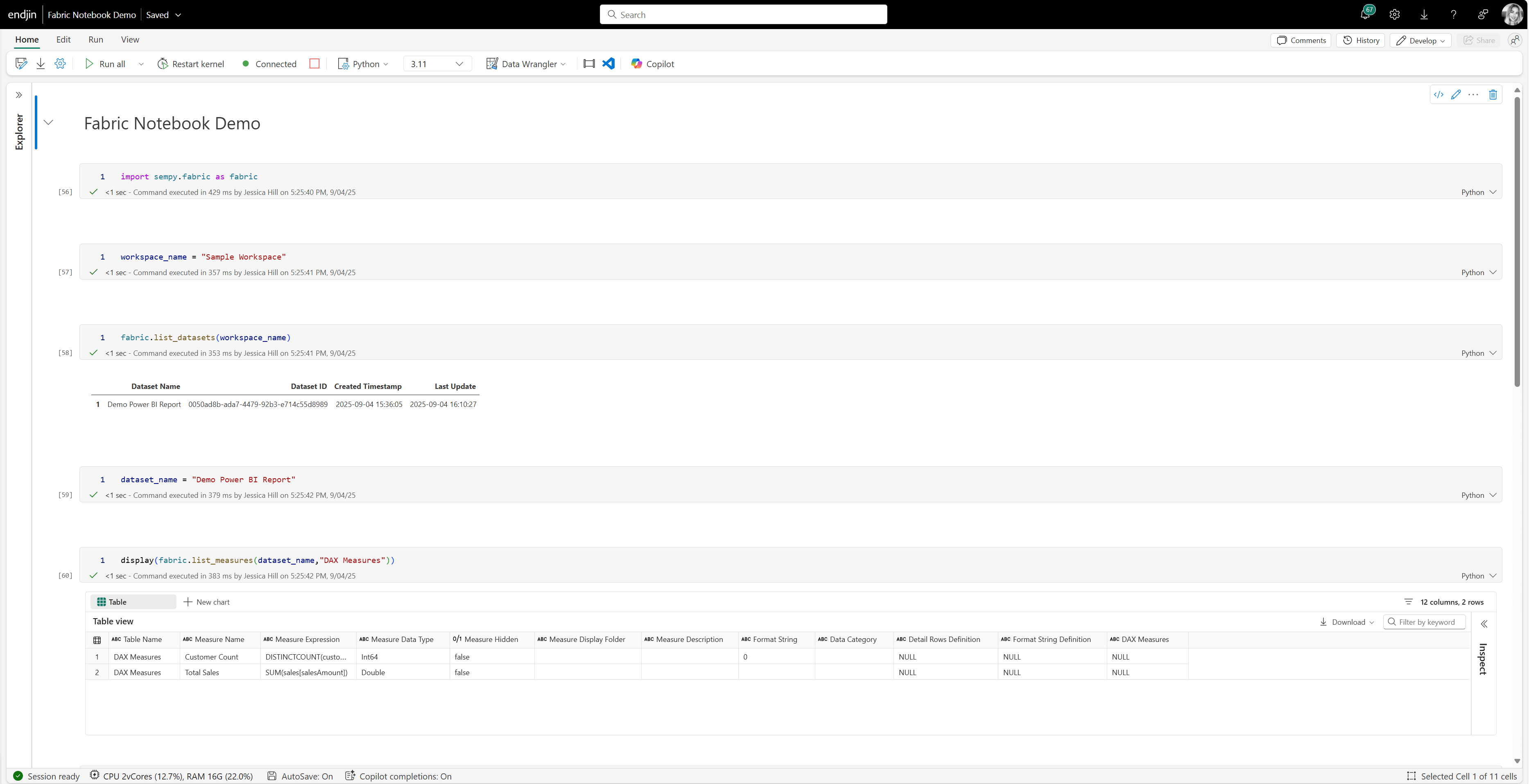
Another key feature of the SemPy library is the ability to retrieve and evaluate DAX measures from your Power BI semantic models. For example, you can use SemPy to retrieve DAX measures like "Total Sales" from your semantic model. Similarly, with SemPy, you can also write new DAX expressions and evaluate them within your notebook.
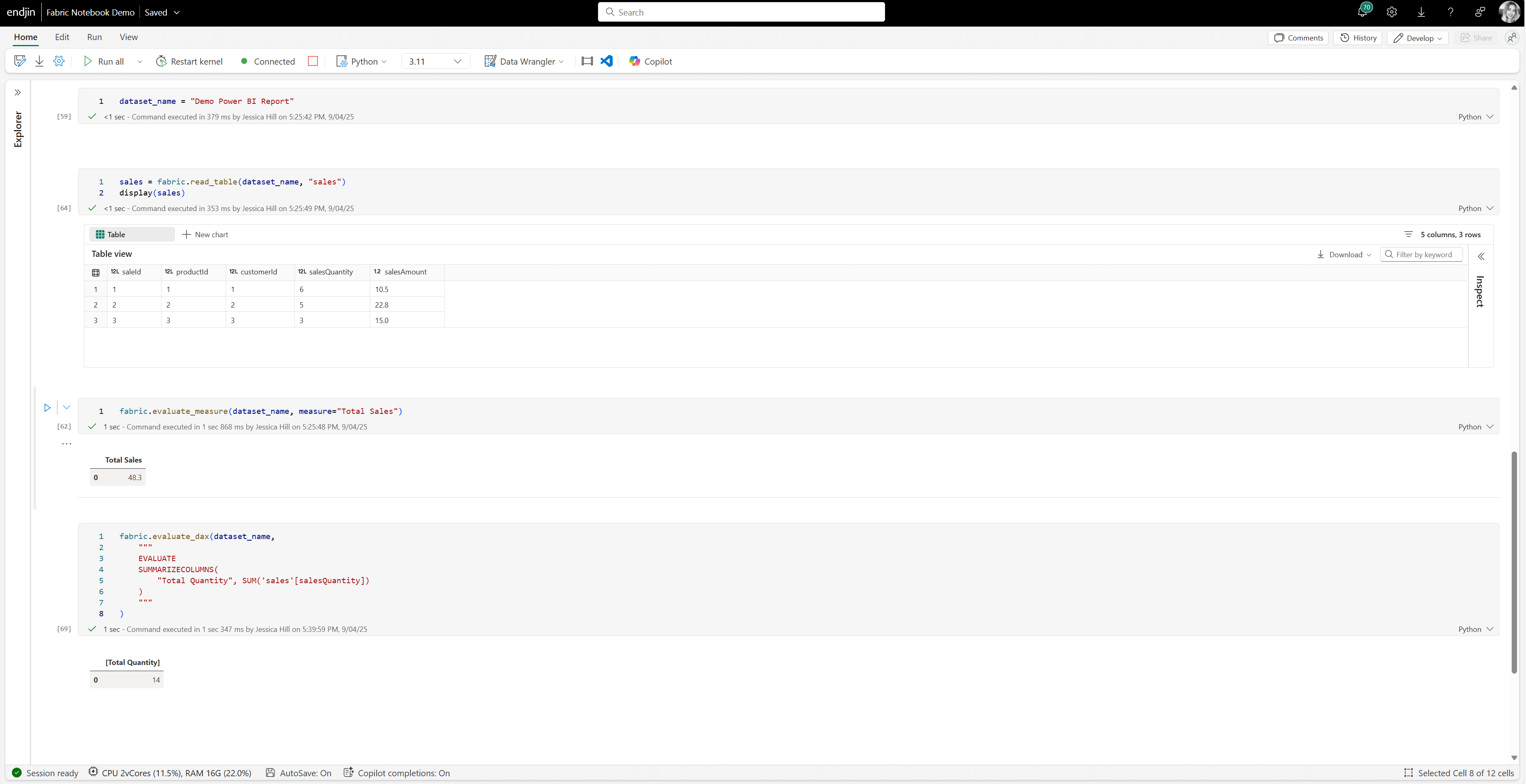
This means you can use business logic, like calculated KPIs or aggregations, defined in Power BI directly in your notebooks, without needing to reimplement the logic manually in Python. Using business logic already defined in Power BI, directly in your Fabric notebooks, reduces duplication and ensures consistency. It also promotes collaboration between data scientists working in Fabric notebooks and business analysts working in Power BI - as both are using a shared semantic layer.
Note that all notebook experiences in Fabric support Semantic Link, but only the Python notebook experience in Fabric offers support for the SemPy library.
Conclusion
Fabric notebooks offer a lot of great features. You can access your lakehouse data easily through the Lakehouse Explorer and store your notebook-specific assets in the built-in file system. The drag-and-drop experience with Data Wrangler makes data exploration accessible, and Copilot provides AI assistance for writing, documenting, and debugging code as well as generating insights from your data. Spark sessions are quick to start up due to Fabric's starter pool model, which makes distributed processing faster than platforms like Azure Synapse.
Python notebooks provide a lightweight, cost-effective alternative for smaller workloads, and come pre-installed with libraries like Polars, DuckDB, and delta-rs - providing a ready-to-use environment for your analytics. Finally, the integration with Power BI semantic models through Semantic Link, Semantic Link Labs, and SemPy allow you to interact with semantic models programmatically, apply DAX measures directly in notebooks, and maintain semantic integrity across transformations. This shared semantic layer promotes collaboration between data scientists and business analysts, which ensures consistency and reduces duplication of logic across platforms.
Whilst these are the top features that stood out to me, there are also lots of other capabilities within Fabric notebooks, so do go and check them out yourself. My colleague Ed has produced a great YouTube video series on getting started with Fabric notebooks, including Microsoft Fabric: Processing Bronze to Silver using Fabric Notebooks and Microsoft Fabric: Good Notebook Development Practices.



