FabCon Vienna 2025: Day 2


Day 2 at FabCon, we shifted from the raft of announcements, into some more deep-dive technical sessions. We covered OneLake capabilities, the new Maps functionality, and some great AI integration demos.
Not only this... But I picked up my new favourite item of clothing!

Keynote - Exploring the Fabric Ecosystem: Databases, Security and AI at Scale
(Shireesh Thota - Microsoft, Kim Manis - Microsoft, Marco Casalaina - Microsoft, Jessica Hawk - Microsoft).
Day 2's Keynote was a far-reaching overview of the Fabric ecosystem as a whole.
They kicked off by showing how you can connect to Fabric items directly from VS Code, including deploying new SQL databases straight into your Fabric workspace.

They demonstrated "reverse-ETL" scenarios. These used Fabric to generate insights and then automate actions based on those insights. This is a powerful pattern for closing the loop between analytics and operations.
A significant chunk focused on AI, risk, and security. The new workspace-level security controls were interesting - Using these, you can enact policies that are either mandatory or monitored, with alerting for issues like bad data uploads.
There was new functionality highlighted for Fabric Data Agents:
- Support for mirrored sources - meaning that mirrored data is now incorporated in queries and responses
- Git integration (like all Fabric objects, agents are now supported in Git.)
- You can also now invoke agents from outside Fabric - for example, from Azure Foundry.
They showed a real-time translation demo of a Teams call, which I can imagine being very useful! Translation in real-time would be another step in what (in my opinion) is one of the most powerful uses of AI as yet - in allowing communication across boundaries like never before.
Then came a GitHub integration demo. This used the "GitHub Spec Kit" to write specifications, then got an agent to create branches, implement changes, and raise PRs. Quite impressive, though I'd be interested to see how it's able to handle more complex scenarios and specifications! For the moment, I'd certainly at least want a human to be reviewing the PRs raised...
Bringing Data into OneLake: A Deep Dive into Shortcuts and Mirroring
(Trevor Olson - Microsoft, Maraki Ketema - Microsoft)
This session provided a thorough exploration of OneLake's data virtualisation capabilities.
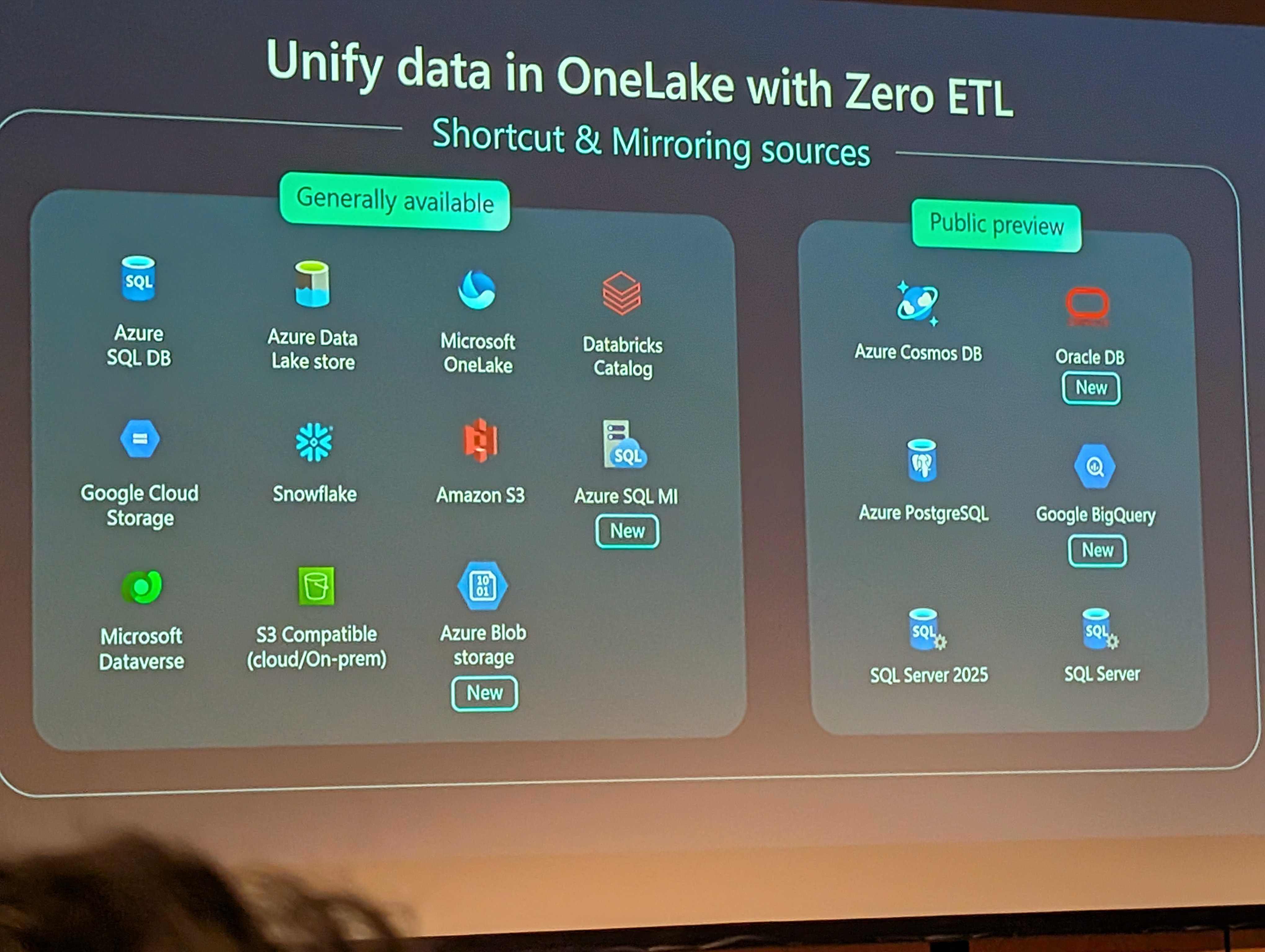
Shortcuts
Shortcuts in OneLake are virtual pointers which allow you to reference data stored in external sources (such as Azure Data Lake Storage, Amazon S3, or other lakehouses), without physically copying or moving the data.
This enables seamless access and unified analytics across multiple storage systems, reducing data duplication and simplifying data management. Shortcuts are native items within OneLake, making it easy for users and services to query and process external data as if it were local, while maintaining a single source of truth and improving collaboration across teams. The shortcutted data behaves identically to native data (just with a different icon!).
There have been multiple enhancements for shortcuts in OneLake:
- File cache (GA) with configurable retention and API reset capabilities. This is enabled in the OneLake settings.
- Cross-cloud identity federation with S3 (public preview)
- Enhanced network security, where you can support trusted service access and don't need to define the gateways yourself
- Metadata transformation (GA)
- Data transformation (preview) - where you can apply transforms (parquet to delta, JSON to delta, and AI transforms) as part of the shortcut
- You can now edit shortcuts (GA) rather than recreating them
- Git integration with variable mapping and workspace variables
- Key Vault support (GA)
- Azure Blob Storage shortcuts (GA) including anonymous auth
- Improved Dataverse authentication options (Service Principal, Workspace ID)
Mirroring
If you want to see both your external data in OneLake and the metadata and catalog information that describes it, then you can use mirroring.
In mirroring scenarios, all metadata associated with the items is "mirrored" into the OneLake catalog. The data is also then mirrored, in one of two ways:
- For open data formats, shortcuts are created to the data.
- For propriety data, a replica of the data is created within OneLake, and kept in-sync using change management. The compute used for this process is free, and the storage itself is also free up to a point.
Open mirroring (preview) is a platform which allows you to extend mirroring to legacy systems and bespoke applications. Some partner companies have already built custom mirroring solutions on this platform.
The integration with Fabric Data Agents means you can pull mirrored data directly into agents and join tables from different sources. This is a powerful combination for cross-system analytics.

Geospatial Insights for Everyone with Maps now in Fabric
(Johannes Kebeck - Microsoft)
The next session we attended focused on the new Maps functionality in Fabric. It handles large datasets much better than Power BI maps and offers extensive customisation options. The integration with event streams enables real-time geospatial intelligence.
The technical implementation uses tilesets for performance. This creates vector tiles at different zoom levels and only showing data which will show up on the available pixels. All layers are stored as a single compressed file.
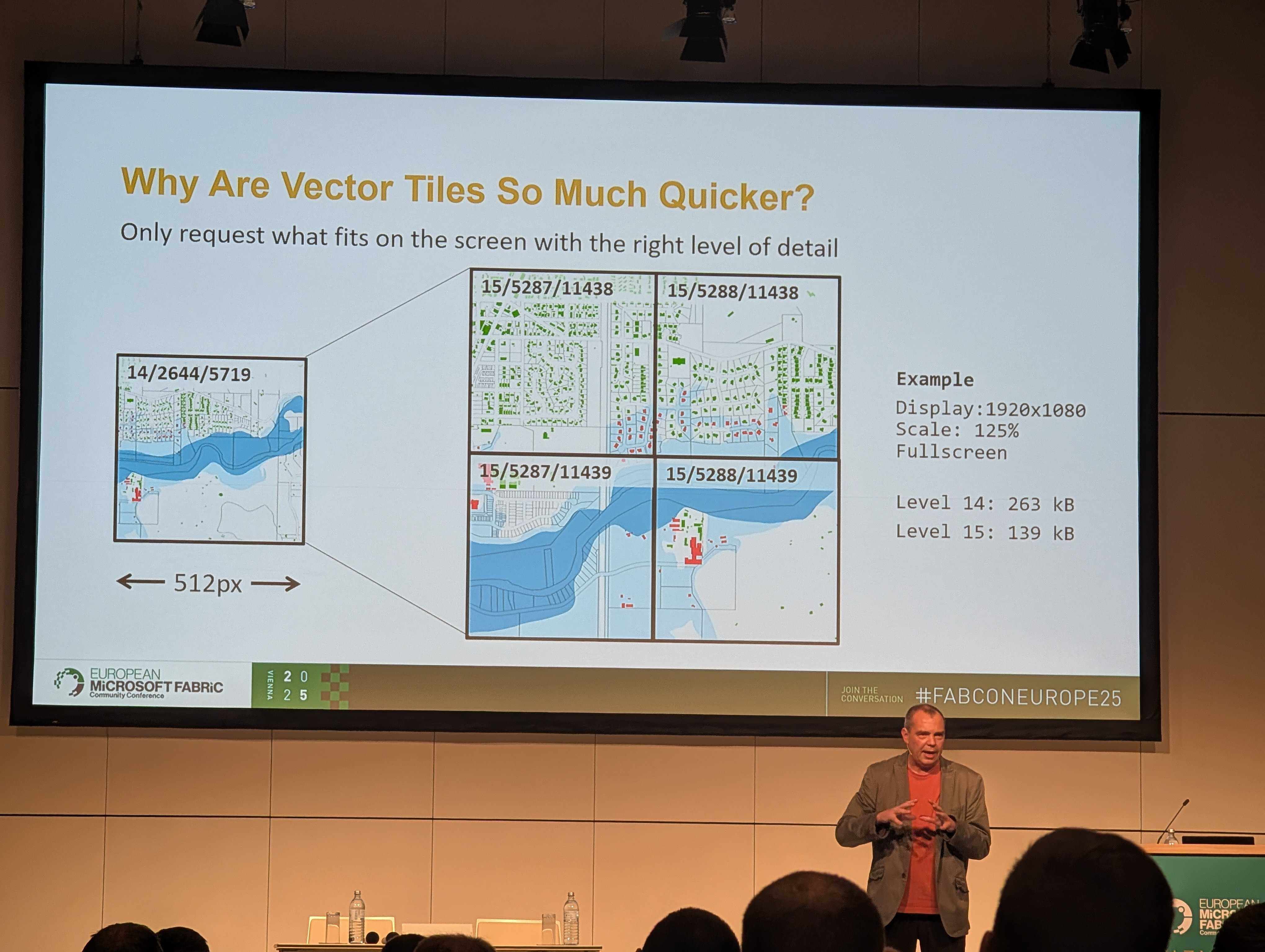
The demo connected to an event stream and grouped geometry data into H3 tiles (a geo-spatial indexing system developed by Uber) using KQL. They also showed a demo of using Fabric Maps to track faults across a power grid in real-time, and mentioned applications such as precision farming and queue management.
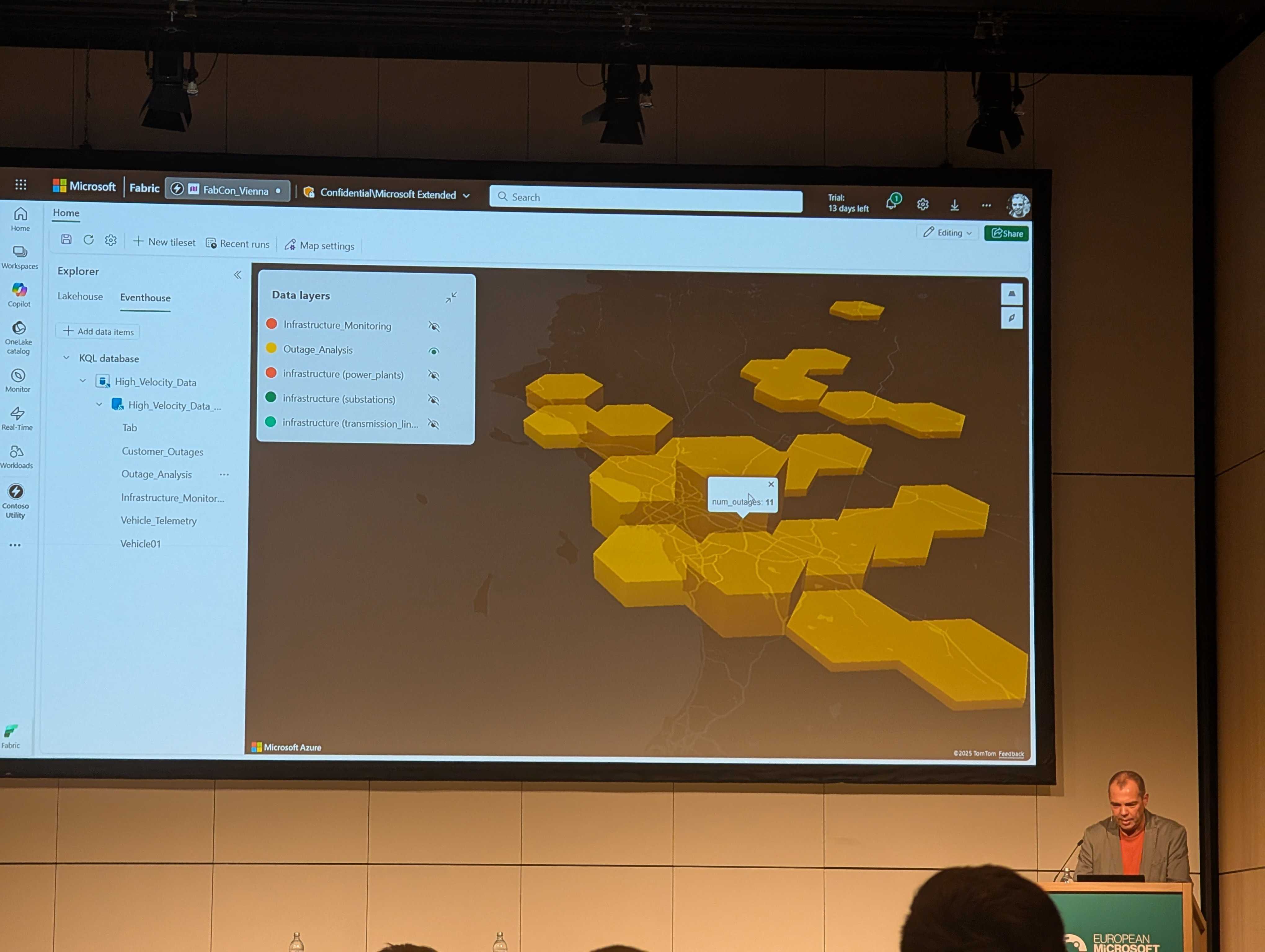
While it's not GA yet, once production-ready this could be a powerful tool for anyone needing to perform geospatial analysis, especially in real-time.
Operationalize Fabric-CICD Python Library to Work with Microsoft Fabric and Azure DevOps
(Kevin Chant - Macaw)
This session ended up being more of an Azure DevOps overview than the Git integration deep dive I was hoping for.
Here at endjin, coming from software development backgrounds, we are used to the option of working concurrently on software, at scale. Personally, I'm still a little unclear how you would achieve this given the current Git functionality in Fabric.
The advice seems to be to have a workspace per branch, or per developer, which they attach to a branch and make changes. But this solution doesn't seem like it would scale well across large development teams!
Note for clarity - this isn't a criticism of the session, which was a good introduction to Azure Devops and the fabric-cicd python library - it just wasn't the session I had assumed it was (due to my misinterpretation of the session title)! The question above around branching policies and how to operationalisation of Fabric CI/CD in general did come up, and caught my attention due to it being one of my leading remaining questions around how teams should adopt and start to use Fabric in anger.
Integrating Microsoft Fabric and Azure AI Foundry for a Real-World Scenario
(Monica Calleja - Microsoft, Sara Lammini Rodriguez - Microsoft)
This was an excellent session on integration between Fabric and Azure Foundry. They walked through a real-world scenario tackling customer churn at a bank using a multi-agent system in Azure Foundry.
The multi-agent architecture was made up of:
- Customer Info Retriever Agent: Used a Fabric Data Agent published as an endpoint.
- Customer Churn Prediction Agent: Connected to a machine learning model created in Fabric Data Science, trained on historical churn data and exposed via an endpoint.
- Loyalty Programmes Agent: Used Azure AI Search for RAG over PDF documents containing loyalty programme information, which was all vectorised and searchable.
- Orchestration Agent: Coordinated all three agents, determining which to call based on the question and parallelising calls to save tokens.
The Agents Playground in AI Foundry provides a testing environment before deploying to production apps. You could see exactly which agents were called and how the orchestration worked.
The end result was a chat-bot interface where business users could ask: "Give me all info on Customer X. Are they likely to churn? If so, recommend a loyalty programme." The orchestration agent would call all relevant agents and synthesise a response.
This demo showcased the true potential of multi-agent systems. Specialised agents can work together to solve complex business problems, that might otherwise be challenging - for humans, or for AI!
Overall
Day 2 provided much more hands-on technical content compared to the announcement-heavy Day 1. The OneLake deep dives, Maps functionality, and especially the multi-agent AI demo showed in-depth practical applications of the Azure stack, all brought together by Microsoft Fabric.
The day finished with a beautiful sunset over Vienna. Stay tuned for day 3!

If you're interested in Microsoft Fabric, why not sign up to our new FREE Fabric Weekly Newsletter? We also run Azure Weekly and Power BI Weekly Newsletters too!



