What is a Data Lakehouse?


In the last few years a lot has changed in the data space. I am acutely aware of this, having left for a career break in mid-2021 and returned to a data landscape that (at first glance) seems unrecognisable to that of 3.5 years ago.
One of the main developments has been the wider adoption of data lakehouses. In this blog I am going to give an overview on what exactly is a lakehouse, a general introduction to their history, functionality, and what they might mean for you!
How we got here
In the constantly changing world of data it can be difficult to keep track of the latest developments and trends, and how they differ from what came before.
The data lakehouse architecture is built on the back of years of developments in the data space. It combines both old and new technologies, to create a new centralized idea that I believe could revolutionise how we interact with data. I often find myself scrolling past the "history" sections of technical articles, but in this case I believe it is integral to understanding lakehouses and the huge amount of value they bring to a data environment.

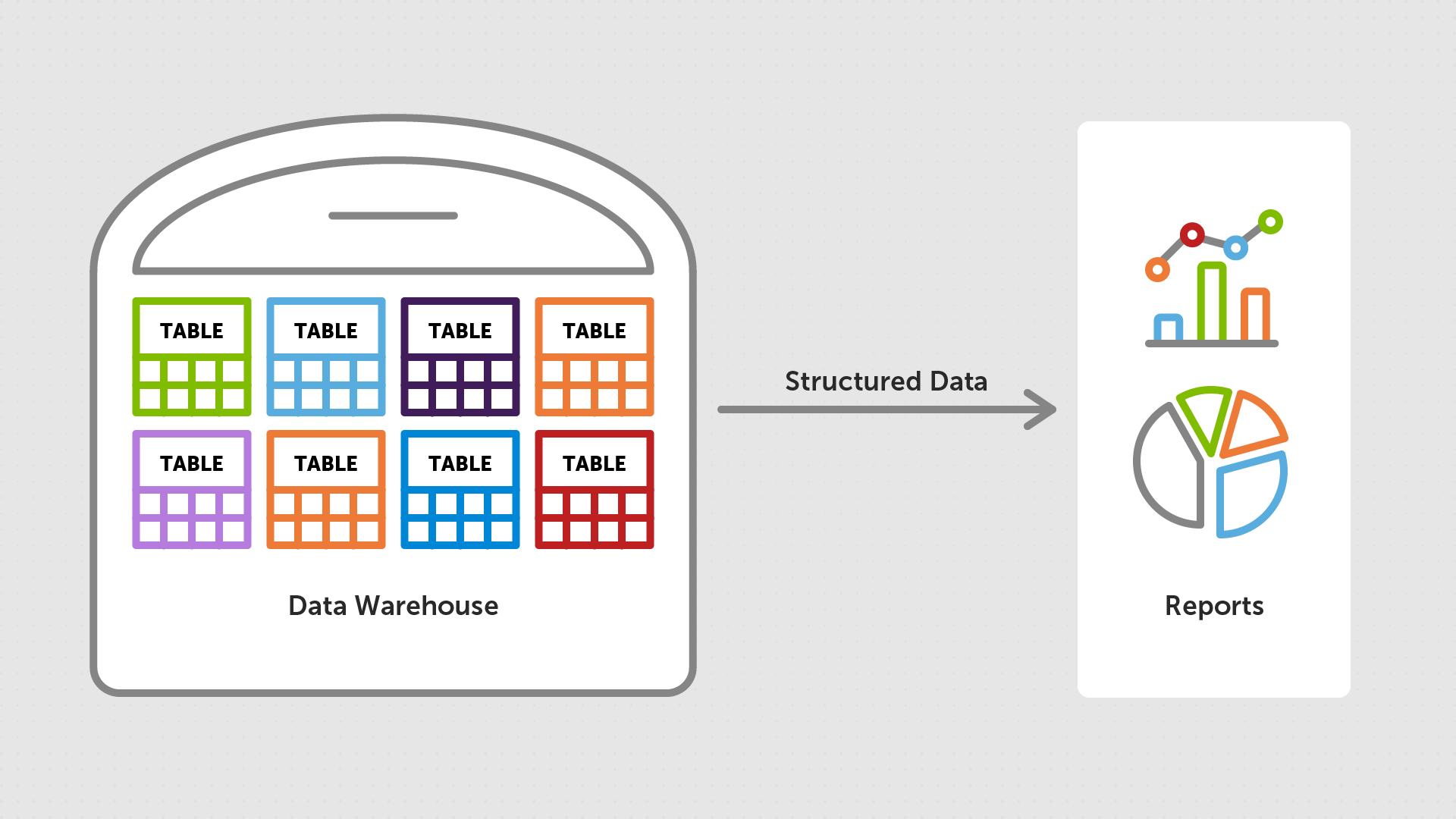
Data Warehouse
Originally, when they first started exploring their data and the value that they could extract from it, many organisations opted for a Data Warehouse architecture. This meant that all of their operational data was moved directly from (often on-premise) live database and stored in a (usually SQL-based) relational format, and queried directly to create reports and extract insights.
Advantages
The main advantages of this architecture were (and are):
- Some level of data consistency is ensured by tables' defined schema
- Reporting queries can be designed to be performant and optimized, leveraging the data's tabular nature - though it is worth noting that denormalizing into star schemas can require a lot of joins (see Barry's post on the subject here!).
- Support for ACID compliant operations
ACID compliance means that the database has the following characteristics:
- Atomicity
Atomicity means that each transaction happens as a single "unit". This means that if you have an action that includes multiple transformations, then either the entire action will succeed, or the whole thing will fail and the database will be completely unchanged. This ensures that your database will never get into a state where, for example in a data copy operation, the data is removed from the original location, but not yet added to the new location.
- Consistency
Consistency means that the tables can only be modified according to well-defined rules. For example, added data must follow the correct schema, or a certain value can't be negative at the end of a transaction.
- Isolation
Isolation means that even if users are concurrently modifying a database, their transactions won't interfere with one another. In practice this often means that even if two things happen concurrently, the database will act as though one of them happened first. One way this is achieved is by temporary locks and queues.
- Durability
Durability means that if a transaction succeeds, its effects will be saved - even in the case of unexpected full system failure.
Disadvantages
However, there were also some major disadvantages to a Data Warehouse:
- The storage and the compute are tightly coupled meaning the architecture is incredibly inflexible
- Data storage is often expensive, meaning that as data volumes increase, storage costs can skyrocket
- It is also often difficult to scale independently - you are forced to scale up compute at the same time as storage, and vice versa.
- You often have to provision for the peak load meaning that you always have to pay for the maximum compute, even when you're not using it
- They're generally unsuitable for storing unstructured data e.g. images, JSON, etc.
- You also generally have to pay for the data warehouse software, which tends to be licensed per CPU, and this can be very expensive
Data Lake
As the world of data started to change, data volumes increased, and unstructured data became the norm, people started to turn to a new storage option: the Data Lake. These are able to cope with the storage of structured, unstructured and semi-structured data - all in the same place! The first widely used data lake was HDFS (Hadoop Distributed File System), but there were soon multiple offerings to choose from (Amazon S3, Azure Data Lake, etc.).
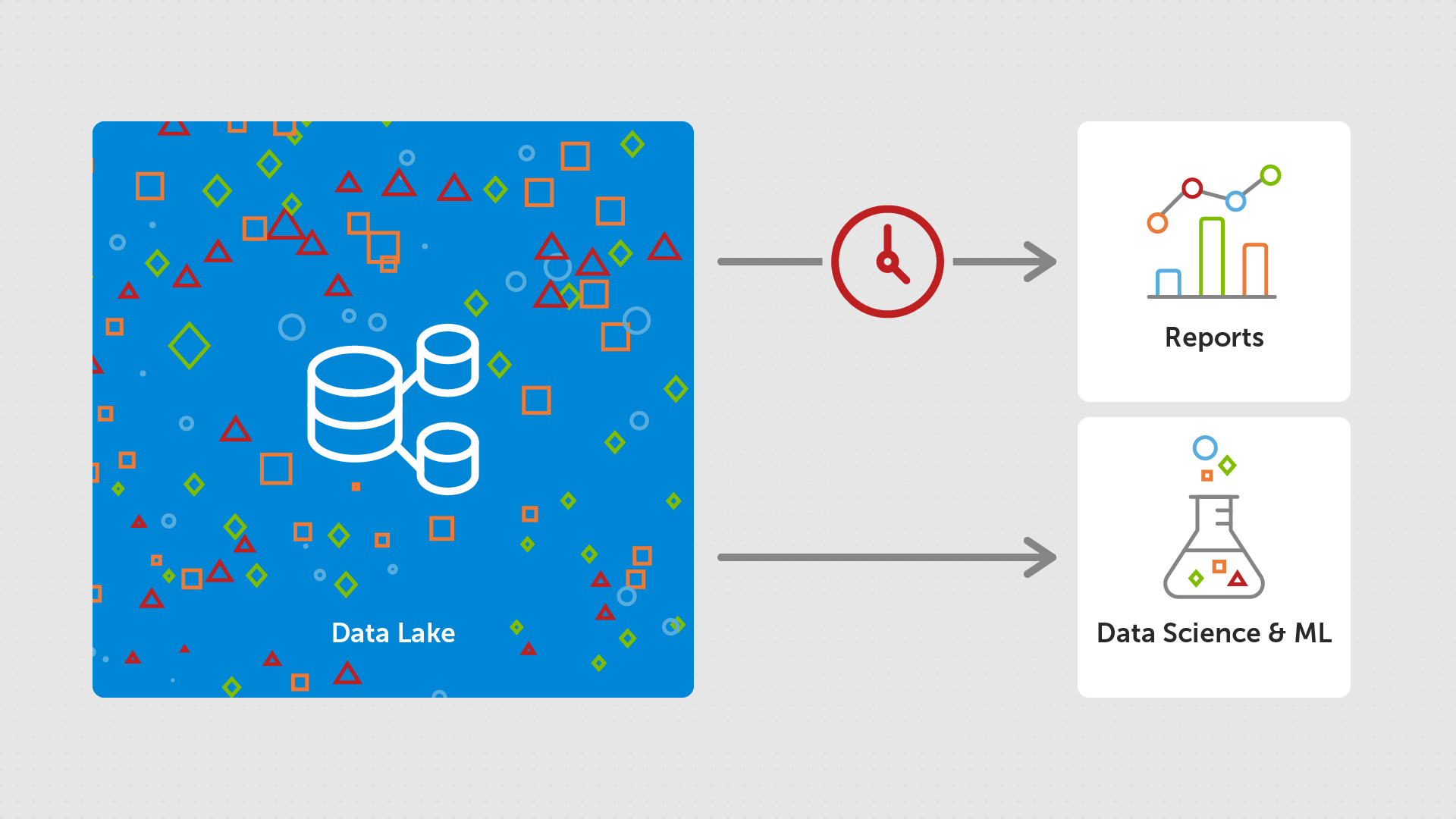
Advantages
Data Lakes are built to allow low cost storage of large volumes of mixed data types.
The storage itself is usually lower cost that a data warehouse. But, additionally, the storage and compute are decoupled. This means that you only pay a "standing charge" for the storage consumed. It means that should your storage needs increase, you don't need to also pay for increased compute power. Likewise if you need more processing power, you don't have to scale storage capacity at the same time.
They also have the advantage of intrinsic support for open file formats (formats that follow a standard specification and can be implemented by anyone, such as parquet), which are commonly used in Machine Learning models and data-science-enabling frameworks (such as Spark).
Data Lakes also support a familiar file-type API, allowing data to be queried like a local file system - with folder structure and a corresponding hierarchy of files.
Disadvantages
Because of the nature of a data lake, and the support for unstructured data, architectures adopt a "schema on read" approach - meaning that the structure of the data isn't defined until the data is read. The implication of this is that there is no built-in way to enforce data integrity or quality. This means that keeping the data consistent presents a huge challenge.
Another issue with Data Lakes is that, though they are great for certain types of querying (ML models, and data science), they aren't optimized for standard Business Intelligence querying (the BI in Power BI!). Many don't intrinsically support SQL-language querying (which is what is used for most business reporting), and those that do can't offer ACID transactions, or meet the performance of a Data Warehouse architecture.

Combined architecture
To combat some of these issues, and support more optimized queries and concurrency, a lot of people adopted an architecture where they would initally ingest the operational data (often from a Data Warehouse) into a Data Lake, where large volumes of data would be stored. This would then be transformed and the resulting projections would be put into a Data Warehouse, which was then used to power the business analytics platforms. This is known as an ELT (extract, load, transform) approach - where you load the data into the system as is, and then transform it to meet your needs.
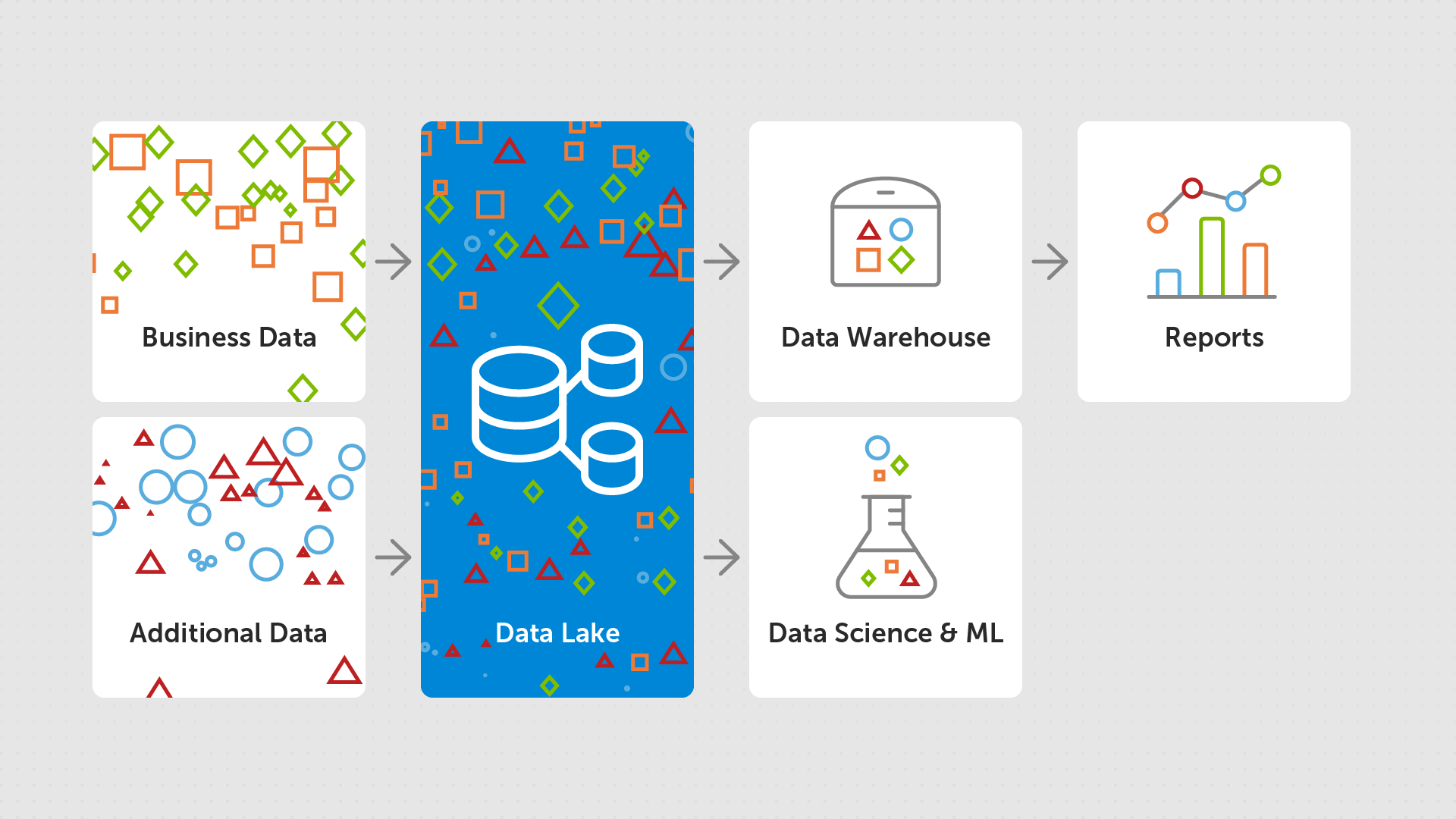
This had the advantage of introducing some level of consistency into the platforms, and achieved the key aim of being able to support business insights in a performant way.
However, it also had its disadvantages:
- The two tier data architecture is complex and meant that there was significant (costly) engineering effort near-constantly involved in keeping the system up-to-date and running smoothly, and a high chance of bug introduction when anything was changed
- It introduced further points of failure into the system, which needed to be monitored and kept healthy
- Keeping the data consistent between the two (and sometimes three) systems is difficult and expensive, and leads to additional data staleness, with the analytics often being carried out over older and out-of-date data
- There is still limited support for data science workloads, with people and organisations needing to choose whether to run this over the Data Warehouse (which is not optimized for these use cases), or over the Data Lake and forgo the data management features (ACID transactions, versioning, indexing)
- Most of your processing time / compute cost is dealing with "data movement"
Data Lakehouse
In response to these challenges, a new architecture began to emerge - the Data Lakehouse. This can be thought of as a combination of a Data Warehouse and a Data Lake (hence "Lakehouse"), where you get low cost support for mixed data types, whilst still being able to access the data management features of a Data Warehouse.
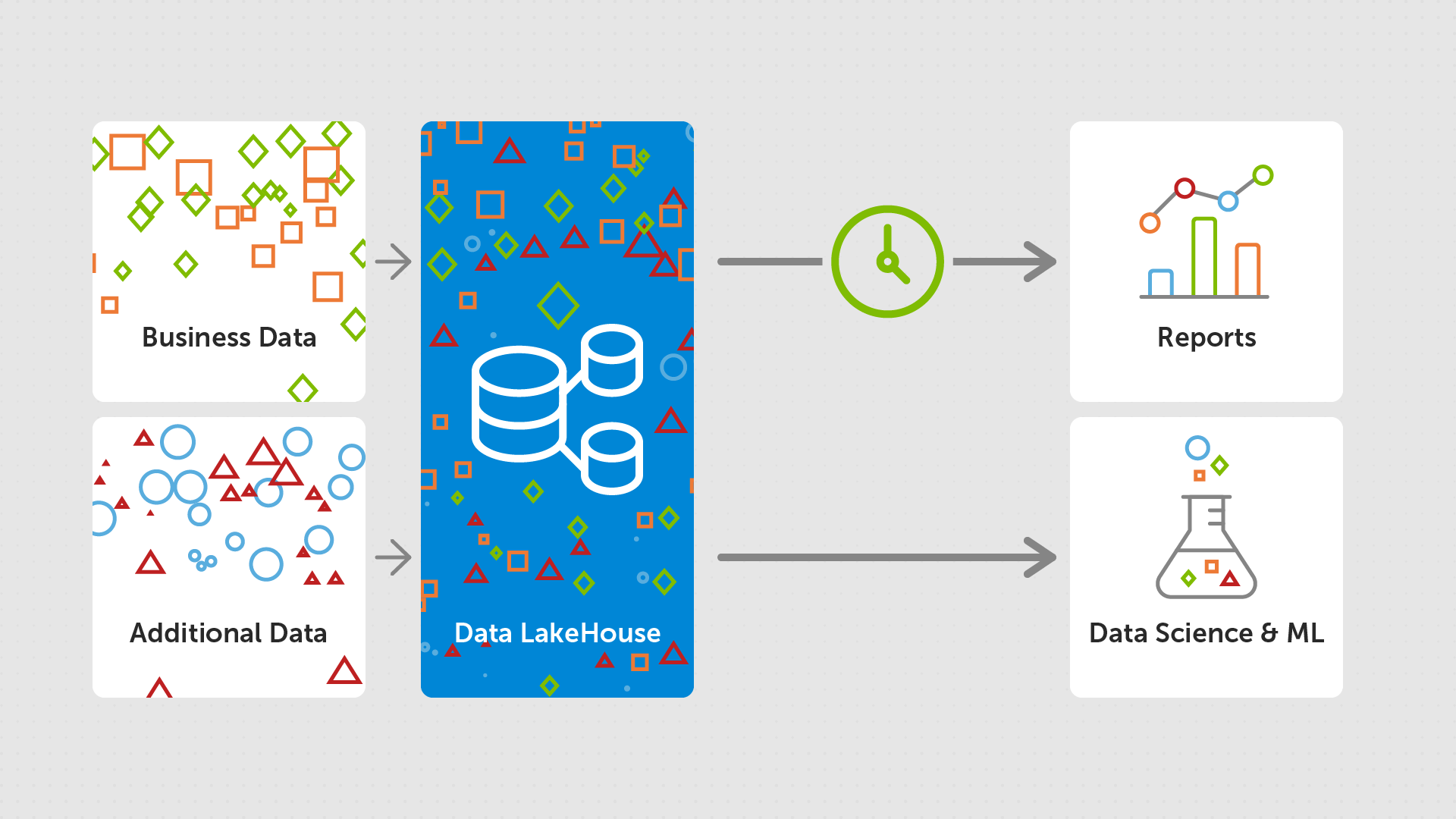
Advantages
At the core of Lakehouses, are the following:
- ACID transactions
- Schema enforcement and governance (including audit and discoverability)
- Business intelligence support directly on the data (to reduce data staleness)
- Scalability (including concurrency)
- Support for open data formats (to support machine learning and data science)
- Support for structured, unstructured and mixed data types
- Support for a variety of workloads (BI, ML, data science)
- Data streaming allowing the processing of real-time data
And, at the core of all of this was the need for these things to be supported without losing the performance capabilities of the classic Data Warehouse approach. And, with the invention of Delta Lake, and other open table formats such as Hudi and Iceberg, this dream is closer than ever (I was fascinated to find out how these work so see my next blog if you too are interested in how this was achieved!).
Microsoft Fabric was announced in May 2023 and provides intrinsic support for Lakehouses - leveraging Delta Lake to support optimized querying for both BI and advanced analytics workloads. Since then, and its General Availability in November 2023, features have been continually added to help users understand new and exciting possibilities for unlocking the power of their data.
What is still needed?
Continuous performance improvements are being made to bring query speed over these mixed data types ever-closer to that of a relational database. But, we are not quite there yet. So, if you do have a relatively small amount of, purely structured, data which is fuelling reporting - a Data Warehouse remains a good storage option.
As with any new idea/architecture, there also is often a big learning curve when thinking about a migration. It can be hard to work out if/how to leverage these new technologies (such as Microsoft Fabric) to best assist your organisational needs.
Microsoft Fabric
An issue that we at endjin have found with Microsoft Fabric specifically is that it re-couples your storage and compute costs. This is not so much an issue with the technology, but more with the commercial model that Microsoft have applied. We hope to see future support for a serverless "pay for what you use" compute model as these offerings progress. This would allow small-and-medium business and enterprise organisations to have a risk-free jumping off point for exploration.
Additionally, Microsoft Fabric is also relatively new, which means that users may find some of the tooling they are used to is not quite ready for general use (a good example of this is the Git integration support - a subject of a future blog post!). However, the team at Microsoft is working hard, and listening to user feedback, to continually improve the functionality. And, even though there are some limitations, there is already more than enough features to begin exploring the possibilities that it unlocks!
Here at endjin we were lucky enough to be involved in the private preview of Microsoft Fabric, and we have a long history of being on the forefront of data architectural thinking. If you are interested in setting up a session with us to see if this is something that you might be able to leverage for you data needs, why not drop us an email at hello@endjin.com?




