How do Data Lakehouses Work? An Intro to Delta Lake


In my last blog I ran through what a data lakehouse is and how they came to be. In this blog, I will dig more into the technology and innovation that drives the wider adoption of this architectural pattern.
The idea of a data lakehouses has been around for some time, but was faced with performance challenges that largely limited its wider adoption. However, with new technologies - such as Delta Lake, Iceberg, Hudi, and other open table formats - there have been huge improvements that have allowed the wider community to start leveraging this exciting technology.
One of the main aims of data lakehouses is to be able to support both:
- Business analytics reporting, and
- Data science / machine learning workloads
in a performant way.

One of the issues that data lakes have always faced is that the data that is needed to support analytics can often be spread across multiple files, in different formats, which can be hard to manage when faced with complex querying logic. In a relational database, it is relatively straighforward to join information across tables, but this is less true when you are storing large volumes of mixed (structured, semi-structured and unstructured) data. This meant that data lakehouses, when supporting SQL-like querying, face huge performance challenges when compared to a relational database.
ACID transactions are also a challenge, as if multiple files need to be accessed and modified as part of an operation, you need to set up complex locking systems. Ideally, we often want to treat this non-relational data as though it is relational, whilst still being able to support performant querying.
What is an Open Table Format?
To combat these challenges, open table formats such as Delta Lake were developed to provide a metadata layer between the data itself and whatever query engine you choose to use:
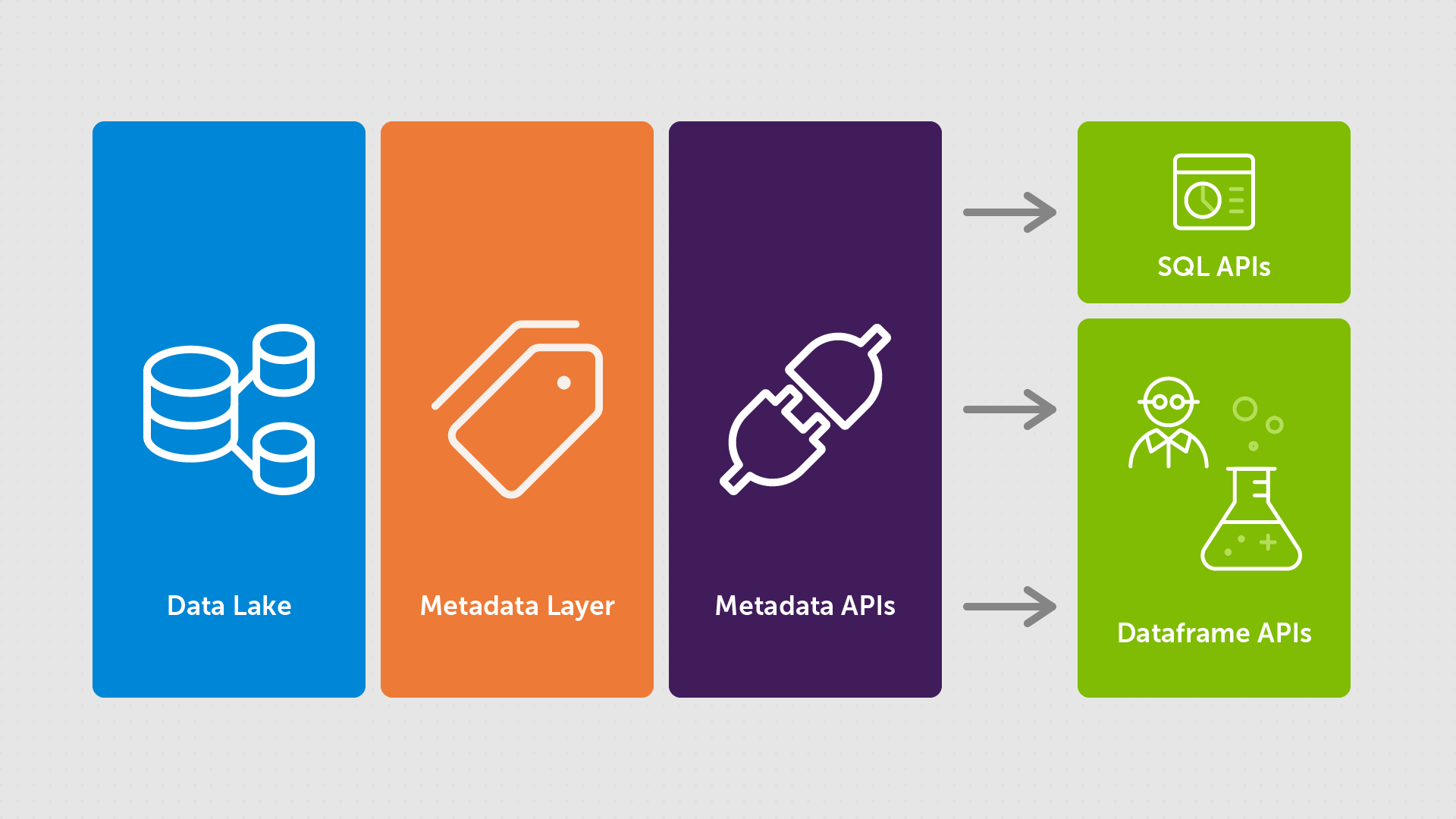
You can see here that the metadata layer and APIs sit between the storage and the query APIs. This layer is used to define and optimize how the data access is managed. This allows them to:
- Implement ACID transactions as you can easily tag and group files which need to be changed together.
- Apply schema validation and performance (rejecting data that does not match a set of rules) which improves data consistency within the system.
- Implement data versioning, creating a repeatable audit trail.
- Enable stream and batch processing.
- Provide more performant querying over mixed data.
Delta lake collects this metadata automatically when you write to a table and, in this way, lakehouses can support well-managed and performant querying using the SQL-like business analytics APIs.
These open file formats additionally enable us to better support optimizations for the declarative APIs that are used for data science and machine learning workloads (such as Spark). These declarative APIs are different from classical imperative APIs, that just provide a list of commands that the system will execute. Instead, we provide a state that we want the system to create, and are not concerned about the steps involved in achieving that state. For example - "I want to combine these two datasets, within this range, by matching these values, and removing any records for which a certain statement is true". In this case, the optimization layer is able to decide how best to execute this query in a performant way.
How does Delta Lake improve performance?
These performance enhancements are achieved using multiple techniques, including:
Indexing
Enabling indexing of the data can have a huge impact on performance as it allows the building of a data structure which supports faster access. In Delta Lake, this means creating a reference table which allows lookup of data based on specific columns. This more targeted approach to data retrieval has huge performance benefits compared to the "table scan" approach often used in data lakes - especially when talking about large data volumes.
Caching
Another way in which the performance is improved is via caching. In Delta Lake, for example, data is cached on disk by the metadata layer, which greatly speeds up read access. Accessed files are automatically placed in the storage of the local processing node, and copies are made of any files that are retrieved from a remote location. It also automatically monitors for changes, meaning that file consistency can still be maintained across the copies.

Auxiliary Data
Alongside the caching of the data itself, additional (supplementary) data is often used to speed up data access. For example, if you store statistics about the range of a certain column, when data within a certain range needs to be accessed (e.g. a date range, or payments above a certain value), then that data can be quickly located.
It also can allow for the skipping of large amounts of data if values are known to not be present. For example, if you are performing a merge on values equal to 1-10, and you store metadata about the range in each file, then you can discount entire files that fall outside this range without needing to do any processing.
Intentional Data Layout
The physical location of data within your storage can have a huge impact on performance. In most cases, you will have regularly access "hot" data, and then that which is "cold" (less frequently accessed). Open table formats increase performance by grouping these together. Beyond that, they also group data that is regularly accessed at the same time, including across multiple dimensions.
Additional configuration
A lot of the metadata is collected automatically when you write out to Delta Lake. However, it is configurable should you choose. A good example of this is the defining of specific Z-ordering for columns. This is useful if you have data that is often grouped by more than one column (e.g. by age and by gender) so smarter grouping is needed to support performant querying.
Additionally, there are account-wide settings such as predictive optimization for Unity Catalog managed tables, which means that instead of just collecting statistics for the first 32 columns in your schema, these statistics will be collected more intelligently.
In Summary
Delta Lake and other open table formats provide a powerful metadata layer that sits between your storage and query APIs, and unlock a huge breadth of management functionality and performance improvements when compared to a traditional Data Lake (even when just using the out-of-the-box functionality). The latest performance improvements have allowed a greater uptake of lakehouses in general, and brought this architectural pattern to a point that it is being adopted throughout many data-driven organisations.
This exciting step towards unified data strategy is one that we have long awaited here at endjin, and if you want to talk to us about how these new ideas and technology can help you, why not drop us an email at hello@endjin.com?




