Data is a socio-technical endeavour


TLDR; this blog highlights some of the ingredients required to create a high performance data team; based on our experience "helping small teams achieve big things"!
At endjin we get an opportunity to work with a diverse range of clients, from charities to large corporations, from small startups to global brands. We strongly believe that the effectiveness of the team responsible for delivering a data & analytics initiative is the single most important factor in the overall success, therefore we like to say:
Data is a socio-technical endeavour.
In other words you have to master the cultural, organisational and human aspects as well as the technology in order to be successful.
The five traits of a high performance data team
The simple model illustrated below fits any data initiative.
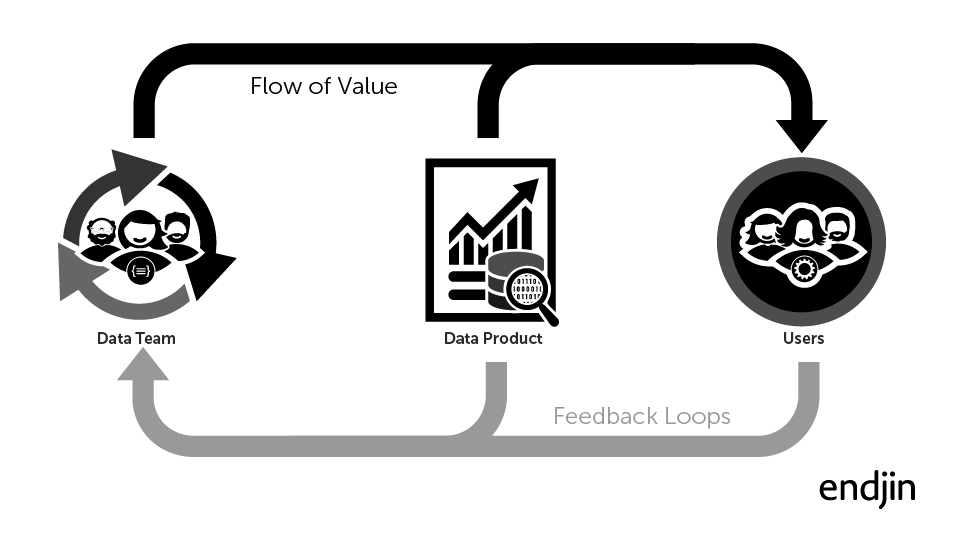

The data team on the left, who create a "data product" to meet the needs of users on the right.
Value flows from left to right.
Also important are the feedback loops that enable the data team to evolve the data product in response to the evolving needs of users.
There's often a lot of uncertainty, especially if you're doing cutting edge, innovative, transformational data products where things are likely to be under constant evolution.
Where the flow of value or the feedback loop breaks down, significant issues will occur.
High performance data teams are highly aware that they are operating within a social-technical system. We have identified five traits that enable high performance data teams to create and sustain a productive socio-technical system:
- Open culture
- Product mindset
- Small and multi-disciplinary
- Engineering maturity
- Wider organisational readiness
We now explore each of these in turn.
Create an open culture
The first trait is an open culture that is founded on:
- Looking outward - they understand that they are part of a wider organisation, the role they play in helping that organisation to achieve its goals and the flow of value that they can facilitate. They are in tune with the shifting needs of the wider organisation, and are able to adapt (and lead others in adapting) to meet those shifting needs.
- Self awareness - there is no such thing as a perfect team, but good teams are "self aware". They are honest about their weaknesses and where they could improve.
- Continuous improvement - teams are always a work in progress, they are self organising with a focus on constant improvement. They set aside time to incrementally work towards achieving perfection, recognising that perfection is a moving target that they will never achieve thanks to the constantly changing environment in which they operate.
- Productive partnerships - teams don't live in isolation. They need to interact with other teams in order to succeed. They recognise the value in forming productive working partnerships with other teams both internally and externally.
Product mindset
The second trait of a high performance data team is that they adopt a product mindset.
A product mindset (as opposed to a project mindset) means that the team are focused on the delivery of long term sustainable value to the organisation. In doing so they seek to Discover, Build and Own data products through their entire lifecycle.
Their goal is to operate as a value centre rather than a cost centre. In other words actively engaging with stakeholders, seeking out opportunities to digitally transform the organisation using data, as opposed to operating as an "order taker", waiting to get work allocated to them.
Use of the term product also reinforces the principle that investments in data & analytics should stand on their own when it comes to a return on investment. Therefore the lifetime value generated by the "data product" needs to exceed the total cost of ownership (TCO) that it will incur over its lifetime.
Data products are not cheap to design, build, operate and maintain. Once the product is created it will need to be sustained over its lifetime, incurring costs over many years. So unless there is a compelling value proposition to be delivered, you should avoid committing to that product.
This concept of lifetime value versus TCO is illustrated below:
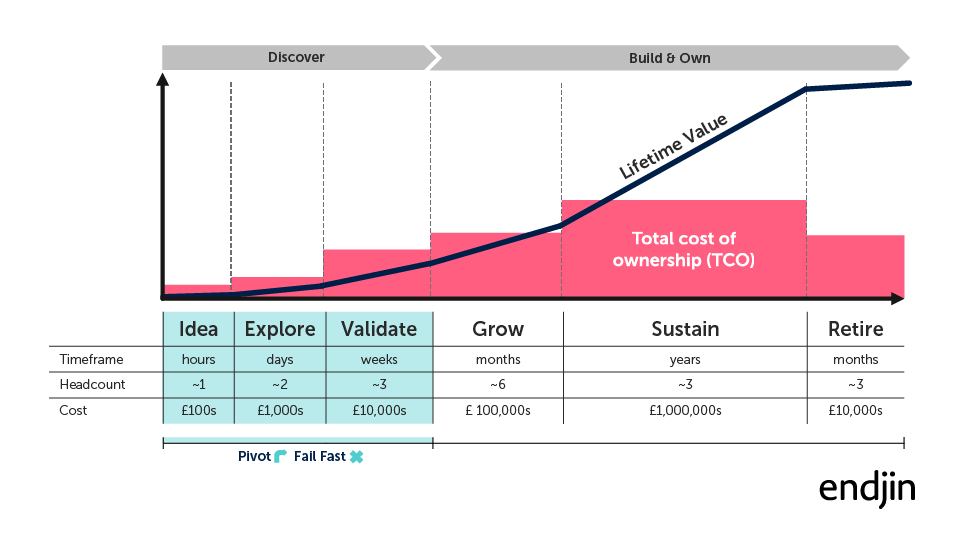
High performance data teams become skilled at identifying the data products that are high value and can carry the multi-generational TCO required to sustain them. They are comfortable challenging stakeholders about the overall commercial viability of any proposed investment, encouraging them to "fail fast" or "pivot" accordingly, avoiding "vanity projects" and the sunk cost fallacy.
In effect they are operating as an innovation engine, helping the organisation to cycle through ideas rapidly to discover the data products that will have a genuine transformational impact. This capability alone represents significant value to the organisation.
You will notice that we use the term "data product" throughout this blog, this is to reinforce product thinking. It is also one of the four principles of the Data Mesh architecture that is gaining a lot of attention in the data industry. High performance teams are able to reconcile the competing demands of de-centralisation, governance and discoverability to identify the sweet spot that will work best for their specific use case.
Operate as a small multi-disciplinary team
The third trait is that high performance data teams tend to operate autonomously as a small and multi-disciplinary team.
Let's tackle each of these in turn!
Small
The magic number is no more than 9. You may have heard Amazon's "two pizza team" principle, which is backed up by academic research, most famously by anthropologist Robin Dunbar.
A small team enables a flat structure and for the team to be self-organizing.
They operate in an environment where they are empowered to get things done and adopt agile practices. This means that there are no hand offs with other teams. Although they may rely on the skills, platforms or services provided by other centralised teams or external organisations from time to time.
This means that they can focus the majority of their effort on the delivery of value.
Multi-disciplinary
By multi-disciplinary we mean the team possess all of the skills necessary to discover, build and own data products through their end to end lifecycle. They embody the mantra "you build it, you own it".
So what are those skills? Much of the advice on the web about building data teams will list a "cast of stars" with roles such as:
- Data scientist
- Data engineer
- Business Intelligence Analyst
- Machine Learning Operations (MLOps) Engineer
- Business Analyst
There is no doubt that you may need some of these skills. But the fundamental problem with filling your team with specialists is that you are at risk of creating silos within the team, and triggering the negative aspects of Conway's law.
These articles also forget that you will need a much broader set of skills and disciplines to launch a production grade data product. Such as the "ops" side of DataOps or other value enhancing skills in areas such as UX design, software engineering and domain knowledge.
With a small team you can't afford to have people that are narrow technical specialists. You need much broader skills, and for the skills across the team to overlap. You want people to be able to wear multiple hats, that are motivated by the team's success, who are interested in the business domain you operate in, are inquisitive and are willing to constantly learn.
We like to say:
Hire for attitude over aptitude.
Look for talented generalists who possess a broader set of skills, enabling them to be more effective overall. We find the following attributes are important to look for when hiring:
- Inquisitiveness - people who want to understand the problem they are seeking to solve.
- Life long learning - individuals who are prepared to pick up new skills and are comfortable with continuous improvement.
- Cognitive diversity - look for people who think differently as a means of building diversity in the team.
This makes recruitment more focused on personal attributes that are less likely to jump out of a CV, requiring other techniques to assess candidates - we recommend activities such as "pair problem solving" exercises as a means of gaining a deeper insight into these attributes.
We illustrate the "attitude over aptitude" principle in the illustration below:

In many cases, we have seen clients succeed by choosing to develop existing "in house" talent rather than hire new people to build their data team. The most successful examples involve supporting domain experts to step into a new data orientated role through training, mentoring and pairing them up with more experienced colleagues. We often find that the domain expertise they bring is more valuable than any technical skills they may initially lack.
Fundamentally, you don't need to hire stars, with a vision and a bit of patience you can grow your own talent.
Should a data team be de-centralised or centralised?
In organisations which are just beginning their data journey, data teams tend to start as a central team, operating as a "centre for enablement" for the wider organisation. Their goal is to operate as an enabling team engaging with stakeholders who are interested in delivering "value from data". They apply their product mindset taking stakeholders through the Discover stage of the product lifecycle illustrated above to help them identify data products that are worthy of being taken into the Build & Own phase. They then take the first few data products into production, helping the wider organisation to see the value opportunity from becoming more data driven.
If a "centre of enablement" team is able to second a domain expert into the team to help them explore, validate and grow a specific data product idea, they drastically increase the chances of success. This is often not easy to do, because it means back-filling key resources. But there are many upsides: not least career development opportunities for the individuals who are seconded in this way. They are able to pick up valuable data skills that they can take back into their substantive role along with the data product they have been instrumental in developing. This helps with the mission of embedding and sustaining "value from data" across the organisation.
As the organisation progresses further in their data journey, they see the value of embedding data skills within specific departments across the business. The small multi-disciplinary nature of the team, coupled with a product mindset, is perfectly suited to this model. Here the data team is de-centralised working within a specific business unit or department, they are "close to the point of application" and can build a deeper understanding of the business domain they are aligned to and the users who their "data product" will impact. This enables them to be more aligned to a single data product that will require significant ongoing investment during the Build & Own phase, or to create a suite of small data products aligned to a specific domain.
Focus on engineering maturity
The fourth trait is engineering maturity. High performance data teams embrace the principles, processes and tools that mainstream engineering teams use.
This is to achieve a single objective:
rapid and safe delivery of value
By rapid we mean taking humans out of the loop through automation and adopting tools that boost productivity.
By safe, we mean removing risk and reducing costs.
The team are aiming to build, test and release new features in a repeatable, reliable, autonomous manner with a high degree of confidence and with little or no ceremony. In software engineering the term for the capabilities is DevOps. In data projects, the application of DevOps practices is known as DataOps.
This DataOps infinite loop is illustrated below with specific activities that are performed at each stage in the loop called out:
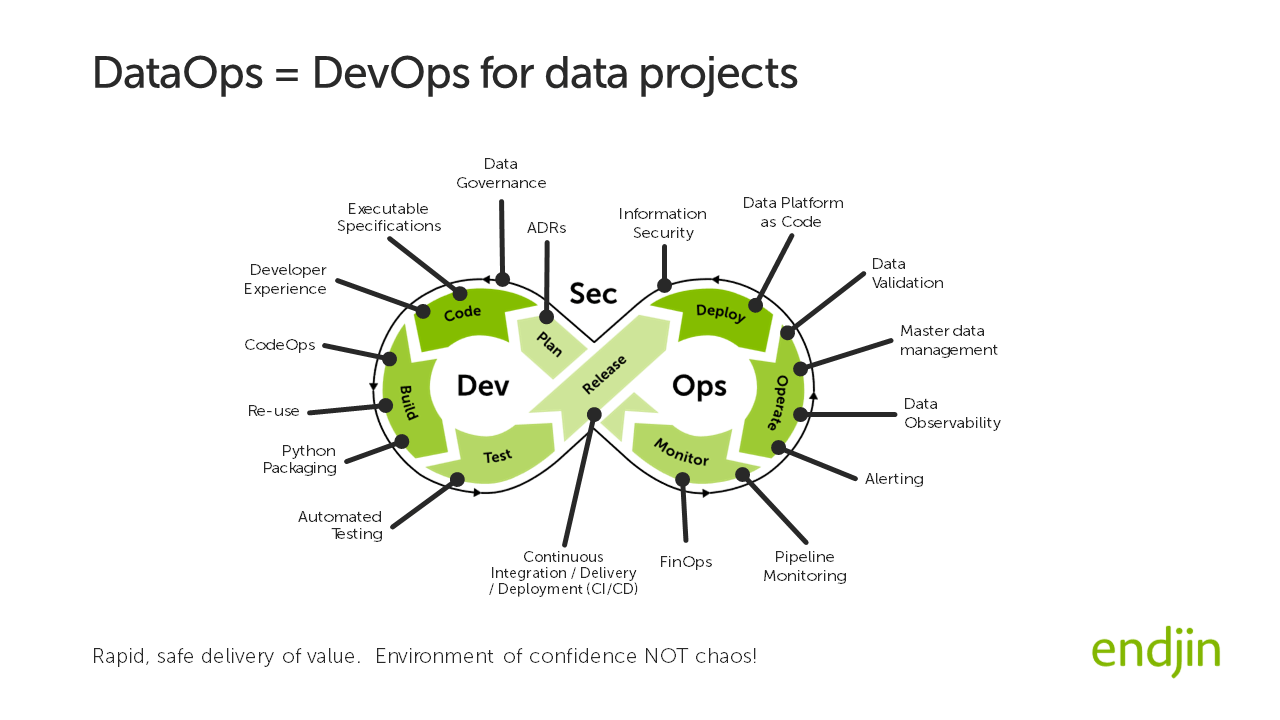
The data tech landscape has matured significantly in the last 5 years. Cloud native platforms such as Azure Synapse Analytics and Microsoft Fabric now provide all of the capabilities you need adopt good engineering practice. In effect, if a team are using modern cloud native data infrastructure, there are no excuses for not having robust engineering practices in place.
Building on the continuous improvement and self awareness themes above, high performance data teams recognise that engineering maturity is a critical capability. They proactively set aside capacity to research, trial and apply the appropriate tools, technologies and methods that will improve the flow of value and minimise TCO. They are well placed to do this because they are responsible for all stages of that the data product value chain and are therefore empowered to apply continuous improvements and will benefit directly from the improvements that they make.
We would recommend an early hire for your data team should be an experienced software engineer who can fast track bringing software engineering practices to the team such as introduction of behavior driven testing (BDD), continuous integration / continuous deployment (CI/CD), infrastructure as code (IaC) and practices such as the use of architectural decision records (ADRs).
Operate in an organisation that is ready to adopt data products
The final trait we wanted to talk about is the readiness of the wider organisation to adopt data products.
Data teams don't exist in isolation. They need to interact with and influence other parts of the organisation to succeed. There are three key areas where data teams engage with the wider organisation:
- Technology peers
- End users
- Leadership
This is illustrated below:

Technology peers
High performance teams establish productive partnerships with their technology peers. These teams are often the "ops" part of DevOps (or DataOps) cycle above. They provide important operational infrastructure, tools and skills in areas such as networking, security and build / test / deployment automation.
These relationships are shaped so that interactions don't inhibit the flow of value. This is typically achieved by encouraging other teams to interact either as an:
- Enabling team – engaging for a short period to bring in specialist expertise that the team needs to unblock a specific impediment; or as a
- Platform team – by providing well documented IP, platforms or services that can be consumed through an API or command line script.
In many organisations it is likely that some of these technology peers will be external parties. This does not prevent a positive relationship to be built, we found that adopting the "enabling" or "platform" team models above are key to making this work.
End users
High performance data teams build a strong relationship with end users of their data product. This is critical to establishing feedback loops, to build empathy and understand their evolving needs.
This can sometimes be a difficult undertaking. End users can be demanding and the feedback they provide can be difficult to take if you are not meeting their needs. Our view is that there is no such thing as bad feedback, the strongest relationships can often be forged from a difficult beginning, in particular where you are prepared to listen and address the feedback in a constructive manner.
In other cases, it can be challenging to get key users to engage consistently, so they are providing frequent constructive input to the team in areas such as describing requirements, backlog refinement and prioritisation, testing and retrospectives. We would recommend establishing that commitment up front (hours per week, speed of response etc.) and be prepared to pause the work if that commitment is not forthcoming.
Key to building a productive relationship with end users is being able to establish a common language. For example, one organisation we worked with had 20 different definitions of Gross Margin. Until we helped the data team to resolve this, it was difficult for them to understand end user needs and to move on to develop the data product.
Leadership
Another common issue we have with users is mis-aligned incentives that can act as a resistance to adoption. To quote Upton Sinclair "It is difficult to get a person to understand something, when their salary depends upon them not understanding it."
This is where the relationship between the data team and the leadership of the organisation becomes important in order to make the necessary operating model changes that are required to overcome resistance.
High performance data teams are also able to influence upwards. Challenging the status quo, encouraging leadership to embrace data opportunities, helping them to understand how they can achieve their goals by integrating data into the wider strategy of the organisation.
High performing data teams have sponsorship from at least one executive who:
- Are committed to their long term success - they understand "value from data" and are able to secure the long term commitment, resources and funding required to make it a reality.
- Lead by example - they are early adopters of new data products. They act as evangelists for the work the data team is doing, driving adoption and momentum behind the work the team is doing.
- Provide "air cover" - they are on hand to help push through any organisational barriers that may arise. They act as an "adult in the room" who can quickly identify and overcome these barriers. Inertia is to be expected with any transformational change.
Summing up
In summary - data is a socio-technical affair. Have you mapped out how value flows in your organisation? Are there opportunities to optimise it?
Do you have feedback loops in place? What are they telling you?
Measure your data team against the traits we describe above:
| Trait | Positive Signals | Negative Signals |
|---|---|---|
| 1 - Open Culture | Are you a self organising team that proactively makes space for continuous improvement? | Are you a team that seems to have stagnated and is losing touch with new technologies? |
| 2 - Product Mindset | Do you act as an innovation engine helping the organisation to discover high value data products? Are you prepared to fail fast when ideas are not viable? | Are you weighed down by and endless stream of projects that take an age to deliver and don't seem to have any impact? |
| 3 - Small Multi-disciplinary Team | Are you a "small team" that is empowered with all of the skills and tools needed to autonomously discover, build and own data products? | Are you often blocked by other teams in the organisation who prevent you from getting things done? |
| 4 - Engineering Maturity | Are you able to deliver data products in a rapid and safe way? | Are releases weeks in the planning and fraught with problems? |
| 5 - Organisation Readiness | Are you working in harmony with the wider organisation to deliver value from data? | Do you feel under-valued and out of touch with the direction that the organisation is going in? |
We'd love to hear from you if you feel you'd benefit from a conversation about "helping your small team achieve big things"!



