Azure Synapse Analytics vs Microsoft Fabric: side-by-side comparison


In May 2023, Microsoft announced Microsoft Fabric. It extends the promise of Azure Synapse Analytics integration to all analytics workloads from the data engineer to the business knowledge worker. It brings together Power BI, Data Factory, and the Data Lake, on a new generation of the Synapse data infrastructure. Delivered as a unified SaaS offering, it aims to reduce cost and time to value, while enabling new "citizen data science" capabilities. See Ed Freeman's Introduction To Microsoft Fabric for more background.
The following animation loop illustrates how Microsoft Fabric is changing the data and analytics landscape:
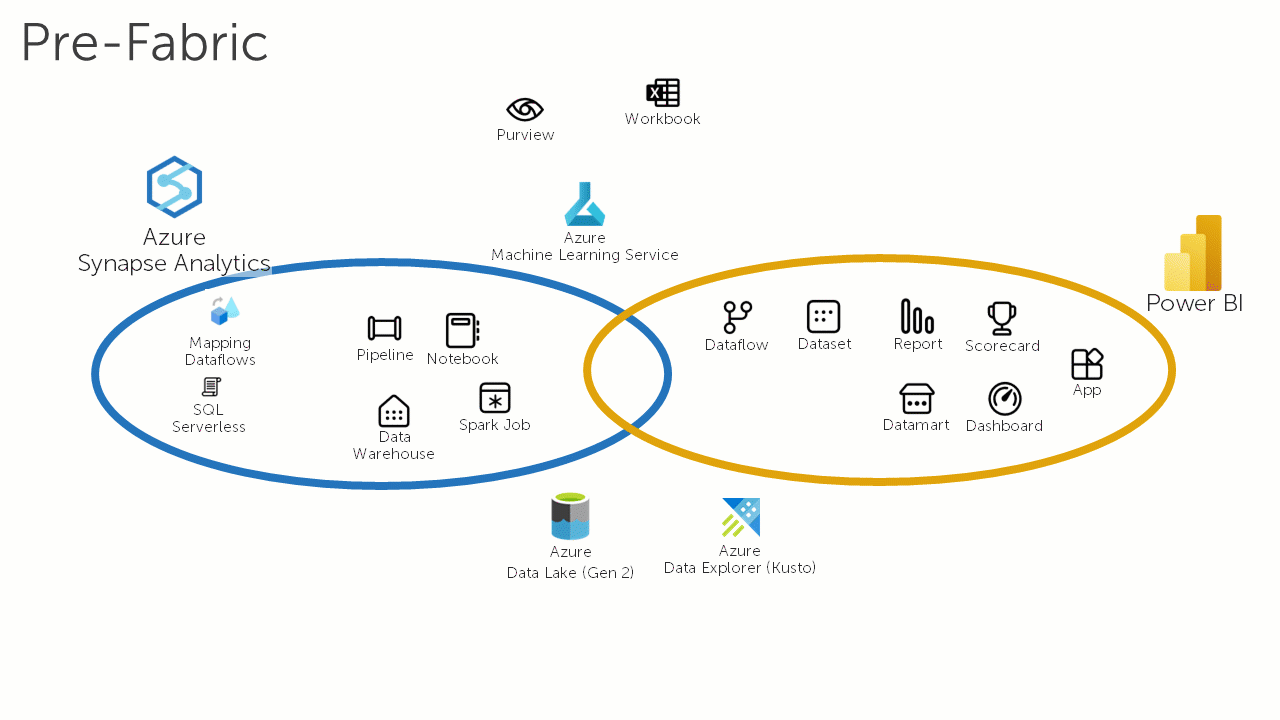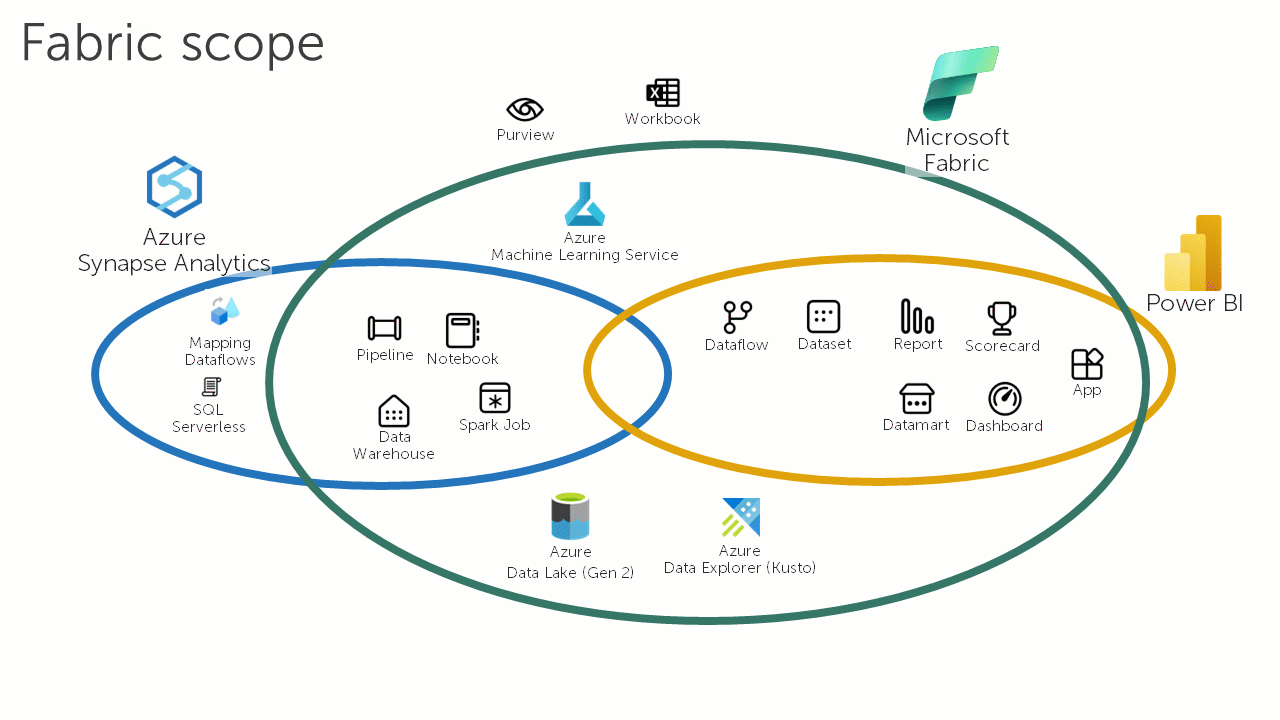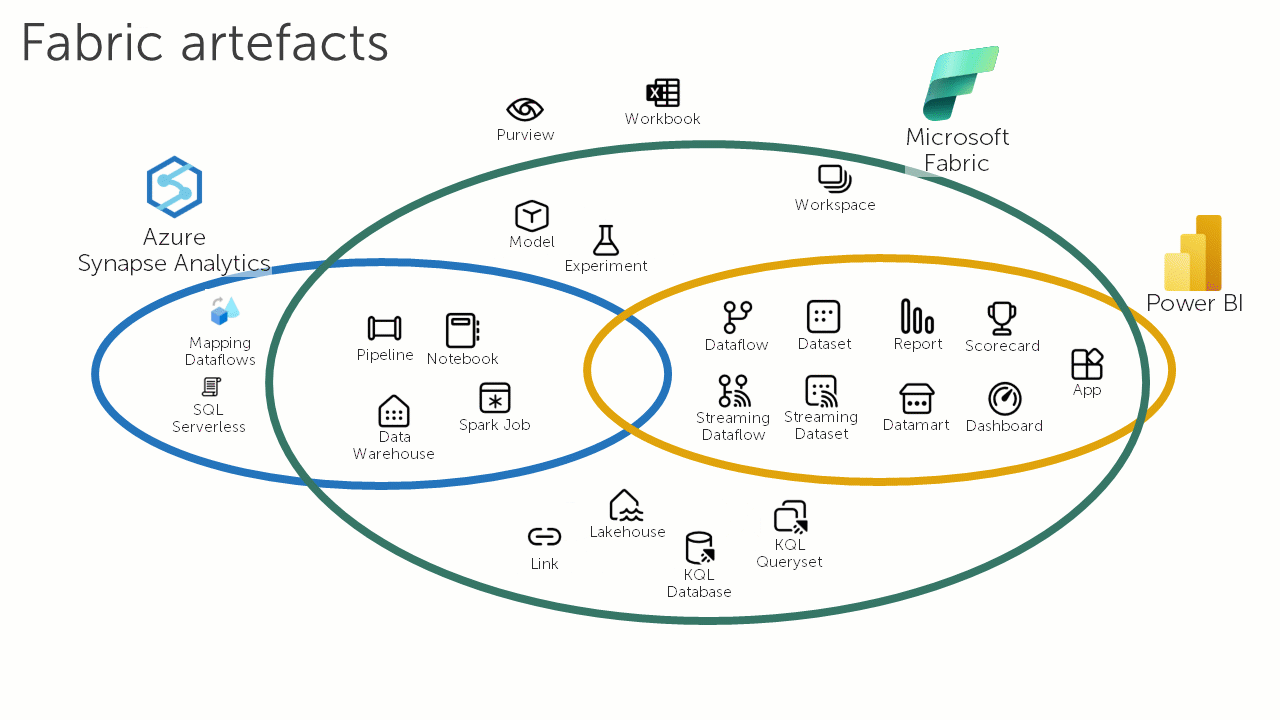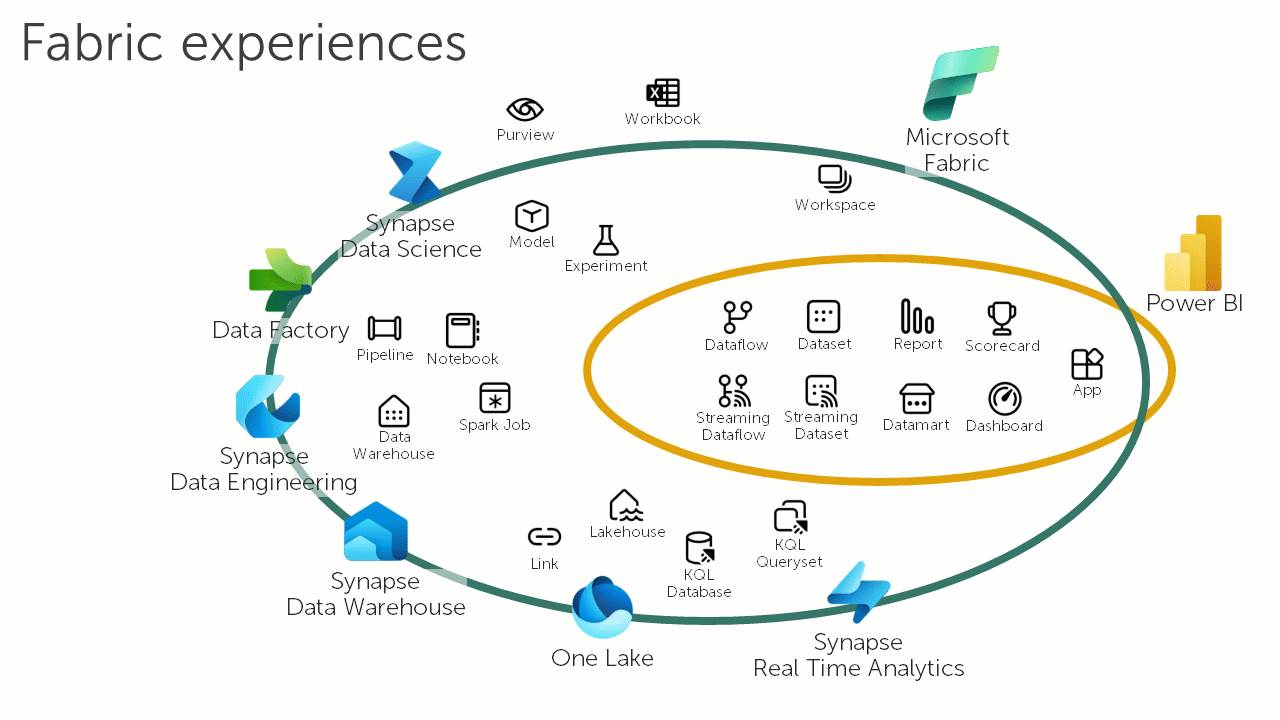
Microsoft Fabric is the natural successor to Azure Synapse Analytics. However, organisations that have made a significant commitment to Azure Synapse Analytics may be disappointed to find that there is no automatic upgrade path for their workloads. Depending on the workload, different degrees of effort will be required to adapt them to run on Microsoft Fabric. For some organisations the costs associated with this migration effort (and the inherent risks in any migration) may act as a barrier.
The objective of this blog is to help organisations with existing Azure Synapse Analytics workloads understand how they could deploy equivalent workloads on Fabric. The blog has two goals, firstly to help people who are familiar with Azure Synapse Analytics to gain an understanding of Fabric through a "Synapse lens" and secondly to assess the cost / benefit of migrating from Synapse to Fabric. A "Synapse centric" approach is taken by stepping through each of the key features in Synapse describing how those features map onto equivalent functionality in Fabric, highlighting key differences along the way. We then provide a set of observations - where there is quite a lot to consider!

It is fascinating to see this "arms race" unfold between the mega vendors (Microsoft, Google) as well as number of niche vendors (Databricks, Snowflake). All are making significant continuous investments as they compete for market share. As these data & analytics vendors strive to develop next generation data & analytics capabilities, Microsoft are in a strong position because they can exploit their dominance in two key areas: Microsoft 365 and Power BI. Microsoft Fabric is seeking to drive home this advantage by integrating and augmenting the functionality we have grown to love in Synapse and Power BI to address new requirements including democratisation of data & analytics and decentralised domain driven ownership of "data products" by providing a self service platform.
However, they need to be careful that the "quantum leap" they are making with Fabric does not leave behind organisations that have already made significant "bets" on Azure Synapse Analytics, and before that, Azure Data Lake Analytics. Whilst the significant investment that has been made by Microsoft in Fabric introduces some impressive new features, these organisations may choose to evaluate Fabric, but wait to see how the platform is received by the wider market and how Microsoft's competitors respond before making a firm commitment to it.
TLDR; the majority of the features in Synapse map directly to similar functionality in Microsoft Fabric. However, even though Fabric is an evolution of the Synapse vision, there's isn't a direct or automatic upgrade path, and so you need to consider it as a migration. Workloads that are Spark based present a more straightforward migration path than those that are SQL based. There are also a number of significant gaps where features in Synapse are not carried through into Fabric (see below). This makes the decision a complex one. We recommend that organisations invest in a "technical spike" to evaluate how Fabric would support their most common Synapse workloads and to provide valuable insights into the migration challenges and longer term opportunities presented by the platform.
Synapse Feature Comparison
The following table provides a mapping for each Synapse feature:
| Existing Synapse Feature | Fabric Feature | Differences |
|---|---|---|
| SQL Serverless | SQL Endpoint | OPENROWSET syntax not supported, this means that SQL cannot be used to query over files in the lake. However structured data placed in “Tables” area of lake will enable that data to be queried via SQL in the “Default Warehouse”, so this provides similar functionality to OPENROWSET. |
| SQL Dedicated (SQL Data Warehouse) | Warehouse | Warehouse data is now persisted in OneLake . |
| Apache Spark Pools | Managed Spark Pools | Fabric is SaaS so there is no need to create and manage Spark pools. It will be possible to choose which version of Spark environment you wish to use and to load specific Python packages into your environment, including an option to do this dynamically within a Notebook. Performance improvements mean that underlying Spark environment “spins up” in seconds rather minutes. |
| Apache Spark Notebooks | Notebook | A number of new features have been added: comments – ability to add comments to Notebooks similar to Word; co-editing – multiple users can open and edit a Notebook simultaneously; data wrangler – new utilities are available in Notebooks to enable data to be explored. |
| Apache Spark Jobs | Spark Job Definition | |
| Data Explorer (KQL Scripts) | KQL Queryset | |
| Data Explorer Database | KQL Database | |
| Synapse Link | Not yet available in Fabric. | Synapse link is not currently available on Fabric. Hopefully we will see this at some point in the future. |
| Synapse Studio | Replaced by new Power BI based interface. | Workspaces are used to organise assets and to drive some aspects of security. User experience is now organised around specific personas “Data Engineering”, “Data Science”, “Data Warehousing” and “Real-time Analytics”, then you still have Power BI, Data Factory and Reflex as stand alone tools. |
| Git Integration | Git Integration | Fabric supports Git integration in a similar manner to Synapse allowing a Fabric Workspace to be synchronised with a Git workspace. However there are significant improvements due to the way that artefacts such as Notebooks are captured in source control because they will adapt their native file format rather than the proprietary JSON format adopted by Synapse. The adoption of the native syntax makes it significantly easier to track and review changes. |
| ML / MLOps | Data Science | Models can be registered and experiments tracked using a native MLFlow endpoint provided by Fabric. To do this in Synapse would require creating an instance of Azure Machine Learning and integrating this with your Synapse environment. The core work to clean, prepare, featurize, train and evaluate model is still performed in Notebooks on the Spark platform using open source libraries such as SynapseML providing continuity with notebooks which have been developed on the Synapse platform. |
| Mapping Data Flows | Not supported by Fabric. | Mapping Data Flows is the “no code / low code” graphical user interface that can be used to transform data in Synapse. This is not supported by Fabric, to achieve similar functionality you should consider new Dataflow Gen2 (Power Query) tool. |
| Pipelines | Data Pipelines | Some pipeline actions have been removed in Fabric. For example, integration with Machine Learning features is now via Notebook rather than Pipelines. |
The following Wardley Map summarizes the table above:
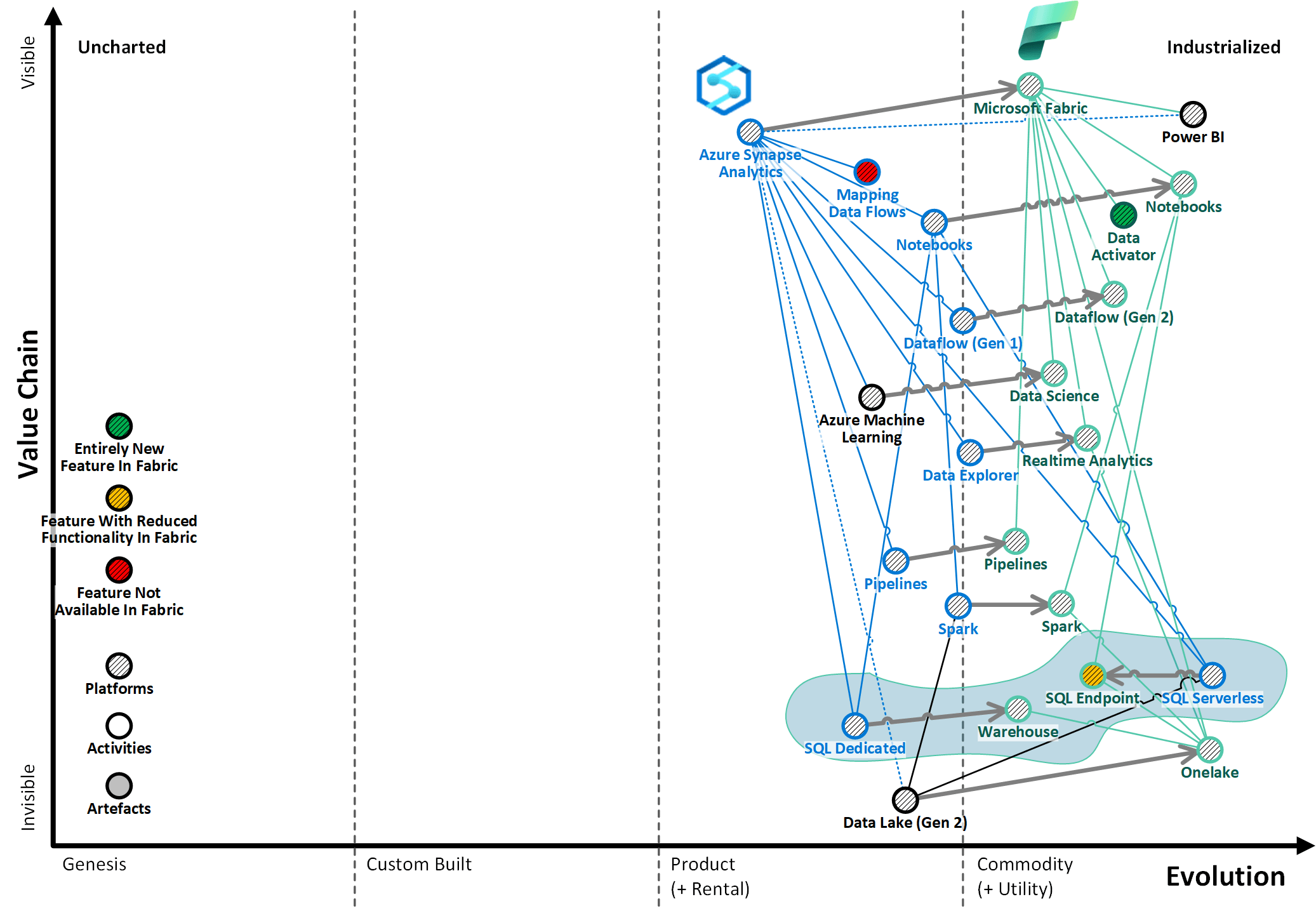
We envisage that this movement in the underlying technology will also enable the evolution of the wider "data value chain". By providing a tightly integrated self-serve data platform that supports the full spectrum of data payloads and analytics requirements, the organisation will be empowered to deliver value from data:
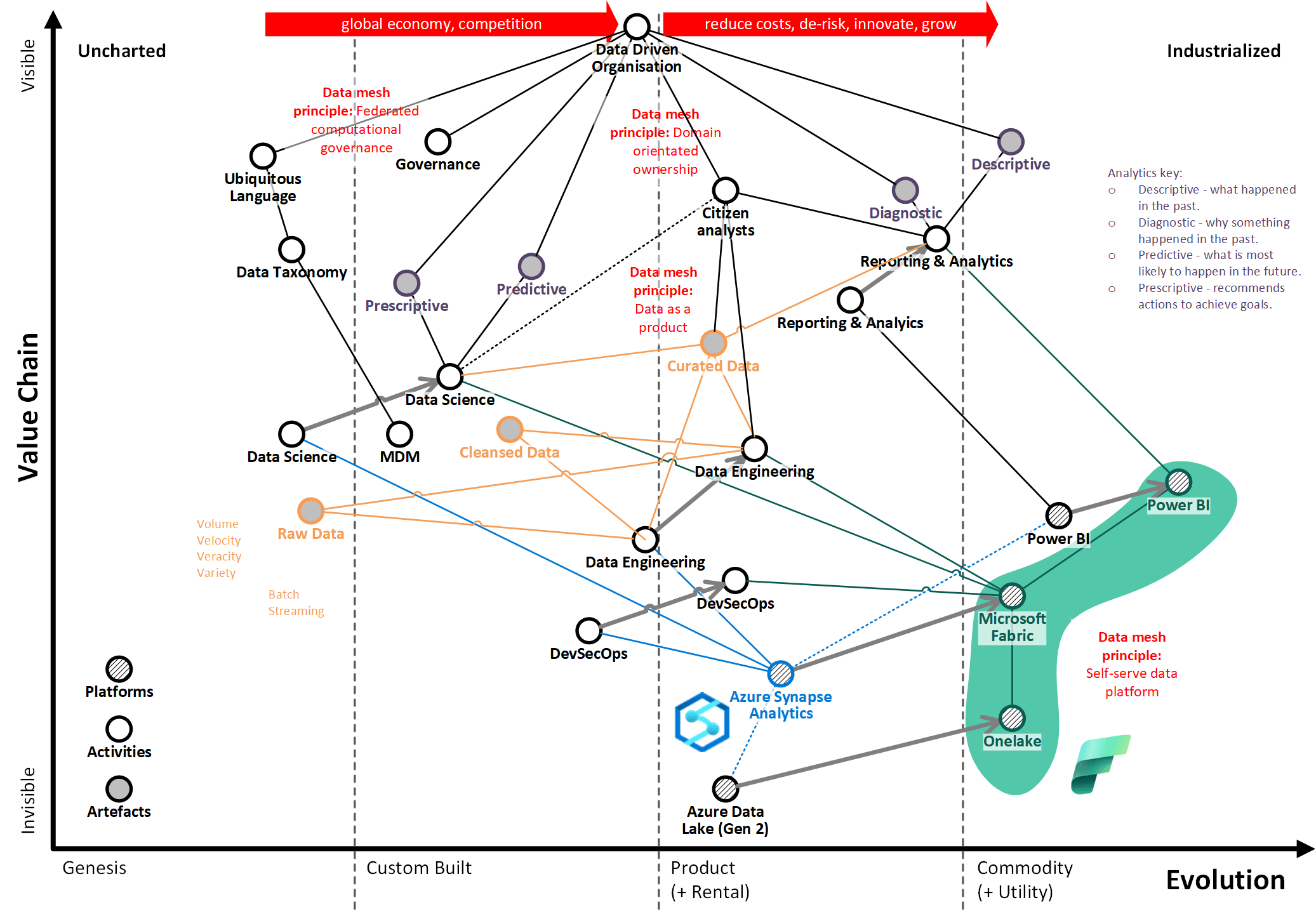
Observations
There are some significant gaps
Even though Microsoft Fabric is an evolution of the Synapse vision, there's isn't a direct or automatic upgrade path. To move Synapse workloads onto Fabric, you will need to manually migrate and modify code such as notebooks, SQL scripts and pipelines to enable it to run. In many cases, this will be relatively straightforward, however in some cases more significant effort will be required because the technology is no longer supported in Fabric, the most significant are:
Mapping Data Flows are not supported in Fabric, the closest functionality instead being provided by Dataflows Gen 2 (Power Query). This will represent a significant barrier to migration for organisations that have invested heavily in the this low code tooling for data wrangling.
There is no support for the OPENROWSET syntax which enables SQL queries to directly address structured data files in the lake. See example below. If structured data is not in Delta format (e.g. parquet, delimited) this data can be placed in the “Tables” area of the Lakehouse, Fabric will automatically scan this data and make it available to be queried via SQL in the “Default Warehouse”, so this provides similar functionality to OPENROWSET but you are querying over the logical managed table that is created rather than directly over the files. This doesn't mean the end of "SQL Serverless" as a technology, the "Default Warehouse" which is made made available over every Microsoft Fabric Lakehouse, can be leveraged in a very similar manner to "SQL Serverless" on Synapse.
The following SQL query syntax which is popular on Synapse is NOT supported by Microsoft Fabric:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://<datalake name>.dfs.core.windows.net/default/raw/purchases/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0'
) AS [result]
Improved integration
Looking to the wider Microsoft ecosystem, Fabric offers "out of the box" integration with functionality that would otherwise require additional Azure resources to be created and configured to integrate with Synapse. Most notable examples are:
Azure Machine Learning - there is not need to create an instance of Azure Machine Learning to register your machine learning models and log experiments, Fabric provides an MLFlow end point by default.
Power BI - whilst there was integration between Synapse and Power BI, this is greatly enhanced with Fabric. Datasets can be created with ease directly on to of the lakehouse, models and measures can be created from within the Fabric UX. This feels like a step change, it is more natural data engineers working "left to right" to transform raw data into analytical data to use Power BI datasets as the semantic layer because they don't need to leave Fabric to create the models and measures. Furthermore, a default dataset is created over any Lakehouse in Fabric further streamlining the process. Finally, the way in which datasets are presented in Fabric as not only an input to Power BI, but as a "data product" that can be consumed by many other means feels like a big step forward, and we hope Microsoft continue to build on this approach.
Developer experience
One significant area that Microsoft Fabric is seeking to add value is around the developer experience:
Time to spin up Spark infrastructure is significantly faster - we are finding it is generally between 20 and 30 seconds, compared to 3 to 4 minutes on Synapse.
The new Notebooks experience offers some attractive new features (e.g. comments, co-editing) for larger teams by boosting collaboration and reducing hand-offs.
Another feature we are excited about is the ability to work locally on Spark based functionality in VS Code, offering further productivity gains for pro-developers.
Git integration is also enhanced in Fabric because core artefacts such as Notebooks are stored in source control using their native syntax where it is much easier to track / review changes.

Having said that, Fabric abandons Synapse Studio to provide an entirely new experience that builds on the Power BI UX. The concept of a workspace is now the primary means to organise assets. We find the new UX can divide the audience, in particular if they have grown used to Synapse Studio. Microsoft have listened to feedback and have made significant improvements to developer experience during the private preview, I'm sure they'll continue to take on feedback to make the experience as productive as possible for all personas.
Commercial model and total cost of ownership
Microsoft Fabric adopts a different commercial model to Azure Synapse Analytics. A significant attraction of Synapse to smaller organisations (with smaller workloads starting out on their data & analytics journey) is the "pay per query" nature of SQL Serverless and the "pay per minute" nature of Spark Pools. Allowing them to run an enterprise grade platform at modest costs that are proportionate to the small workloads they are running. As a result, we have clients who are delivering their organisations data & analytics needs using Synapse, with monthly Azure costs in the order $100s. The low cost / commitment to entry approach has served Synapse well, there is a concern that Fabric may not be as attractive to organisations that are seeking low barriers to entry.
Fabric largely abandons the "pay for what you use" approach. It adopts a capacity based approach. This will force organisations to commit to a minimum monthly spend on the platform. Whilst there are lower tiers available that will enable organisations with smaller workloads to adopt Fabric, the key concern is that this could result in a material impact to Azure costs.
We recommend that organisations model the Total Cost of Ownership (TCO) - in other words to uncover all of the costs in order to make and informed and balanced decision. We anticipate this approach will be highlight tradeoffs in the Fabric TCO where some costs may well increase, however there will also be reduced costs by the very nature of this being a SaaS rather than PaaS platform.
What Synapse workloads are ripe for migration?
Firstly, through Onelake shortcuts the migration process streamlined by giving organisations the option to migrate the Synapse workloads but not the underlying data. Based on our experience using the platform, migration from Synapse to Microsoft Fabric is likely to be more straightforward for organisations that are have predominantly Synapse Spark workloads and are using that to project data for analysis in Power BI. See Ed Freeman's What is Onelake? for a more detailed insight into Onelake and the powerful new features it offers.
Conclusions
Organisations that currently use Azure Synapse Analytics should evaluate Microsoft Fabric and determine how it fits into their technology road map. Key factors to consider include:
- Impact on TCO - how does moving from PaaS (Synapse) to SaaS (Fabric), impact TCO? For example, can savings be realised by removing the need to manage Azure resources?
- Pros and Cons to SaaS - as a SaaS platform, Fabric takes an opinionated approach to deploying, configuring and implementing technologies that you have had more control over with the PaaS nature of Synapse (and the wider Azure resources that often accompany it). In many cases, this could be welcome because it means less decisions for you to make, but you also need to evaluate these "opinions" against your own requirements to make sure it fits your needs now and into the future.
- Vendor lock in - does moving to Fabric make it more difficult to move a different vendor in the future? Is this a significant issue in the first place?
- Time to value - do the developer experience and productivity features in Fabric (e.g. the new Notebook experience) open up opportunities to streamline end to end development lifecycle?
- Minimising technical debt - will Fabric simplify your codebase and therefore reduce maintenance effort? For example, direct "see through" connectivity from Power BI to Delta tables in the lakehouse means that a SQL layer (and the associated scripts to create the SQL views) no longer need to be maintained.
- Azure costs - Fabric adopts a different billing model to Synapse, how this will impact your monthly Azure OpEx?
- New features - looking beyond the "like for like" migration of existing functionality, what opportunities do the new features of Fabric offer, do they unlock use cases that are in your backlog?
- Strategy - how does Fabric fit with your longer term data & analytics strategy? How well does Fabric fulfil next generation data & analytics capabilities:
- Lakehouse - bringing together the best of data lake and data warehouse capabilities to streamline the delivery of modern, cloud native analytics
- Data Mesh architecture - to support de-centralised domain driven ownership, "data products" that can be discovered / shared and enabling democratisation of analytics through a self-service data platform
- Data virtualisation - through features such as OneLake
- New concepts - as a next generation platform, Fabric introduces a number of new concepts that need to be evaluated against your own business, data and technology architectures. Do these concepts align well with you needs?
If you believe there are opportunities, as a next step, we recommendation that you make a small targeted investment in a "technical spike" to evaluate how well Fabric can support your data & analytics vision. Microsoft provide detailed instructions about how to get access the Microsoft Public Preview trial on their web site.
This should performed as a disciplined experiment, based on:
- Fixed scope - focusing on a suitable use case (typically an existing Synapse workload) that can be used to drive validated learning
- Time boxed - aiming to generate insights in weeks not months, with a mindset of "failing fast" if necessary
- Holistic - an evaluation that extends beyond the technical to also consider the wider organisational implications of adopting Fabric
- TCO - we recommend building a complete view of the total cost of ownership (TCO) to compare current architecture with a Fabric. This should include workload modelling for Azure costs, future development costs for evolution of workloads, costs of servicing technical debt and training costs.
- Success criteria - a clear set of objectives for the technical spike that cover both tactical and strategic considerations. These should be aligned to the organisation's strategic goals.
If you would like to explore how Fabric could help you accelerate, de-risk and streamline your data & analytics strategy, please get in touch for our free data strategy briefing.



