My Year in Industry so far


As I approach my 6 month mark at endjin, I reflect on what I have worked on and what I have learnt.
First few weeks
On my first day at endjin (1st August 2022), I met a couple of members of the team in Reading in a co-working space to hand over my work laptop and get started. Despite coming back to a company that I'd worked with over the summer a year prior, it felt as though it was my first day along with the same excitement and nerves. The first day was mainly installing and setting up everything I would need and having a catch-up on what had happened since I was last there.
As the week progressed, I worked on a number of different projects, including the 'intern project' that I previously worked on with the other three interns, which focused on generating synthetic customer data. It was amazing to be able to come back a year later and see the progress that a project has made and how it may have changed differently than you'd expected it to, where even the initial objective had evolved as it was used across several active customer projects and new features and use cases emerged. This highlighted the importance of reviewing and re-planning as a project continues to ensure it still fits the use case.
Over the course of the first few weeks, I found that I had found my footing again and was beginning to fall into the pattern of working from nine to six each day. I began to find that I was understanding more about the different topics that everyone was mentioning or talking about and that certain bits of information started to click as I learnt about more surrounding different projects.

In Week 2, Howard introduced me to the OpenChain project, set up by the Linux Foundation to create a standard for creating, using and modifying open-source software. It shows organisations where they need to be to be in line with ISO 5230 standard and ensure open-source licence compliance is met so that it is quicker and easier to use open-source software and improve security. He explained how focusing on the adoption of this could be a great self-contained project for my year in industry as it covers all the different stages of a project and could eventually work on making it a service that endjin offers in the future.
OpenChain
I began to research OpenChain by reading articles and watching previous webinars that have been held to gain a better understanding of the specification. I got given access to the 'Getting It Right With Open Source Software' course by Holly Wyld and Martin Callinan. This introduced me to a number of different core aspects surrounding OpenChain, starting with explaining what open-source software is, to learn about the licences that make them open source. From here I had the basic knowledge to continue researching the parts I didn't understand or wanted to know more about, and I started documenting it as a blog post. Endjin has a blog section on their website where they write blogs about topics they're working on or new and exciting technologies.
Initially when I started writing my blog post, it was quite short and concise, I hadn't reached many different parts of OpenChain, but after receiving feedback I realised that I needed to explain everything as clearly and simply as possible, so it was easy to pick up for anyone, including me. The more I wrote in my blog, the more I realised I had to learn about the subject, which led me to explore much deeper into OpenChain and open-source licensing. The more I learnt about OpenChain and the processes involved to manage all of endjin's open-source licenses, it started to become much more complex than I had previously thought, it now showed to be more than just a legal problem, but a security one too. After lots of researching, my introduction to OpenChain blog became three blogs as a series:
Due to the OpenChain project being a non-prescriptive standard, it's higher level so it doesn't tell you how to do anything, you need to work out how to map it's objective to your own domain. It is also very broad, so that it can fit any company and any technology, it took a while to understand what each part of the specification required and how it applied to endjin. Because of this, there were a lot of discussions about the approaches we wanted to take, and how we were going to design the systems that would automate managing a lot of the repositories.
Generating SBOMs
As the OpenChain specification is non-prescriptive, we had to decide how to implement it for our technology stack. Following an audit of all endjin's open-source repos we found that they consisted of .NET, JavaScript, PowerShell and Python meaning we were able to use SBOMs as a universal standard to analyse all the components of the software.
The first step we intended to take on the OpenChain project was to have each repository generate a Software Bill of Materials (SBOM) which is a graph of dependencies of component, each of which may have a different Open Source Software (OSS) license for a piece of software. It lists all the components and the dependencies that are required to make a program run.
In order to be open-source licence compliant we needed to ensure that we were tracking all our open-source licences. By having an SBOM for each repository, we can track everything being used. Open-source compliance is the process of ensuring that you satisfy the legal obligations and copyright terms that come with open-source licenses. Being compliant means you are observing copyright notices and satisfying the conditions set out in the licence requirements. All licenses in the dependency tree needs to be license compliant. For example, if you are creating open-source software under a permissive license (e.g. MIT) and you are using a licence that is copyleft (e.g. GPL) somewhere in your dependency tree, like GPL v3, you would be required to make the rest of your software have the same licence to be compliant.
Build script manager
My first part of work on the OpenChain project was to work with James Dawson on the 'build script manager'. Each repository should have a build script that builds a program and other commands for Continuous Integration (CI) workflows. The build script manager manages all these scripts, their versions, and use cases. The build script manager is programmed using PowerShell so I got to have a go at programming in a new language and seeing how it is useful for more DevOps/CodeOps cases. CodeOps is a new term created by James Dawson ensuring consistency across repositories, the upkeep of repositories and their pull requests, and maintaining repository workflows. In the build script manager, we added the functionality to generate the SBOM for each repository. Then we set up the workflow to run every night. With this setup, we can generate an SBOM for each repository with a build script and store the SBOM in a Data Lake in Microsoft's Azure Cloud Platform. Here, I designed and implemented a complex data pipeline that was generating data from one store (each GitHub repository), converting it (generating the SBOM data based on the original repository data) and connecting it to a new data source (Azure Data Lake).
With the data now in the Data Lake, we could start to decide how we were going to use it to gain an understanding of each repository, to then know how open-source licence compliant each repository was. I started sketching out a diagram of the processes we were currently using and how they all related to each other. I found that drawing it out so that it can be visualised, made it much easier to see what we'd done, where we currently were and the direction we needed to go moving on.
Data wrangling
The next step was to wrangle the SBOM data, as it was currently in JSON format, and we needed To convert it into a data structure more suited to analytical workloads, tabular format. I started in one of endjin's synapse workspaces and created a notebook. Using PySpark, an interface for Apache Spark in Python, allowed me to do SQL-like analysis on my JSON data. I started by importing the data from the data lake, then ran a series of different commands to extract the data from JSON format. From there I split up the one table into three separate tables: metadata, components, and dependencies. Because each of these tables was different shapes, I kept them separate for ease of processing and visualising. I then wrote them back to the data lake as parquet files.
Visualising data
I replicated this process for the output of the build script manager, also a JSON file. The information passed back to us contained metadata about the run and information about each repository that it covered. I followed the same Azure Synapse process of importing the data and generating two tables: metadata and repositories. Having this data, we wanted to be able to see which of the repositories were being processed. To do this I designed a Power BI report which visualises the data.
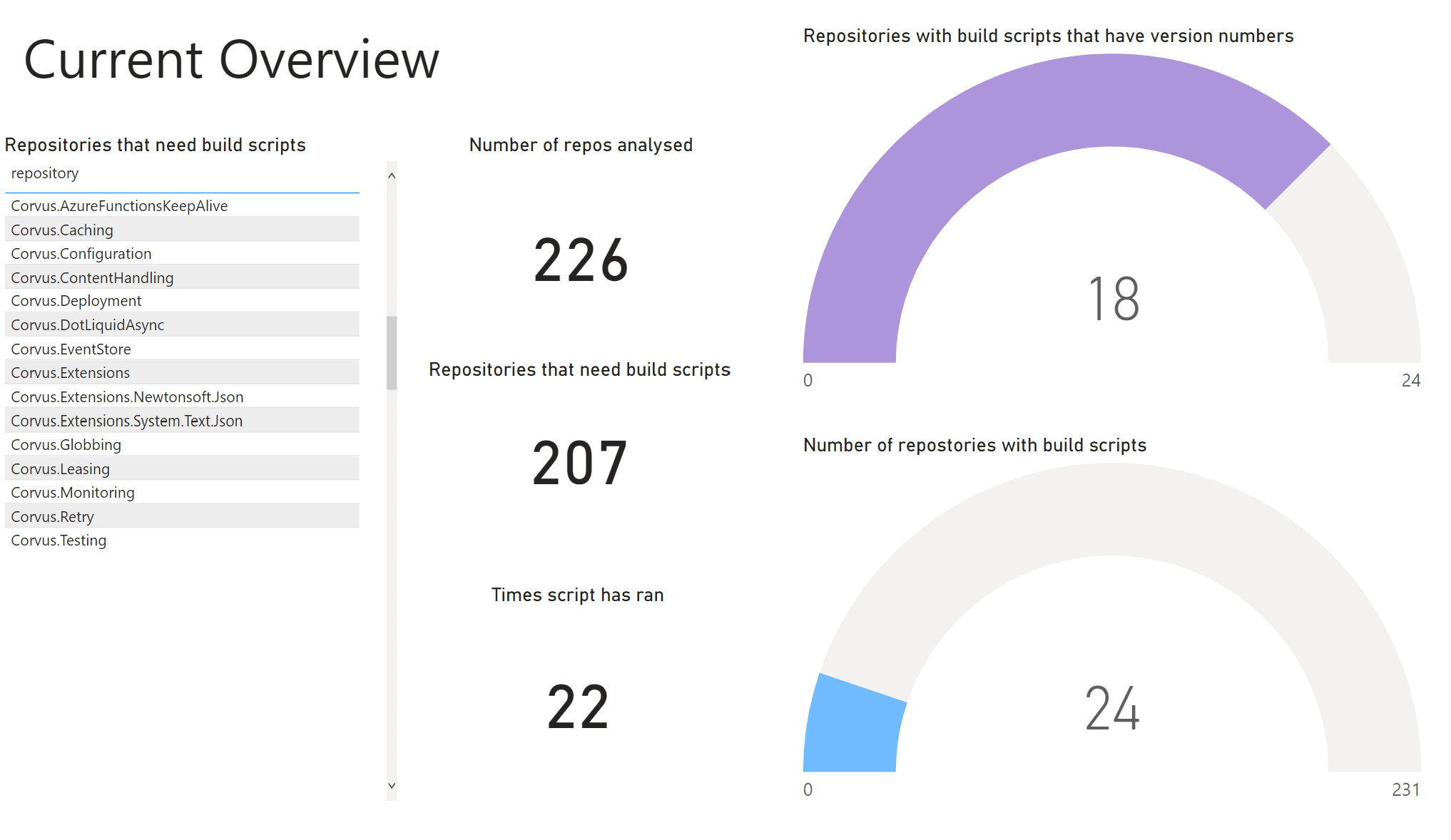
I created an overview page, which contained a list of the repositories that still needed build scripts, semi-circle radial bar charts and cards with key numbers on them. The radial charts were useful as they can show the progress towards how many repos were being analysed, and how many still had to go. There was also another page called 'over time' which contains four bar charts that show the progress over time, to show whether new repositories were being upgraded to allow for analysis.
For the repositories to be recognised by the scripted build manager, they need to have a PowerShell-based standard build script, part of endjin's reusable "Recommended Practices framework" called build.ps1 file. This can be generated for each repository following several steps, using endjin's build tools. As endjin has over 200 repositories spread across several GitHub organisations, I spent time going through and migrating the repositories that were ready over to scripted build. This meant that they could then generate SBOMs and therefore were being tracked, and later managed.
IP Maturity Matrix
Endjin has developed a framework called the IP Maturity Matrix (IMM) that measures the engineering practices 'quality' of a repository, for example how much of it is documented or how much code is covered by tests. As part of the OpenChain project, we wanted to link in OpenChain to the IMM as a new category, so that it would show whether a repository generates an SBOM.
Scores for IMM are stored in the repository in a imm.yaml file, with the scores being manually created and decided. However, we had the data on whether an SBOM was being generated, or not, for each repository, so we wanted an automatic way to update the YAML (another markup language) files in each repository, especially because the data is dynamic and could be updated from day to day.
As we already had the code from the build script manager that can go through all the repositories and update them, we decided to repurpose the code for this new functionality. I went through and rewrote the PowerShell logic that would make the changes to the repository, wrote the new unit tests using pester and imported the data from Azure as a CSV to use against the imm.yaml files. Then went through and set up the workflow, so that it can run daily on its own as a GitHub actions workflow. Now it updates all the yaml files to give insight into each one, whether they have an SBOM or not.



