In Defence of Squash Commits


I'm a big fan of Mark Seemann's (ploeh) writing. I recently engaged with him over a tweet.
Git squash is destructive. Why burn a bridge behind you? You can always squash locally if you ever need to, but you can't reconstruct the history you destroyed. A comment: https://t.co/zfrYKsP3Ua
— Mark Seemann (@ploeh) October 11, 2022
I disagree with this conclusion (partly because it is based on a false premise). I wrote a bit about my reasons in reply but as Mark later said:
I don't think Twitter is a good medium to discuss implications
I did write a short explanation of one of the factors that has led me to the opposite of Mark's conclusion. But as I've thought more about it, I've remembered that there are many factors that have, over time, led me to prefer squash commits, and the one I put in that thread wasn't even the most important. It was merely the one that had the most vivid associations. Twitter is absolutely the wrong medium for this, hence this blog post.

The context of the discussions is Mark's Use Git tactically post, in which he advocates "micro commits." It is not an article about commit squashing, but at one point he does mention in passing that he is not a fan of commit squashing. In context, this seems a bit odd to me, because I take the view is that if you commit in small increments working on a problem, commit squashing can be all the more important.
Not destructive
The heart of Mark's argument, which he reiterates in a comment is this:
Fundamentally, commit-squashing is a destructive process.
But it isn't. If it were, his argument would be compelling, and I'd be against commit squashing myself. But commit-squashing is not destructive. At least, not on the Git repository hosts that I use. If you create a PR in either GitHub or Azure DevOps, the original commit history is preserved regardless of whether you squash the commit when merging the PR.
To illustrate this, here's a screenshot of the recent commit history in the .NET runtime repository:

These are all squash commits. If you squash when merging PRs in GitHub, you will recognize this style of commit message, but if you're unfamiliar with it, notice how each one includes a hash symbol followed by a number. These are hyperlinks. (In the actual commit object in the git repository, they are just text, but GitHub renders them as links.) Let's see what happens if we click one. I'm picking the fourth commit in the list, the one with the message of "Introduce a source generator for invoking methods on unmanaged vtables (#68276)".
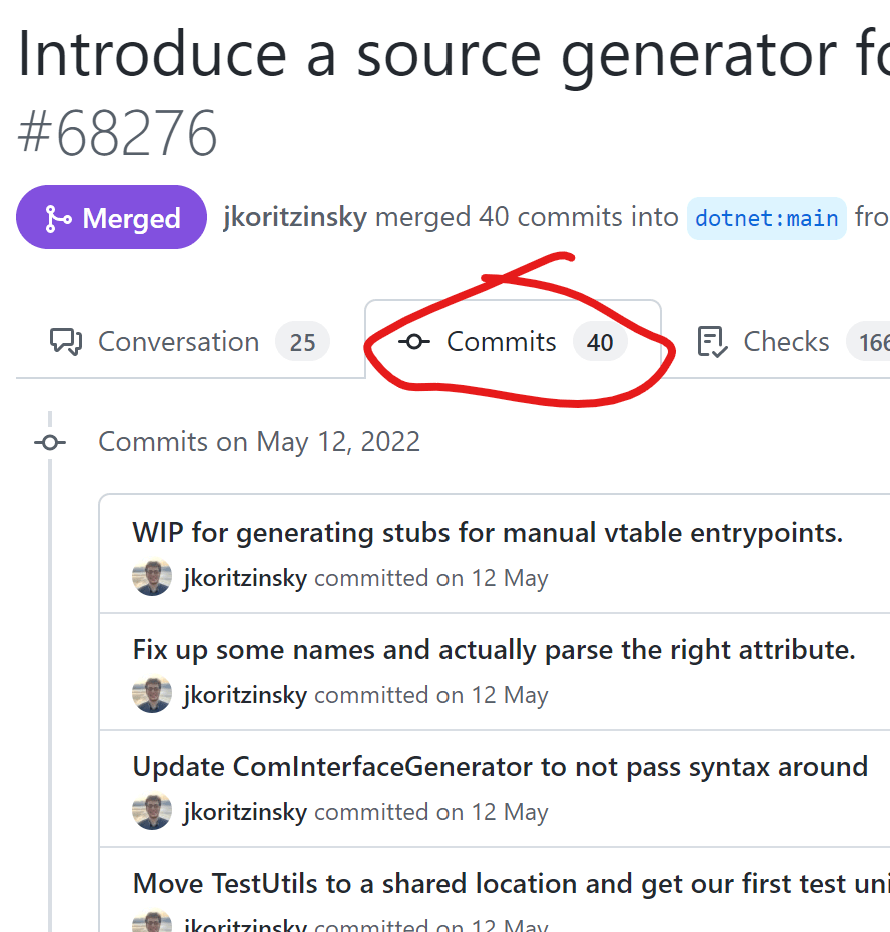
Well would you look at that? There's a tab with a "Commits" label. And what do we see when we click that? Why, it's the complete commit history of the PR! It wasn't destroyed at all.
If you read Mark's article explaining why he doesn't like squash commits, he effectively argues that a squash commit would have made the bisect operation he employs in that article impossible. This certainly isn't true here. As the screenshot above shows, you can find the complete history in GitHub. You can then click the button with the <> label next to any commit to browse the repository's tree for that commit. When you're browsing a tree at a commit that's no longer on a branch, GitHub shows you a warning, but you can open up the branch/tag selector dropdown, type in a new branch name, and it'll offer to create a new branch for you (as long as you have permission to do create branches in that repo; with the .NET runtime repo you'll probably need to clone it into your own org first) with the full original commit history. You could then fetch that branch to your local repo clone, and run the bisect.

So there is a little bit of extra manual work on the very rare occasions that git bisect is the right tool. But the alternative is to make your commit history several times larger than it needs to be. (I'll be coming back to the problems that causes.)
In summary, the principle argument offered against squashing commits does not hold, because it is based on a false premise.
Pre-empting an objection: repo completeness
There's one obvious objection to this: if you make a local clone of the repository, you won't have access to the history for old PRs by default. You can make it available locally by creating a branch for it as described above, but you can only do this by going into GitHub first. So there is information up on GitHub that won't necessarily be in local clones of your repo. If you want local clones to be a complete copy of everything, you might object to this.
My response is: that ship already sailed.
Git repository hosts such as GitHub and Azure DevOps provide a great deal of contextual information that is not in your local repo clone. Work items/issues are perhaps the most obvious example. The discussion threads attached either to these or PRs are another. There is also integration with build and deployment mechanisms—for example, Azure DevOps can show you which environments the PR you're looking at has been deployed to, which build was deployed where, and whether any related builds or deployments encountered problems.
(I'll return to this later because I believe that high quality context gives good reasons to favour squashing commits.)
It is of course possible to take a purist stance that everything of importance should be in the repo, available in every clone (although it's not clear to me what you do for issue tracking if you take this stance) in which case it makes sense to reject the idea of squash commits. (Even then, you could just choose not to delete old branches after merging, and if you have a deep objection to destroying information, maybe that's already your policy.) This stance also entails rejecting a lot of the value that products like GitHub and Azure DevOps can add beyond the bare repo.
If you have decided to take advantage of what these systems have to offer, then you already crossed the line where not everything is in your repo. At this point, insisting that every PR's commit history must be in the repo seems incongruous.
Now that we've established that the principle argument against squash commits is simply wrong, let's look at some of the benefits.
Cognitive load
Code that expresses intent can often be easier to understand than code that expresses only mechanism. If I write this:
int m = Math.Max(v1, v2)
it is completely clear that it is my intention to assign into m whichever of v1 or v2 has the higher value. I find that preferable to the following:
int m = v1 > v2 ? v1 : v2;
This second example isn't much harder to understand. But it's a bit harder to understand. I have to look at it and infer the original author's intent. There are two reasons this is less good. First, there's more uncertainty over whether the developer really meant this—if I'm trying to find a bug, then I have to consider the possibility that the developer meant something slightly different from what they wrote. That's a lot less likely in the first example (although that still leaves the possibility that they did mean that, but they were wrong to do so).
But there's a more serious problem. The second example places a larger cognitive load on the reader. Anyone inspecting this code has to work harder to understand it than they do to understand the first example. This leaves less mental capacity for understanding other aspects of the code. By expressing things at a lower-level, the second example effectively reduces the amount of code that will fit in the reader's head.
More generally, there is a simple but highly effective transformation that can often make code easier to understand: move a group of low-level operations into a function with a name that describes the intent of those operations.
When reading code, we always need to understand what the author of the code was trying to do. Code that more directly expresses intent will typically be easier to understand than a bunch of low level actions.
I believe the same principle applies to the commit history. It will be easier to understand a commit history that directly expresses what I meant than to understand of a series of commits that merely capture what I did.
Look again at the example from the .NET runtime. If you look at the full commit history, you will find it includes a commit with the message "Fix up some names and actually parse the right attribute". I don't think it's possible to understand the intent or significance of this commit in isolation. (GitHub agrees with me: if you visit the commit, it shows it to you in the context of the PR, to give you some chance of making sense of it).

Compare that with the squash commit that actually made it into main, which has the message "Introduce a source generator for invoking methods on unmanaged vtables." That tells me what the developer was trying to achieve. (And it's linked to the PR, so I can go and look at the entire commit history if I want to see all the steps and missteps the developer took to implement this.)
I like code that does what it looks like it does. And I like my commits to have the same quality.
Meaningless noise
Staying with that example from the .NET runtime, it illustrates why it is at best unhelpful to include certain commits in your main branch. That last individual commit I mentioned is there because the commit immediately before it had some mistakes.
It's also common for commits to fix typos introduced earlier. The fact that this occurred is not useful to someone trying to understand the code later on. Leaving commits like that in the history just provides a smattering of extra low-level cognitive overhead. It might not require a lot of effort to see that the commit just corrected a typo and can therefore be ignored, but this still consumes a non-zero amount of mental capacity. If you have a lot of this kind of noise, it starts to add up. Why would you want your code to be harder to understand than necessary if there's no upside?
It's worth acknowledging at this point that some commits have more value than others. This means that extremist points of view such as "never squash" are not universally applicable, and of course it means I must agree that a "squash everything" approach is also not necessarily always the right answer. When I've been working on something that required a great deal of experimentation and false turns, I have sometimes done a rebase to remove the most worthless commits while retaining the more significant ones. (I do this a lot when working in other people's repos where they do not squash PRs. I sometimes do it even when squashing PRs, because removing clutter from the history recorded by the PR can sometimes be useful.)
By the way, if you ever work experimentally on a feature, and then once you've worked out how it will work, you discard the experimental branch and create a new one where you do it for real, I would argue that this is not different from a squash commit in any deep way.
Sometimes I commit and push because I happened to need to move from one computer to another, or just because I wanted to protect some work in progress from machine failure. (Advocates of the "never 5 minutes from a commit" approach would just say: well you shouldn't ever be in that situation. That's sometimes fine, but I often end up doing experimental work where it is not at all clear up front what will work. The necessary research can take days, so that kind of activity just isn't compatible with that mindset.) The external events that made it necessary for me to move to a different room have nothing useful to say about how the code evolved. Ideally I would erase them even from the PR's record of the full commit history, and I certainly don't want them on main.
Commits with context
One of the things I find difficult when working in a "we don't squash" repo in project with a large number of contributors, and a lot of concurrent work in flight at any one time, is that it can become very difficult to understand why any single commit is in there.
If a commit appears only in the history of a PR, this is never a problem. As I showed earlier, git presents the commit in the context of the PR to which it belongs, so you can see exactly what it was for. And if your PR is associated with work items, you can go on to learn more about the background of the work. And if everyone always rebases their commits before merging back to main, giving you a completely linear commit history, it's also not a problem. But if that's not the standard practice, it can be a lot more difficult.
This is another excerpt from the comment Mark posted under his blog:
you can always do a ‘private squash' if you need to. In the situation you outline, if you truly feel you could get better insights from a squashed commit, then squash it on your local machine, and keep the squash there.
This supposes that it's easy to work out what to squash. But I have arrived at many a Git repo in which the commit history is an impenetrable mess, a situation someone memorably described as turning the commit history into Guitar Hero. (I believe the original source, which has some salty language, is here.)
So yes, you can squash on your local machine, but only if you don't mind doing 30 minutes of research to work out what to squash. Conversely if you always merge changes back to main with a squash commit from a PR, it takes seconds to find the entire full commit history from the squash commit. My way imposes much less work on someone who wants to see the full history than Mark's way imposes on someone who wants to see the purpose and context of the commit.
This easy determination of the context of a commit is something I mentioned earlier when pre-empting an objection based on not all information being baked into the repo. The upside of allowing that some information lives in your repo host is that it can enrich the context. But there's one particular benefit I want to talk about.
Summary and detail
When you produce squash commits from a PR, you have the option to look at two different levels of detail. By default you will see a relatively high-level expression of intent. But you have the option to look at the full commit history if you want more detail.
This is analogous to what happens if you transform code by wrapping a series of steps in a well-named function. The first thing you see will will be a description of intent. You have the option to go and look at the function definition if you need to inspect it in more detail.
One of the big problems with refusing to use squash commits is that you get just the one level of detail. Imagine transforming a codebase by identifying every leaf function, and then replacing each call of each leaf function with the contents of the function. Now do it again, and continue until your code is one vast, flat, single function. Would you expect that to make the code easier to understand? Always having all the detail inline with no structure doesn't sound to me like a strategy likely to make a codebase easier to understand.
Having just two levels of detail in the commit history provides a lot less flexibility than the arbitrary extent to which we can compose and abstract in code. But two levels is better than one.
Git merge disasters
Finally, we get to the issue I raised with Mark on Twitter. Having had time to reflect, I now think this is the least important of the issues, because I've only ever run into this with codebases that were troubled for other reasons. (Specifically, codebases where it took far too long to merge changes back to main, and where vast amounts of work were in flight simultaneously.)
On a couple of projects I've worked on, I've hit situations where an overly complex commit history causes Git to decide that when merging a multi-commit change back into main, it will make you resolve the same conflict for every single commit in your change. Worse, sometimes these conflicts somehow come back later—I've been asked to resolve conflicts I already resolved in earlier commits (again, for every single commit in my latest merge).
I never got to the bottom of why this occurred. It seemed more productive to devote energy to convincing my clients to avoid the practices that seemed to lead to this problem. But I've seen it happen on two unrelated projects. It is one of the reasons I'm reluctant to have large numbers of commits in what amounts to a single logical change.
Conclusion
Total detailed information can be useful, but it is often useful to encapsulate. You can retain all of the value while improving readability. This is as true for commit history as it is for coding. Git-based repositories do not have a good, arbitrarily composable mechanism for this. Squashing commits in a way that makes it possible to get back to the full history is the closest we get, and in my view, this is better than having the highest level of detail be the only available level of detail. Encapsulation destroys no information, and it improves readability.