Does Azure Synapse Link redefine the meaning of full stack serverless?


The work we do for our customers at endjin falls under two broad categories - Data & Insights, and .NET Modernisation. There's many varieties and flavours of the specific engagements, use cases, workloads and deliverables, but essentially we help people with data challenges, and we help people with modern application development.
As time goes on, these worlds become more closely and closely aligned. The problems, challenges and opportunities that our customers face tend to straddle both sides of equation - "how do we design a secure, scalable, cost effective platform that can ingest many millions of messages a day from IoT devices", and then "how do we securely and efficiently analyse masses of data in the cloud, in a cost effective way".
As such, we meet fewer and fewer organisations with siloed development and BI teams, and more and more organisations with "hybrid" roles such as DevOps, Data Engineer, even Data Ops, all reflecting the journey that these organisations are on, towards being cloud-first and data driven.
This is enabled by the underlying technology platforms - the agility, scale and speed that the cloud provides - especially when you align to a vendor and take advantage of platform service based (PaaS) and serverless architectures.

Serverless in particular has been a game changer in recent years, offering simple deployment mechanisms for application logic and consumption-based pricing models, or pay-as-you go code execution. Serverless architectures also provide elastic scalability without the overhead of configuring or tuning underlying infrastructure, meaning small teams can achieve big things - further blurring the distinctions between being a software developer or hardware engineer.
Full stack serverless
The phrase "full stack serverless" is a relatively new term, but one that's already gained traction, and already has its own book. It covers the architecture, platforms, and associated skill sets needed to build and deploy end to end serverless applications. This typically means web UIs built with Javascript frameworks that can be hosted as static single page applications (e.g. Vue.js, React etc), talking to backend APIs hosted in serverless compute platforms (like Azure Functions and AWS Lambda), which read and write data in cloud storage, either SaaS databases (e.g. Cosmos DB, Firebase), or lower level storage services (e.g. Azure Blob, Amazon S3).
All the major cloud platforms offer services to support this architectural pattern. Azure Static Web Apps is one such service, that not only provides serverless hosting for SPA web UIs and integration with Azure Functions serverless APIs, but makes it incredible easy to build and deploy these types of applications by offering a streamlined developer workflow. Continuous deployment from code repositories, integrated domain configuration, and built-in authentication and authorisation providers means the time-to-value is significantly reduced.
But where "full stack" falls short is that it focuses solely on the application architecture - the transactional, user facing end of the solution - and ignores what happens behind the scenes. What about the back-office analytics function, including everything from "traditional" BI, to more advanced data mining and predictive modelling?
On-demand cloud analytics
Alongside the rise of PaaS services and serverless architectures in the application domain, there's been similar advances in the analytics space in recent years. As the cloud offers infinitely scalable and increasingly cheaper storage, the rise of big data (capture everything, as it might be useful) has meant new cloud-based analytical and data processing tools have also become available.
Cloud-based ETL tooling (e.g. Azure Data Factory), map-reduce and parallel processing (e.g. Hadoop, Spark), and machine learning and predictive modelling capabilities (e.g. Azure Machine Learning, Google AI Platform) are now all available under the PaaS and SaaS model. But the nature of these workloads - whether it's ad-hoc experimentation, or massive-scale data mining, means there's still a logical, and often physical boundary between the notion of "the application database" and "the reporting database" in most holistic solution architectures. This means broadcasting and syncing changes between the two, so that a back office reporting process doesn't negatively impact a live transactional system.
And, whilst they might be marketed as PaaS services, in most cases there's still a need to provision underlying clusters to execute workloads. Spark-based platforms in particular (e.g. Databricks) have risen in popularity massively as the next progression from Hadoop-based big data processing. And whilst they're marketed as pay-as-you-go services, they're still not-quite "properly PaaS", or "properly serverless". You need to provision and spin up (albeit easily) Spark clusters to execute your workloads, and there's still an overhead in terms of time and money around that cluster start up and tear down, around the actual workload you're executing.
Azure Synapse - the missing Link?
Azure Synapse presents a unified, integrated view over a collection of Azure data services, which can be used to support the end-to-end data and analytics process. It includes services and tools for data ingestion and storage, data preparation, data visualisation, environments for experimental data wrangling, a platform for hosting common data modelling tools and libraries and services for automation and productionisation of the end to end workloads.
But as well as packaging up existing Azure data services in a very compelling box, Synapse also brings some new and exciting technology to the table.

Pay as you query (PAYQ)
SQL on Demand is a new service that allows you to execute T-SQL queries over files stored in Azure Data Lake Gen 2, or Spark tables. This is true serverless technology – there's no SQL Server or database to provision and manage, but you can connect to a SQL on Demand instance from any client application that supports a SQL Server connection and execute SQL code over your data in its raw form – either CSV or Parquet files – in your data lake. Queries are charged based on the amount of data scanned, depending on the region.
Hybrid Transactional Analytical Processing (HTAP)
But the real game-changing piece is Azure Synapse Link for Cosmos DB, which extends the support for SQL on Demand to enable querying over the Cosmos DB Analytical Store. This is a fully isolated column store of your data in Cosmos, that allows you to execute large scale analytics against operational data without any impact to your transactional workloads.
Data is automatically synced between the transactional store and the analytical store in near real time, and the column store format is optimised for large scale analytical queries, improving the latency and query performance.
With Azure Synapse Link, you can develop "no-ETL" hybrid transactional/analytical processing (HTAP) solutions by directly linking to Azure Cosmos DB analytical store from Synapse Analytics.
This means the "full stack serverless" definition can be extended from the application stack to the analytics stack - using SQL on Demand as a serverless, consumption-based query engine over an optimised analytical store of your transactional data, that is automatically synced as your serverless transactional application reads and writes to Cosmos DB.
As this diagram from Microsoft shows, those SQL on Demand queries can be integrated into any standard BI tooling (e.g. Power BI), providing an end-to-end serverless transactional and analytical solution architecture.
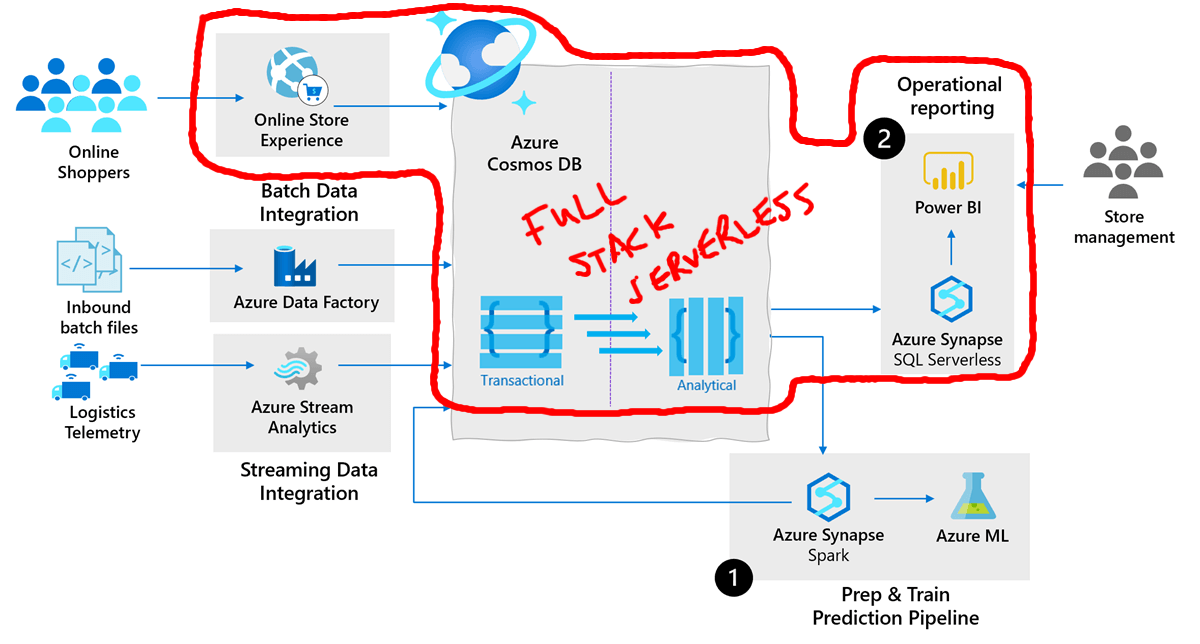
Redefining Full Stack Serverless
Azure Synapse Link for Cosmos DB redefines "full stack serverless" by literally acting as the link between a serverless application stack and serverless analytics enabled by SQL on Demand.
With this set of technology, an end to end, serverless, consumption-based architecture is possible, meaning the time to value for the entire solution is reduced and smaller teams can achieve bigger things.
Want to get started with Synapse but not sure where to start?
If you'd like to know more about Azure Synapse, we offer a free 1 hour, 1-2-1 Azure Data Strategy Briefing. Please book a call and then we'll confirm the time and send you a meeting invite.
We also have created number of talks about Azure Synapse:
- Serverless data prep using SQL on demand and Synapse Pipelines
- Azure Synapse - On-Demand Serverless Compute and Querying
- Detecting Anomalies in IoT Telemetry with Azure Synapse Analytics
- Custom C# Spark Jobs in Azure Synapse
- Custom Scala Spark Jobs in Azure Synapse
Finally, if you are interested in more content about Azure Synapse, we have a dedicated editions page which collates all our blog posts.