Azure Synapse Analytics: serverless replacing the data warehouse


As businesses are becoming more reliant on data, they are demanding richer insights, greater agility, and more innovation. In response, the traditional SQL data warehouse is being replaced by discrete data pipelines that feed curated data to the business via optimised storage solutions and APIs.
These new data architectures rely on serverless compute and cheap storage to provide the scale and efficiency, while enabling teams to remain focused on insights rather than infrastructure.
A modern serverless data architecture
At the heart of the serverless data architecture is cheap, commodity cloud storage usually in the form of a data lake. The data lake is the primary data source for downstream business reporting. This cost effective and highly available storage is evolving to include fine grained security, immutability, automatic data lifecycle management and even native query.
Once data has landed it is then processed into representations and formats that meet the functional, performance and availability requirements of the business. This is achieved by building specialised data pipelines for individual workloads. These pipelines feed data to APIs that in turn drive business reporting and applications. This usually requires an intermediate store which is chosen based on functional and operational needs.
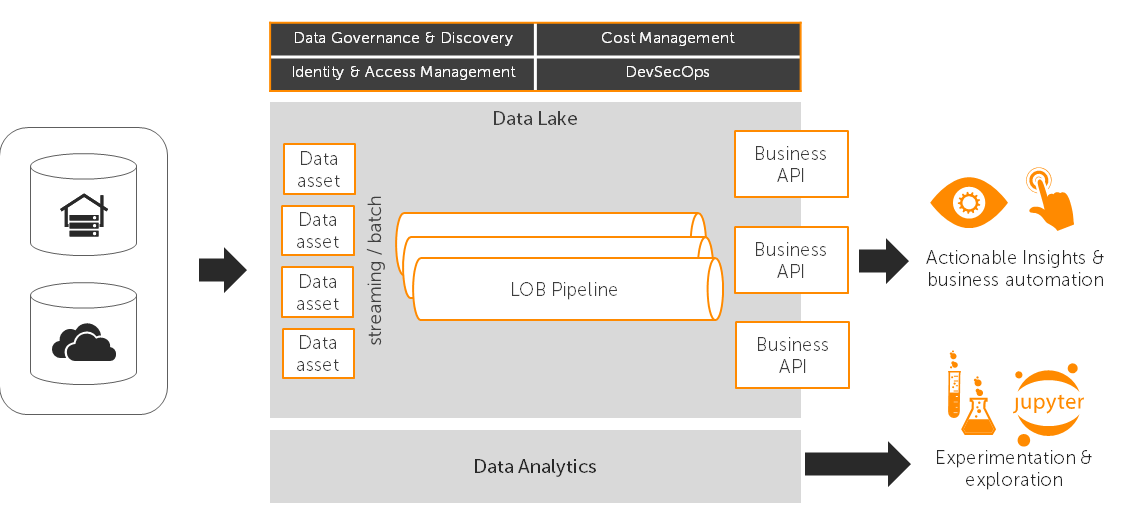
Technologies that natively use cloud storage as backing stores with standard file formats encourage outputs to be stored and served from the data lake itself. This helps to generate a data sharing culture which increases opportunities and reduces effort.

This approach represents a step-change from standardization to optimisation.
In many ways this architecture replicates a traditional data mart. The 'warehouse' is implemented a set of standard entities over a data lake with various ETL processes populating business specific stores. The difference is in the flexibility to match workloads with the right processing and technology blend, enabling solutions to naturally evolve in line with business need.
Where a business unit may traditionally have had their own data mart in the form of a SQL database, they now have information and insights delivered in the best format at the right time for a specific business activity. They also gain the ability to be able to tap in to the data lake at any level, from curated insights back to raw data. What's more generated information and insights are then contributed back into the data lake for others to use.
Of course, this approach does not come without a number of questions and concerns, and if left un-addressed could lead to an expensive and unmanageable data estate.
Why serverless is needed
One potential drawback of this approach is the additional burden associated with managing an explosion of data stores and services in use. Serverless helps address this concern by removing the effort associated with managing and maintaining infrastructure. Operational effort is shifted upwards to the workload level and associated savings are re-invested in governance and automation.
Policy driven cloud governance and security, enforced by the data platform, ensures delivery teams have the guardrails they need for compliance. Workload monitoring insights and alerting streamlines operational efforts and pre-emptive issue detection helps ensure remedial action is taken before the business is impacted.
Another significant benefit of serverless is the shift to consumption-based computing which enables modern chargeback accounting and cost management. This helps to unlock business budgets and makes it easy to define and track ROI. In-turn, this helps to fuel innovation while ensuring inefficient processes are either updated or retired. The overall outcome is a much leaner data-driven organisation.

The biggest hurdle for serverless is likely to be cultural. Organisations who are unable or unwilling to adopt a more collaborative, decentralized agile approach may struggle. Those more likely to succeed will adopt an evidence-first approach at every stage.
Give me an example
Serverless storage is relatively mature, most organisations who are operating in the cloud are taking advantage of it whether they are aware of it or not. Truly serverless data querying and processing on the other hand is just starting to emerge.
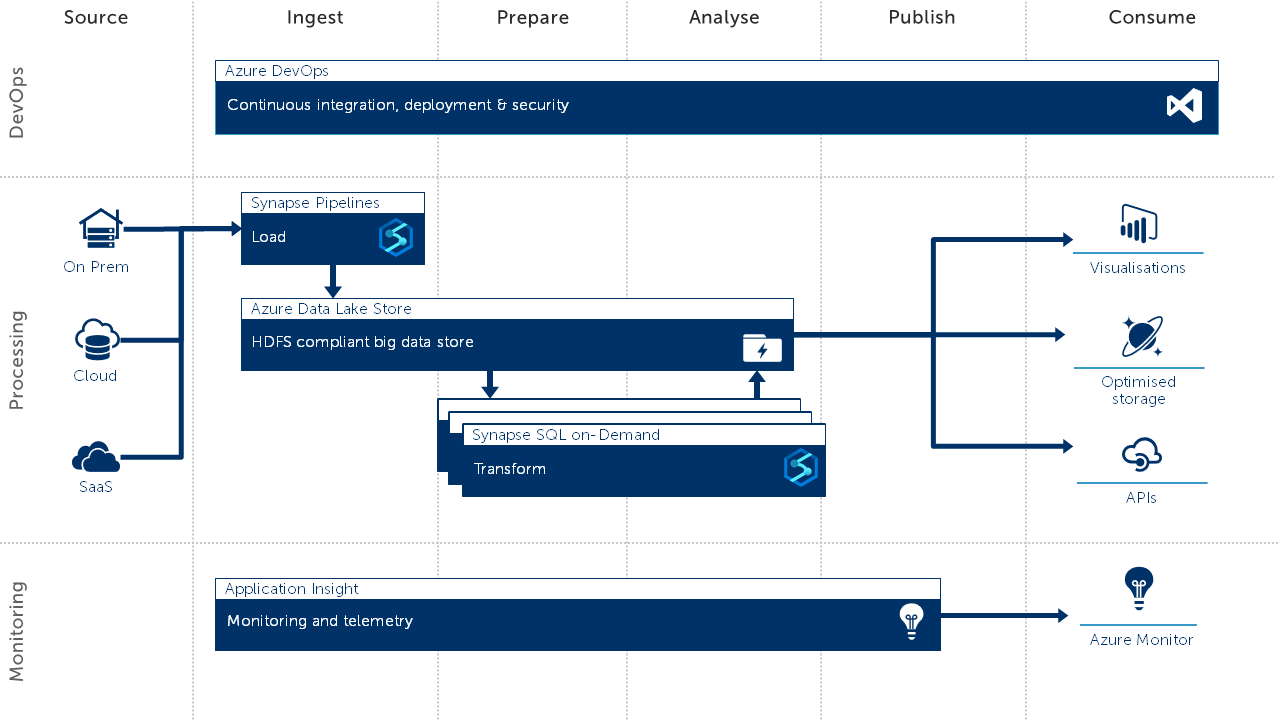
A great example of this is Azure's Synapse SQL on demand. The services allows you to query, combine, and process data stored directly in data lakes as CSV, Parquet or Json. This can be combined with Synapse Pipelines (Azure Data Factory) to build business focused data solutions.
If you are interested in getting your hands dirty, checkout the video below.
Want to get started with Synapse but not sure where to start?
If you'd like to know more about Azure Synapse, we offer a free 1 hour, 1-2-1 Azure Data Strategy Briefing. Please book a call and then we'll confirm the time and send you a meeting invite.
We also have created number of talks about Azure Synapse:
- Serverless data prep using SQL on demand and Synapse Pipelines
- Azure Synapse - On-Demand Serverless Compute and Querying
- Detecting Anomalies in IoT Telemetry with Azure Synapse Analytics
- Custom C# Spark Jobs in Azure Synapse
- Custom Scala Spark Jobs in Azure Synapse
Finally, if you are interested in more content about Azure Synapse, we have a dedicated editions page which collates all our blog posts.
FAQs
How do you run an Azure Synapse SQL on-Demand query from Azure Data Factory?
Azure Synapse Analytics comes with tabular data stream (TDS) endpoint for SQL on-Demand, meaning you can run SQL queries as if you were talking to any SQL Server or Azure SQL Database. It's therefore possible to use a standard Copy Activity in the same way as you would were you to copy data from a Azure SQL Database. The TDS endpoint can be found on the workspace overview tab of your Synapse workspace and is in the format<workspace-name>-ondemand.sql.azuresynapse.net. Note that you will be constrained by the language features available with SQL on-Demand. In the future, it is likely that there will be tighter workspace integration along with stored procedure support. This means that you will be able to take advantage of SQL on-Demand features such as CETAS.