C# faux amis 3: variable declarations and type patterns


As you may recall, I started this series with a mystery: sometimes using an explicit type causes the compiler to perform fewer compile-time checks than will occur if you use var instead.
The title of the article provides a clue as to when this can occur, so let's look at the similarities and differences between a couple of language features introduced in C# 7.0: deconstructing assignments containing variable declarations, and type patterns.
Compare this deconstructing assignment:
(int x, int y) = p;
with the pattern here:
if (p is Point (int x, int y))

If you're looking at that and thinking "That's not a type pattern," and are then struggling to resist the urge to complete the meme with "THIS is a type pattern" then you should surrender to the urge. While you are correct that the thing after the is keyword is a positional pattern, it contains two nested type patterns:
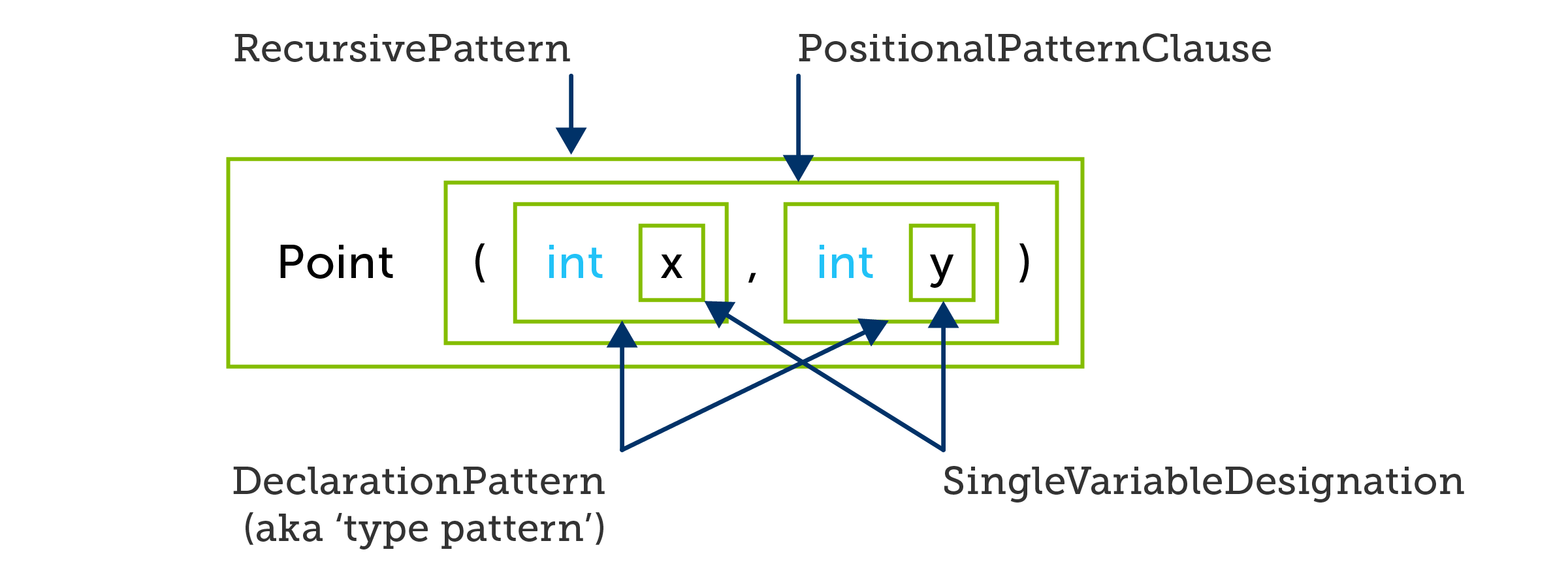
In the examples earlier in this series, we've been comparing deconstructing assignments with entire positional patterns, but now I want to focus on the patterns nested inside this positional pattern: int x and int y. These two patterns look identical to the variable declarations in the deconstructing assignment. The behaviour seems pretty similar too: each of these examples deconstructs a value and assigns the component parts into variables, variables that these expressions also have the effect of declaring. Roslyn even calls these things DeclarationPatterns in its API.
However, despite the apparent similarities, they are not the same: they are faux amis. There is a very important difference. When looking at these entire statements we've seen already that the compiler will only accept the assignment statement if it can verify at compile time that a suitable deconstructor exists, whereas the positional pattern may decide at runtime that it does not match, in which case it will evaluate to false. But what is less obvious is that this pattern might perform 3 runtime checks. Suppose our Point type looks like this:
public class Point
{
public Point(object x, object y) => (X, Y) = (x, y);
public void Deconstruct(out object x, out object y) => (x, y) = (X, Y);
public object X { get; }
public object Y { get; }
}
This is admittedly a slightly curious choice—you'd normally expect a type representing a 2D point to use a numeric type for its coordinates. But in the broader scheme of things, it's not unheard of to have properties of type object to allow some flexibility of representation.
If p's static type is Point, the deconstructing assignment shown earlier will not compile, but the pattern will. And that pattern would also compile if p were of type object (or some other type that could conceivably hold a reference to a Point). It will only match if the values that the Point's X and Y properties contain at runtime have type int.
If your intention had been to state that you believe that any Point will deconstruct into two ints, and for the compiler to let you know if you are wrong (which is exactly what the deconstructing assignment example does) you will be disappointed.
But what about my original claim? How can var lead to more compile-time type checking than int? Consider these two examples, one using int:
if (p is Point (int x, int y))
{
return x + y;
}
and we saw earlier how Roslyn interprets that:
And one that is almost identical, but replacing int with var:
if (p is Point (var x, var y))
{
return x + y;
}
Here's how Roslyn sees that second one:
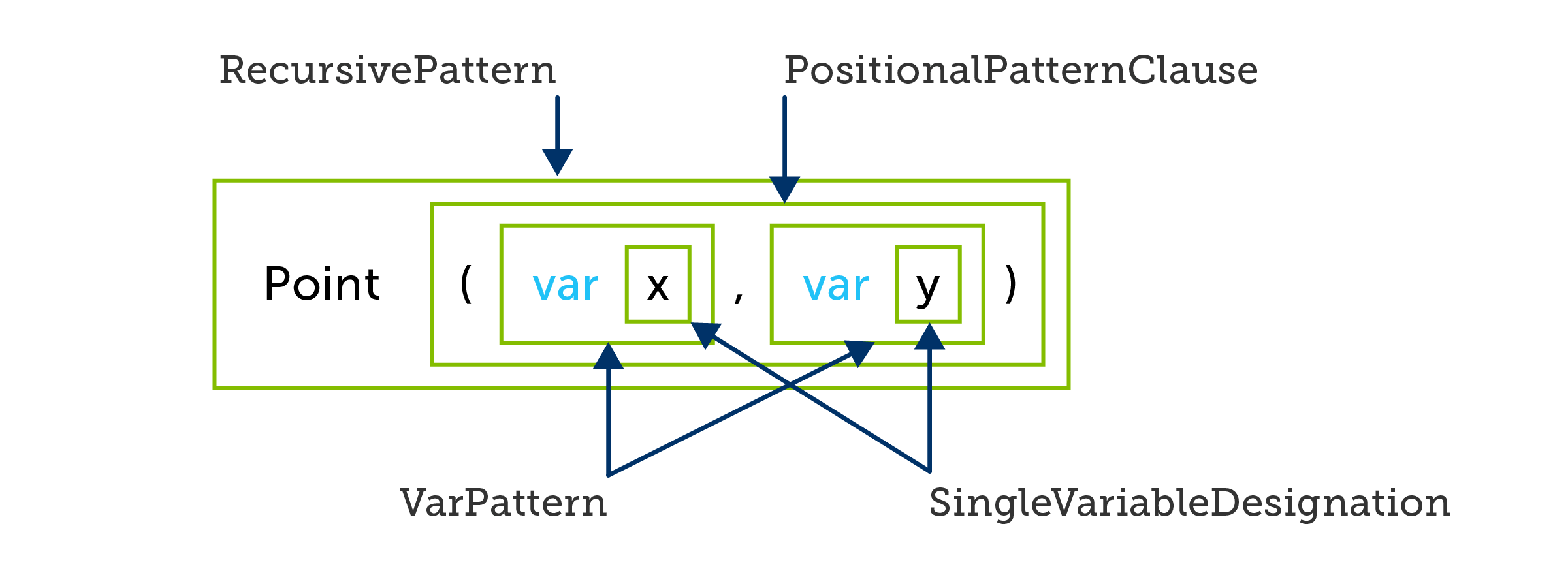
The difference is that instead of nested DeclarationPatterns (type patterns) we get nested VarPatterns. And that matters because a var pattern never performs a runtime type test. It always succeeds, and the variable it introduces has a type based on the pattern's source—the outputs of the Point deconstructor in this case.
If Point is defined as shown above, the first example compiles without error, and results in 3 runtime checks: 1) is p a Point? 2) is p.X an int? 3) is p.Y an int? The body of the if statement runs only if all three checks pass. The second pattern won't compile at all, because the compiler infers that x and y here have a static type of object, and there is no + operator that takes two objects.

If you were mistakenly under the impression that a Point was a pair of int values (and not, as it is here, a pair of objects), the example using var will detect your mistake at compile time, but the example using int will not. (And worse, not only does it defer the check until runtime, if the type checks for int fail, they do so without error—the pattern will just evaluate to false, and the body of the if statement will not run.)
If you see a type pattern on its own, that behaviour is not surprising:
if (p.X is int x)
{
return x + 10;
}
Here it is obvious that this will test p.X at runtime to see if it is an int. This is clear because the pattern follows immediately after the is keyword, so if you just read the code out loud, you get something resembling a description of how it behaves. But it's a good deal less obvious that when you have a recursive pattern, each nested pattern can add its own runtime check. And it might not even be obvious that you're looking at nested patterns at all in cases such as the positional pattern with two nested type patterns shown above, given how much the code resembles a deconstructing assignment (in which the exact same text does not constitute a pair of nested patterns).
To be clear, I'm not saying that the C# compiler is getting anything wrong here. It's just potentially surprising because deconstructing assignments and positional patterns are faux amis: they look very similar, but that similarity can mislead you. It's also slightly frustrating: I really want to be able to say "test whether this is a Point, and if it is, deconstruct it into the pair of int values I believe it to be. Please tell me if I'm wrong to believe that." And I can do that:
if (p is Point pt)
{
(int x, int y) = pt;
return x + y;
}
I just can't do it without introducing an extra assignment expression. And I would argue that to someone who's not a language wonk, it might not be immediately obvious why that doesn't mean the same thing as this:
if (p is Point (int x, int y))
{
return x + y;
}
particularly since they would in fact mean the same thing if you were correct in your assumption that Point deconstructs into a pair of int values. These examples are only different in the case where you're wrong: one compiles, and the other points out your mistake.
Conclusion
It probably sounds like I'm unhappy about the new patterns added in C# 7 and 8, or with the general direction of the language. In fact, overall I like the new pattern features, not least because I've done some work in recent years in Haskell and F#, both of which have extensive pattern matching, and it's something I've wanted every time I come back to C#. (That and algebraic data types.) I have made extensive use of the patterns that were added in C# 7 and I'm looking forward to being able to use the new ones in C# 8.
I wrote these articles partly just to understand what was going on. I was really quite surprised by the initial discovery, but having worked it though I see how it ended up that way, and don't have any ideas on how to fix it. Nonetheless, having seen the deeper issue here, I thought it was worth sharing, because it's useful for C# developers to be aware of the potential problems.
That said, there is one positive principle I would take from this: I would recommend making things that are different look different whenever possible. Many years ago, the designers of the C programming language took the decision to attempt to make function declarations resemble the syntax for function calls—an attempt to be helpful that ended up creating faux amis. Although it makes simple functions easy to read, it ended up creating various complications that are with us to this day in C family languages. Array declaration syntax in C# is another example—pop quiz: when constructing a multidimension jagged array in C#, does the array size go here new int[10][] or here new int[][10], and why? I can never remember which it is. If arrays used the same syntax as the other type constructors introduced later, e.g. if we wrote new array<array<int>>(10), I would find that much easier to comprehend.
The lesson I learn from all this is: make different things look different. And this is really just a special case of a broader principle: code should do what it looks like it does.



