Introducing DuckLake: Lakehouse Architecture for the Modern Era


TL;DR:
DuckDB Labs has announced DuckLake, a new open lakehouse format that reimagines data lake architecture by storing metadata in a traditional database rather than complex file hierarchies. This approach provides true ACID transactions across multiple tables, dramatically improved performance for small changes, built-in encryption, and simplified operations. Available as an open-source DuckDB extension, DuckLake represents a return to proven database principles while maintaining the scalability and openness that make data lakes valuable.
Series Recap: From Single-Node to Distributed
In our previous DuckDB Series, we've explored how DuckDB embodies the "data singularity" trend: the point where single-node processing power meets most analytical workload requirements. We covered DuckDB's technical innovations, its integration with Microsoft Fabric, and the philosophical shift it represents in data processing. But one question has remained: how do we scale DuckDB beyond single-user scenarios while maintaining its elegant simplicity?
The answer has arrived in the form of DuckLake, a new lakehouse format created by DuckDB Labs that extends the "data singularity" concept into multi-user, enterprise-scale scenarios.

DuckLake was recently announced on YouTube by DuckDB creators Hannes Mühleisen and Mark Raasveldt. We've studied the announcement, accompanying blog and documentation in detail and experimented with the DuckLake extension which has been launched for DuckDB. Our thoughts are captured in this series of blogs.
Important Note: As of June 2025, DuckLake is experimental software. While extensively tested, it's not yet production-ready and is expected to mature throughout 2025.
The Evolution: From Databases to Files and Back Again!
DuckLake represents a fascinating return to database principles after years of file-based architectures that have led to compromises. To understand its significance, we need to examine how the data lake ecosystem evolved and where it went wrong.
The Parquet Foundation: What Works Well
At the heart of modern data lakes lies Parquet — a columnar storage, self-describing, compressed file format that's perfectly optimized for its intended use case: storing large volumes of tabular data on object storage such as AWS S3 or Azure blob. As the DuckDB Labs team notes, "Parquet is the interchange format of choice for high performance analytics," it represents a massive leap forward from CSV-based files for a range of reasons, not least the fact it encodes schema metadata (column names and data types) and adopts columnar storage which enables effective compression of data.
Parquet excels at what it was designed for, but it has fundamental limitations:
- Files are "write once" — they are not designed for updates - if you want to update the data you need to re-write the file. Appending data works (just add a file with the new rows and leverage globbing), but deletes require more complex workarounds.
- Schema evolution and enforcement are problematic and typically requires data to be re-written.
- Time travel and ACID principles become extremely difficult.
The File-Based Metadata Trap
With Parquet providing the means of storing the raw data, the missing piece has always been the metadata layer — something that directs users to the specific Parquet files containing the data they need. Layers of complexity have built up over time to unlock database-like features over Parquet files.
The Hive Metastore began the evolution of moving from a data lake to lakehouse architecture. More recently, the Iceberg and Delta table formats have emerged to address more of the challenges around managing metadata and bringing database-like features to a lakehouse such as schema enforcement, schema evolution, transactions and time travel.
However, Iceberg and Delta share some common limitations: they are table formats so they solve these challenges at the table level - i.e. features such as transactions and time travel can't be applied across multiple tables in an atomic way.
They have also tried to solve metadata management problems by introducing an additional layer of files to manage that metadata, for example Delta format relies on a set of JSON files in the _delta_log folder to maintain state. This file-centric approach begins to hit the inherent limitations of object store technologies such as "eventual consistency". This requires many expensive round trips to write data and update metadata files.
Scaling up the velocity of operations on this lakehouse architecture begins to hit performance bottlenecks, when making small frequent updates. To overcome these challenges file based meta data is now being augmented with cataloguing services such as 'Snowflake's Polaris over Iceberg' or 'Databricks Unity Catalogue over Delta'. So we end up with another layer in the architecture, adding further abstraction and complexity.
As Mühleisen puts it:
"Existing lakehouse formats, in our opinion, have bad aesthetics."
By this, he means the complexity that has been developed to enable lakehouse architectures to evolve, whilst avoiding the use of database technology at all costs.
Here's the irony: both Iceberg and Delta eventually had to add database-backed catalog services to solve consistency problems. They spent enormous effort trying to avoid databases, only to end up requiring them anyway — but never revisiting prior design decisions to streamline their approach. This is where DuckLake comes in!
Mapping the evolution
We've used a Wardley Map to illustrate this evolution over the last 25 years from traditional relational database management system (RDBMS) based warehouse, to data lake, then lakehouse and more recently where DuckLake is seeking to take the architecture.
The value chain of each era of technology is mapped in primary colours (see key on left side of map) with dotted lines showing how discrete layers in the value chain have evolved over time.
The natural evolution of all technology from genesis to commodity is tracked by the X-axis of the Wardley Map, making it a good way of building an understanding of what is at play and how DuckLake represents a new generation of lakehouse architecture by building on the best innovations from the past.
There are three key points highlighted on the map:
A - data lakes are characterised by the separation of storage from compute - it enabled organisations to leverage cheap commodity storage (e.g., Amazon S3, Azure Blob) and compute (e.g., Spark clusters) and to scale these independently. It also allowed greater flexibility around the veracity of data types that could be stored and processed by bringing different compute engines to work with the data stored on the lake based on the nature of that data. Although it is interesting to note that Microsoft have recently reversed this trend with OneLake because they've decided to adopt the capacity charging model which binds use of storage and compute back together.
B - DuckLake consolidates metadata management - DuckLake is simplifying the lakehouse architecture by consolidating all metadata management currently distributed of across multiple layers into a single database. This removes the bottlenecks associated with file based metadata management and enables DuckDB to operate as a "multi-user" platform.
C - Data Singularity - as an "in process" query engine, DuckDB is able to exploit the full capabilities of modern compute hardware. It supports multiple development tools and operating systems, enabling it to be leveraged on the vast majority of modern compute hardware empowering users with a slick local development experience and enabling multiple deployment scenarios whether that be on-prem, in the cloud or at the edge.
We can see from the map how DuckLake goes full circle by bringing many of the features we took for granted on traditional RDBMS based warehouse platforms into the modern cloud native era by exploiting shifts in the lower levels of the value chain and simplifying others.
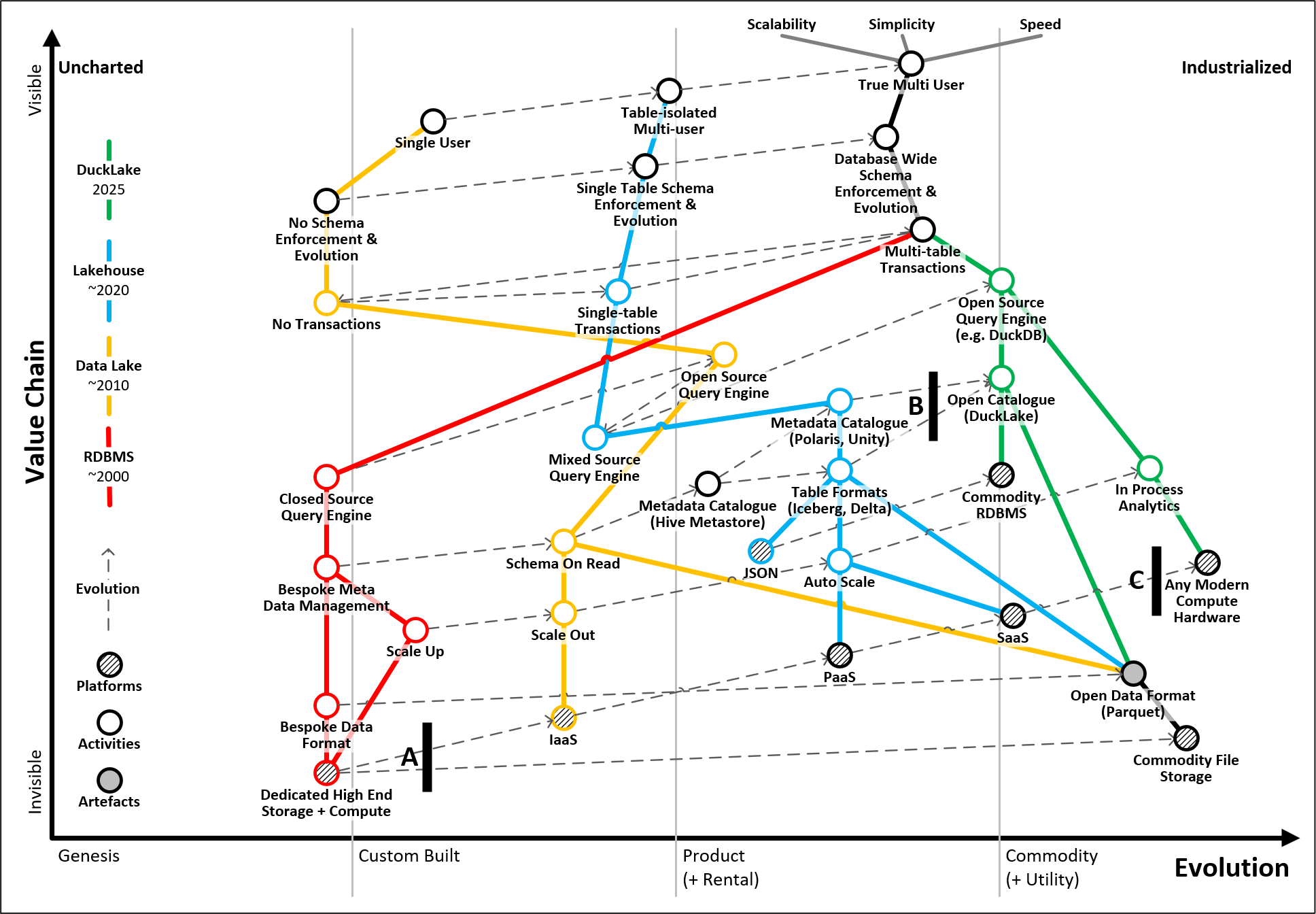 'Wardley Map showing evolution from traditional RDBMS warehouse through data lake and lakehouse to DuckLake'
'Wardley Map showing evolution from traditional RDBMS warehouse through data lake and lakehouse to DuckLake'DuckLake: A Convention, Not a Platform
It's crucial to understand that DuckLake is not a specific platform or codebase — it's a standard. As Mühleisen emphasizes:
"DuckLake is not a DuckDB specific thing, it's a standard, a convention [that will enable you to] manage large tables on blob stores that are stored in formats like parquet by using a database [for the metadata]."
DuckLake is built on established, proven standards:
- DuckLake Interface - standard SQL for all operations.
- Commodity RDBMS - an ACID-compliant database, for storing metadata (PostgreSQL, SQLServer, Oracle, MySQL, SQLite, DuckDB itself).
- Parquet files - the open standard for storage of tabular data for analytics workloads for storing raw data.
- Commodity file storage - any common platform that can act as an object store (Amazon S3, Azure Blob, Google Cloud Storage, local filesystem, etc.).
From an infrastructure perspective, you only need to pick two commodity technologies: a suitable RDBMS and a file storage platform — both of which are already prevalent in many organisations. So adoption of the underlying infrastructure which supports DuckLake should not present a barrier to most organisations.
We've created another Wardley Map to illustrate the DuckLake in more detail. It shows DuckLake as a standard which can be implemented by any client tool which needs to perform CRUD interactions with a DuckLake lakehouse. The standard describes the metadata schema and the SQL based interface for interacting with the lakehouse. The standard builds on commodity relational database management system (RDBMS) and commodity storage.
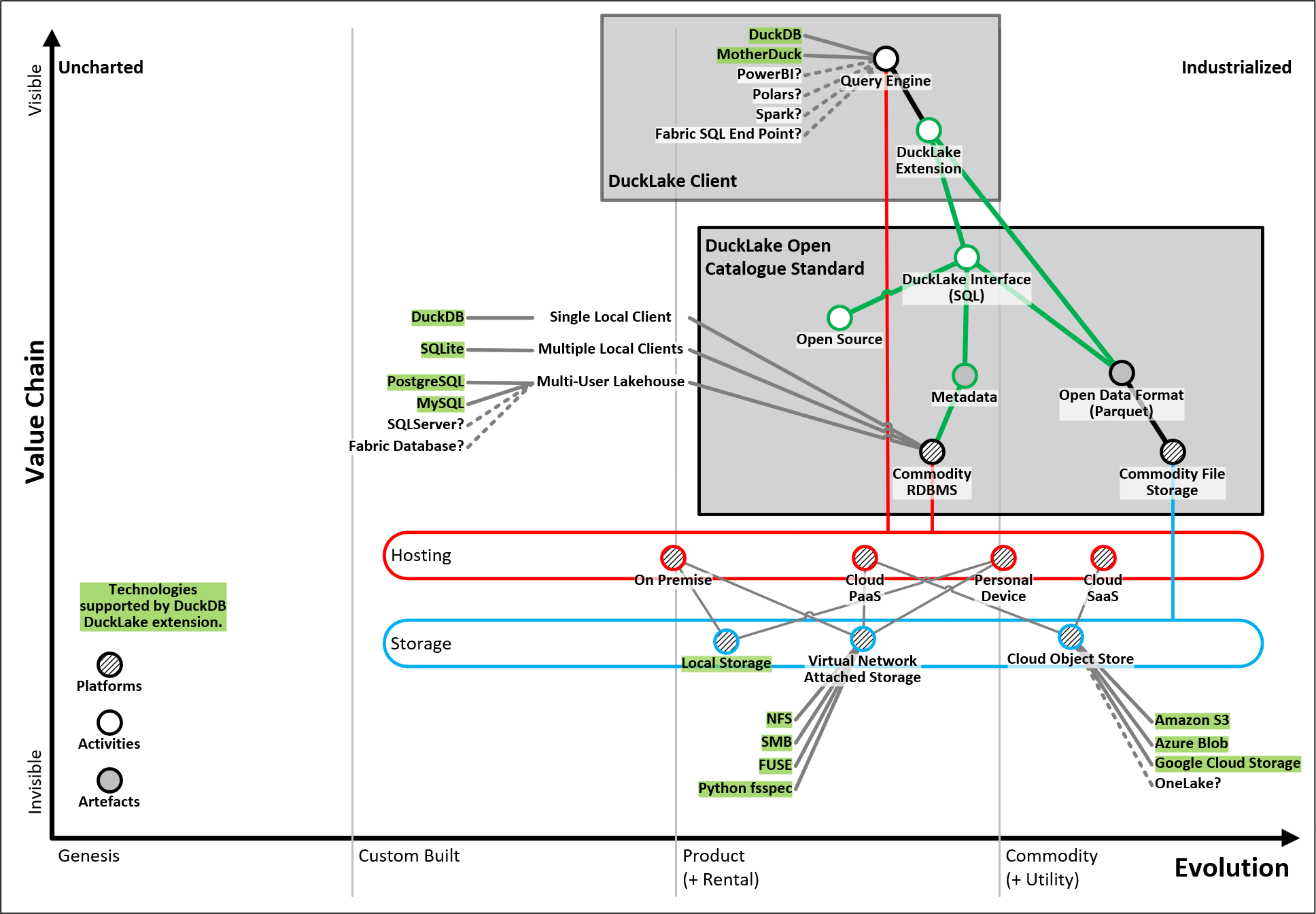 'Wardley Map illustrating the DuckLake architecture in more depth'
'Wardley Map illustrating the DuckLake architecture in more depth'
The map highlights the technologies currently supported by the DuckLake extension for DuckDB, but technologies could also be used to implement a lakehouse which adopts the DuckLake standard. The DuckLake extension for DuckDB is the first example of a client for DuckLake, but other vendors, open source tools and platforms could also interact with DuckLake as a client. Given that DuckLake is an open standard which is simple to implement, we could imagine a heterogeneous environment where many different "DuckLake client" implementations are interacting with a DuckLake lakehouse.
This simplicity enables remarkable flexibility. You can start with a fully local setup (DuckDB + local files) and seamlessly transition to cloud-scale architecture (for example, PostgreSQL + S3) without changing your application code. The choice of technology stack becomes a deployment detail rather than an architectural constraint.
DuckLake: An Open Catalog Format
Another crucial distinction is that DuckLake is a catalog format, while Iceberg and Delta are table formats. As Raasveldt explains:
"DuckLake is not necessarily a direct replacement for Iceberg or Delta alone. It's a replacement for the whole lakehouse stack: it's a replacement for 'Iceberg + Polaris' or 'Delta + Unity'. It replaces the whole stack and it can do everything that that stack can do."
This is a significant claim given the traction that platforms such as Snowflake, Databricks, Google BigQuery and Microsoft Fabric have gained in the data platform market.
Addressing the Scale Question
The inevitable question is "does it scale?". The answer lies in understanding what DuckLake is actually scaling:
- It does not store data in the RDBMS — only the metadata. The exception being data inlining.
- Metadata is roughly 5 orders of magnitude smaller than your actual data: a petabyte of Parquet data requires only ~10 GB of metadata. Even at massive scale, this metadata easily fits within the capabilities of modern RDBMS systems that routinely handle terabyte-scale databases.
This approach isn't theoretical — it's how the world's largest analytical systems already work. Use of a RDBMS for metadata management is exactly how Google BigQuery (with Spanner) and Snowflake (with FoundationDB) already work. As Raasveldt notes:
"The one difference between the existing design of these hyper scale databases and DuckLake is that we have visibility. The DuckLake metadata is open, the Parquet files are open, but it's the same exact design."
Both Snowflake and Google BigQuery have a strong track record of supporting "big data" and therefore we know this architecture works at scale. DuckLake brings this proven approach to the open-source world.
Three Core Principles
DuckLake is built around three fundamental principles:
Simplicity - two required components (metadata database + storage platform). Metadata database applies standard SQL operations for all metadata operations, over a schema which is supported by any RDBMS which supports ACID transactions and primary key enforcement.
Scalability - independent scaling of storage, compute, and metadata layers. Enabling an architecture that will scale to thousands of tables and schemas, as proven by Snowflake and BigQuery.
Speed - consolidating metadata management into a database enables complex multi-table operations, eliminates multiple round trips through metadata file hierarchies. It also applies "data inlining" for small changes (more on this in part 3 of the series).
DuckLake's Philosophical Clarity
DuckLake's approach is refreshingly direct: if you need a database anyway, why not use it for more of the work?
The most compelling aspect isn't the technology itself — it's the philosophical clarity. After years of increasingly complex workarounds to avoid databases, DuckLake simply acknowledges what the industry learned anyway: metadata management is a database shaped problem that requires a database solution. Specifically, databases provide the fundamental building blocks that lakehouse formats have been painfully reimplementing with files:
- ACID transactions for consistent multi-table operations.
- Optimistic concurrency control with automatic conflict resolution for safe multi-user access.
- Indexing and query optimization for fast metadata lookups across millions of snapshots.
- Constraint enforcement (like PRIMARY KEY violations) for elegant conflict detection.
- Mature durability guarantees backed by decades of proven reliability.
Rather than building yet another custom metadata management system in files, DuckLake leverages these battle-tested database primitives and focuses innovation on layer where it's actually needed.
Strategic Implications for Enterprise Data Architecture
DuckLake represents another important milestone in data architecture evolution. Rather than revolutionising from scratch, it elegantly combines proven standards (SQL and Parquet) in a simplified architecture that addresses the limitations and "bad aesthetics" of existing approaches.
As we continue exploring the intersection of modern hardware capabilities and analytical workloads, DuckLake extends the "data singularity" concept embraced by DuckDB into multi-user scenarios — enabling thousands of DuckDB instances to interact with a shared lakehouse, coordinating through elegant, scalable, database-managed metadata.
For organizations evaluating their data lake strategy, DuckLake offers several compelling advantages:
Simplified Infrastructure: only two technology choices to make: RDBMS and object storage. Both are commodity infrastructure with mature operational practices.
Proven Scalability: based on architectures already running at massive scale. The DuckLake can handle thousands of transactions per second, across hundreds of concurrent users.
Open Standards: full visibility into both data and metadata. No vendor lock-in or proprietary formats.
Evolutionary Path: compatible with existing formats, enabling gradual migration and experimentation.
Development to Production Continuity: The same DuckDB code that works on your laptop scales directly to enterprise infrastructure.
We'll explore these features in more detail and the future impact of these capabilities in Part 3 - DuckLake in Perspective.
Available Today
DuckLake isn't just a specification — it's available as a DuckDB extension starting with version 1.3.0. Installation is characteristically simple:
INSTALL ducklake;
What's Next in Our Series
In Part 2 - DuckLake in Practice, we'll move from theory to practice with a comprehensive hands-on tutorial. We'll walk through creating your first DuckLake instance, demonstrate core operations like table creation and data manipulation, explore the file organization, and show you how snapshots and time travel work in practice. Whether you're a data engineer wanting to experiment with DuckLake or an architect evaluating its capabilities, Part 2 will give you the practical foundation you need.
Stay tuned as we dive deep into implementing DuckLake and discover how elegantly it translates theory into practice.



