Creating Quality Gates in the Medallion Architecture with Pandera


Data validation is a critical step in ensuring the quality and reliability of your data pipelines. In this article, we'll explore the role of data validation within the medallion architecture, how to use Pandera to validate data effectively, and cover practical strategies for handling data validation failures.
What is data validation?
What is data validation? The process of determining whether data is valid.
What does it mean for data to be valid? Data is valid when it meets the expectations that have been agreed upon. So it's a question of "what you get versus what you expect".
What sorts of expectations do we typically have?
- Schemas – is the data in the correct shape (including column names, data types, nullability)?
- Constraints – does the data adhere to pre-defined constraints?
- Uniqueness – should a given field contain distinct values?
- Primary and foreign key constraints
- Anomaly detection – outliers and unusual patterns
- Basic range checks on date and numeric type columns
- Statistical techniques for identifying outliers and checking distribution of data
- Sensitivity – Is the data expected to contain personally identifiable information (PII), for example?
- Quality – validity is a binary thing – either all expectations are met or they're not, whilst quality provides a continuous measure. If we treat quality as a quantity expressed as a percentage, you can think of valid data as having quality of 100%, whilst non-valid data has a score of somewhere between 0% and 100%. Quality may be measured by different metrics, like percentage of complete records and timeliness. Expected data quality may be captured in SLAs of data providers as acceptable thresholds, e.g. no more than 0.1% of records incomplete.

There are also the sorts of expectations that are not based on properties of the inidvidual data records, but rather of the batch of data in question. These include: the size of the batch, file format, and encoding. Then there are expectations of the source systems that produce the data, like the availability (can you only query the source system at a certain time of day?), update frequency, retrieval mechanism (REST endpoint, SFTP, USB stick by post, etc), and how much data can be requested (rate limits).
The expectations of data coming from source systems are arguably the most important. These expectations should be captured in data contracts – human readable documents, representing an agreement for how data should be exchanged between both sides: producers (i.e. owners of source systems) and consumers. The actual validation process is then a software-based implementation of the data contract.
Now we have established what data validation is, next let's look at why you should bother doing it.
Why bother doing data validation?
Invalid data is bad news for consumers. Typically the consumers of data are human beings – they use it to make decisions. If the data is invalid then those people are misinformed. Misinformed people means misinformed decisions – and that results in bad outcomes – loss of revenue, reputation damage, etc.
Consider the following scenario. You have a dashboard consuming data from a handful of database tables. You're not doing anything to validate the data before it hits the dashboard visuals. How can you be sure the report does not contain inaccurate or nonsensical data?
Perhaps it's a CRM dashboard, and for your use case the age of customers is a particularly significant indicator. How would negative or unrealistically old ages impact the story depicted by your dashboard? It would certainly skew aggregate calculations like averages and variations, and could consequently mislead decision makers.
Poor decision making is not the only consequence. Invalid or otherwise poor quality data may lead people to lose trust in the data and the whole report, and – rightly or wrongly – potentially the entire data platform and the people who built it. This obviously has broader implications. The erosion of trust could cause a "shadow data" approach, where data consumers decide to get or generate data themselves outside of the organization's data governance and security processes, leading to a mess of disparate data sets as well as security and governance challenges.
Malformed data may cause code to error and throw exceptions – resulting in failed pipelines, report visuals failing to render, etc. You want to anticipate this to avoid user frustration due to downtime, and avoid wasting time and money on troubleshooting and remediating the problem.
Validation is particularly important when processing data coming from the outside world which is messy and complex, and is something over which you typically have little or no control. You need to put protections in place to prevent bad data from polluting your data products.
If you pay to be provided with data, the commercial agreement will likely include SLAs. You will need to validate data to measure, enforce and report these.
So, how does this work in practice?
Data validation in the medallion architecture
Whilst data validation is a critical component of any data platform, regardless of its design, one common approach is to follow the medallion architecture. This blog post will be discussing data validation in the context of the medallion architecture.
The medallion architecture is a data lakehouse data design pattern developed by Databricks. It organises data into layers – Bronze, Silver and Gold, with the goal being to progressively improve the structure and quality of data as it flows through each layer: Bronze => Silver => Gold.
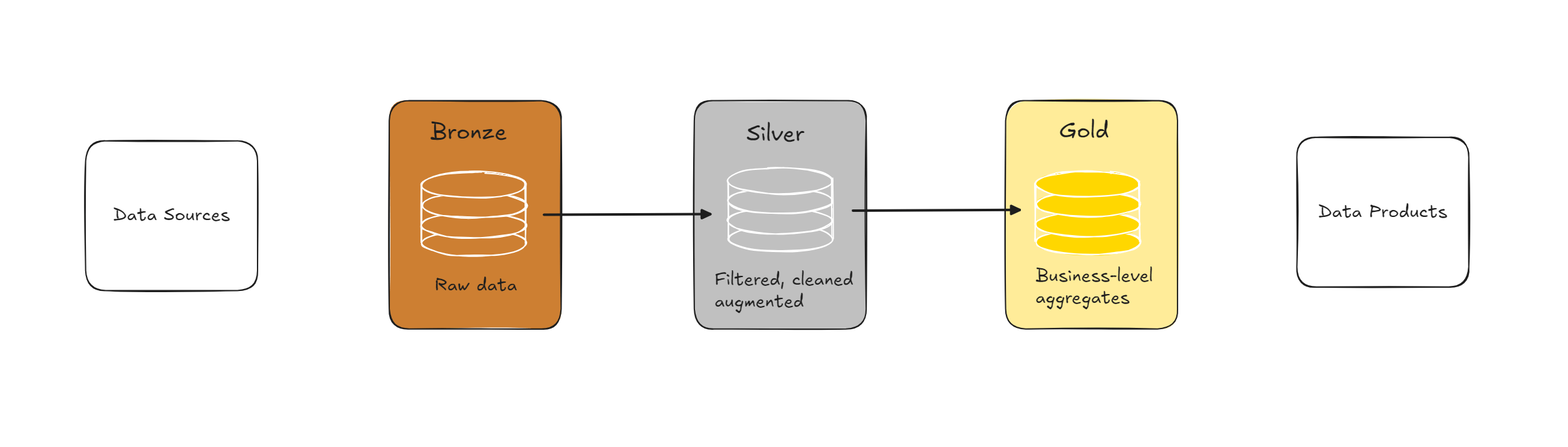
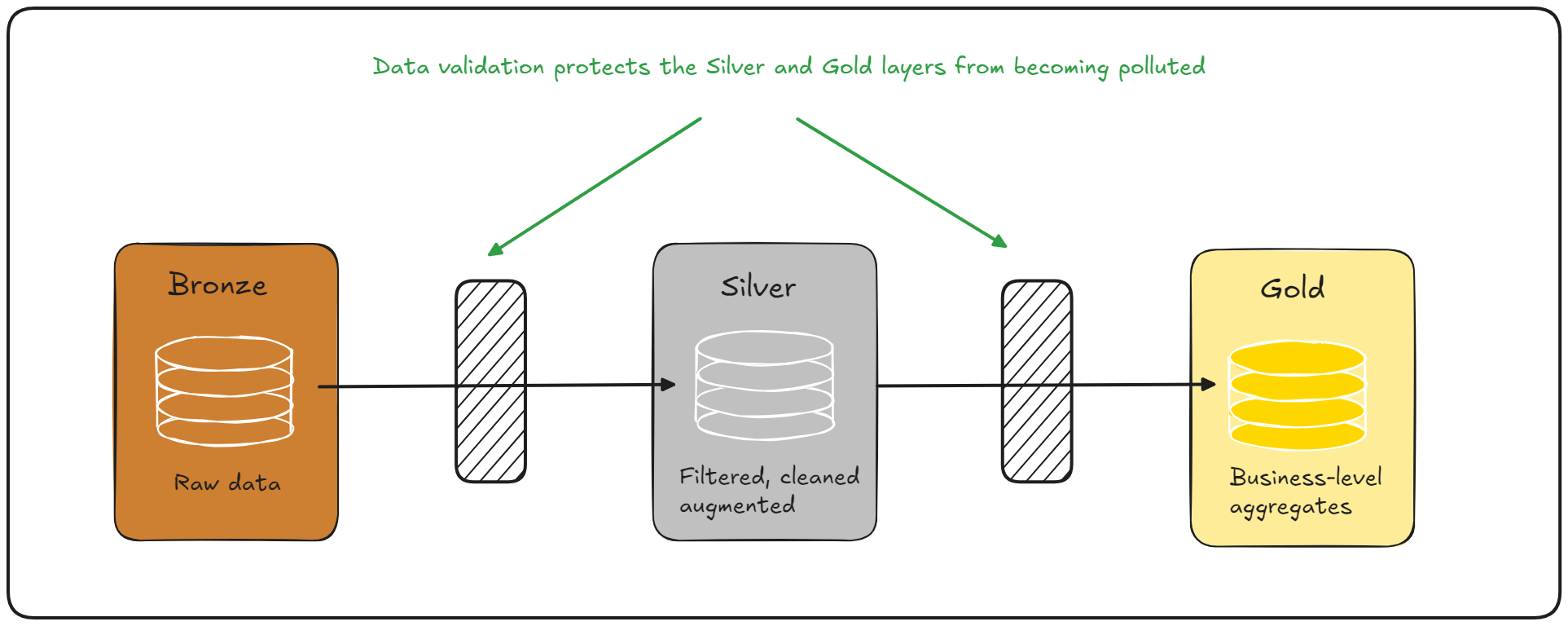
To see how data validation fits into the medallion architecture, let's consider each layer in turn.
Bronze
The Bronze layer is the raw data layer, it's supposed to be the landing zone for data from source systems. Data should exist in Bronze as it exists in the source system – no transformations or schema enforcement. Whilst, therefore, it doesn't make sense to validate the individual records at this stage, expectations of the batch/file should be validated before landing in Bronze. Does the file conform to the expected naming standard? Is it in the expected format and encoding? Is the file size in the expected range? And so on.
Whilst not strictly part of the medallion architecture model, some situations may call for a pre-bronze "quarantine" zone to provide an extra layer of protection to prevent malicious or corrupted files from being persisted into the lakehouse. This zone could be used to virus scan files and perform any necessary pre-processing, like unzipping compressed files, for example.
Silver
The Silver layer should contain cleansed and structured data, organised into tables. It's supposed to enable self-service analytics by being a reliable source of data which analysts, data scientists, etc, can use to begin exploring trusted data and start building a gold layer to drive downstream products.
The Silver layer should provide an organisation-wide view of all data. To enable a shared and consistent understanding of the data, naming should align with the ubiquitous language of the organisation; validation of naming could be driven by a data dictionary.
It is the route from Bronze to Silver where you're dealing with the messiness of the outside world. It is therefore where data validation is most important — you need to guard against the messiness.
Gold
The Gold layer is the final layer, where business logic and aggregations are applied. The tables in the Gold layer should be ready for consumption (trustworthy, valid and high quality) and designed for a specific use case. It may be the source for a specific analytical report, for example.
Whilst validating data between Silver and Gold is less of a concern than between Bronze and Silver, it's still important. Data in Silver tables should already be valid, but could become invalid afterwards. Say, for example, the schema of a table in Silver on which your Gold layer depends has been changed by a different team, which breaks your Silver => Gold pipeline. This is less of a concern when using data formats in Gold that support schemas, like Delta, because schemas are automatically enforced. But consider a situation in which a developer introduces a bug in the Silver => Gold pipeline code. This could invalidate data in a way that didn't break schemas, for example if a function for calculating ages from DOBs produced negative age values. This is the sort of thing that should be covered by unit tests, but data validation would add an extra level of protection at runtime.
However, with all of that being said, most data validation problems exist in data coming into your platform from the outside world, which is why Bronze => Silver data validation is most crucial.
Data lakehouse architectures are a combination of the data warehouse and data lake architectures. The thing that makes them possible is the existence of data formats that support ACID transactions, as these enable the merging of data warehouse features (reliability and consistency) with the scalability and cost effectiveness of data lakes. An example of such a format is delta lake, which is an extension of the parquet file format developed by Databricks. Delta integrates deeply with Apache Spark APIs, making PySpark the go-to processing engine for moving data across the layers of the medallion architecture.
To maintain clean Silver and Gold layers while using PySpark, we need a Python-based tool capable of working with PySpark data structures. One such option is Pandera.

Data validation with Pandera
Pandera is a Python library designed for performing data validation on DataFrame structures. (I covered it in an earlier blog post in which I compared it with another validation library called Great Expectations). It is therefore best suited for validating the first sort of expectations I mentioned in the introduction – those of individual records. As the name suggests it's centred around Pandas, but it has support for DataFrame types from other libraries, including PySpark and Polars. Validation in Pandera is based around the DataFrameSchema object, which is like a relational database table schema, allowing you to define expected names, data types and nullability for columns.
The following example demonstrates how to validate a PySpark SQL DataFrame using Pandera. First it creates a PySpark DataFrame, df, from some dummy customer data, and afterwards defines a Pandera schema, ValidationSchema. The schema is defined using the class-based API, it defines expected columns as class attributes, expected types (PySpark SQL data types) using the type annotation syntax, and nullability through the Field type. Notice the schema class derives from DataFrameModel, a type imported from the Pandera.pyspark namespace; this makes the schema use the PySpark backend for Pandera.
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
import pyspark.sql.types as T
import Pandera as pa
from Pandera.pyspark import DataFrameModel, Field
from datetime import datetime
spark = SparkSession.builder.getOrCreate()
data = [
("Alice", 34, "London", datetime(2021, 5, 21), "alice@hotmail.com"),
("Bob", 45, "Liverpool", datetime(2020, 8, 15), "bob@gmail.com"),
("Cathy", 29, "Glasgow", datetime(2019, 11, 30), "cathyoutlook.com")
]
columns = ["Name", "Age", "City", "registration_date", "email"]
df = spark.createDataFrame(data, columns)
class ValidationSchema(DataFrameModel):
Name: T.StringType = Field(nullable=False)
Age: T.LongType = Field(nullable=False)
City: T.StringType = Field(nullable=False)
registration_date: T.TimestampType = Field(nullable=False)
email: T.StringType = Field(nullable=False)
We can then validate the DataFrame against the schema by calling the validate class method on the schema class, passing in the DataFrame. The object returned from validate is a PySpark DataFrame containing the original data, but extended to hold validation results.
validated_df = ValidationSchema.validate(df)
print(validated_df.show())
+-----+---+-------------+-------------------+-----------------+
| Name|Age| City| registration_date| email|
+-----+---+-------------+-------------------+-----------------+
|Alice| 34| London|2021-05-21 00:00:00|alice@hotmail.com|
| Bob| 45| Liverpool|2020-08-15 00:00:00| bob@gmail.com|
|Cathy| 29| Glasgow|2019-11-30 00:00:00| cathyoutlook.com|
+-----+---+-------------+-------------------+-----------------+
The validation results are exposed via the Pandera attribute on the resulting DataFrame. The errors object is empty in this case because the DataFrame is valid against the schema.
Pandera_errors = validated_df.Pandera.errors
print(Pandera_errors) # prints: {}
It's important to understand how Pandera surfaces validation errors. There's an optional boolean parameter on the validate function named lazy, which when False causes Pandera to raise an exception immediately after discovering a validation problem. For PySpark SQL DFs, the default value is True, and in this mode Pandera records all validation errors without raising an exception. The benefit of validating lazily (lazy=True) is that you get to see all validation problems, whereas with eager evaluation (lazy=False) you only get to see the first. Let's see an example of this by introducing some validation issues into the data.
The next example introduces some schema violations by changing a value in the Name column to None and converting the Age values to floating point numbers.
data = [
("Alice", 34.0, "London", datetime(2021, 5, 21), "alice@hotmail.com"),
(None, 45.0, "Liverpool", datetime(2020, 8, 15), "bob@gmail.com"),
("Cathy", 0.0, "Glasgow", datetime(2019, 11, 30), "cathyoutlook.com")
]
df = spark.createDataFrame(data, columns)
df_validated = ValidationSchema.validate(df)
df_errors = df_validated.Pandera.errors
print(json.dumps(dict(df_errors), indent=4))
{
"SCHEMA": {
"SERIES_CONTAINS_NULLS": [
{
"schema": "ValidationSchema",
"column": "Name",
"check": "not_nullable",
"error": "non-nullable column 'Name' contains null"
}
],
"WRONG_DATATYPE": [
{
"schema": "ValidationSchema",
"column": "Age",
"check": "dtype('LongType()')",
"error": "expected column 'Age' to have type LongType(), got DoubleType()"
}
]
}
}
This time the errors object contains some validation error messages. It correctly reports that the Name column contains a null value when it shouldn't, and that the Age column contains DoubleType type values whereas the schema expects LongType values.
In this form Pandera schemas are basically that – schemas – objects allowing you to define expected column names, data types and nullability. But the power of Pandera schemas comes from the ability to define checks. A check is a function that implements a specific expectation for a specific column. Logically a check function takes a value from the column as input and returns True if the expectation is met and False otherwise. And since they're functions, you have complete flexibility – you can implement almost any expectation this way.
Whilst you can define your own custom check functions, the library comes with lots of built-in checks that cover common expectations. The following example uses a total of three built-in checks: lt and gt are used to demand that values in the Age column fall within the expected range: greater that 17 and less than 125; isin is used to check that values in the city column match one of the values in the list of cities. It also defines a custom check function, regex_check, to validate that values in a given column match a given regex pattern, which we use to check that values in the email column are valid email addresses.
from Pandera.extensions import register_check_method
data= [
("Alice", 34, "London", datetime(2021, 5, 21), "alice@hotmail.com"),
("Bob", 45, "Liverpool", datetime(2020, 8, 15), "bob@gmail.com"),
("Cathy", 0, "Lonpool", datetime(2019, 11, 30), "cathyoutlook.com")
]
df = spark.createDataFrame(data, columns)
# Register a custom check method
@register_check_method("regex_check")
def regex_check(pyspark_obj, *, regex_pattern) -> bool:
cond = F.col(pyspark_obj.column_name).rlike(regex_pattern)
return pyspark_obj.dataframe.filter(~cond).limit(1).count() == 0
cities = ["London", "Liverpool", "Manchester", "Birmingham", "Glasgow", "Edinburgh"]
EMAIL_REGEX = r"[^@]+@[^@]+\.[^@]+"
class ValidationSchema(DataFrameModel):
Name: T.StringType = Field(nullable=False)
Age: T.LongType = Field(nullable=False, gt=17, lt=125)
City: T.StringType = Field(nullable=False, isin=cities)
registration_date: T.TimestampType = Field(nullable=False)
email: T.StringType = Field(nullable=False, regex_check_new={"regex_pattern": EMAIL_REGEX})
df_validated = ValidationSchema.validate(df)
df_errors = df_validated.Pandera.errors
print(json.dumps(dict(df_errors), indent=4))
{
"DATA": {
"DATAFRAME_CHECK": [
{
"schema": "ValidationSchema",
"column": "Age",
"check": "greater_than(17)",
"error": "column 'Age' with type LongType() failed validation greater_than(17)"
},
{
"schema": "ValidationSchema",
"column": "City",
"check": "isin(['London', 'Liverpool', 'Manchester', 'Birmingham', 'Glasgow', 'Edinburgh'])",
"error": "column 'City' with type StringType() failed validation isin(['London', 'Liverpool', 'Manchester', 'Birmingham', 'Glasgow', 'Edinburgh'])"
},
{
"schema": "ValidationSchema",
"column": "email",
"check": null,
"error": "column 'email' with type StringType() failed validation None"
}
]
}
}
This schema has correctly detected the issues. The value 0 in the age column is less than 17, "Lonpool" is not a value in the provided list of cities, and the email value in the final row is missing an @ and consequently isn't a valid email.
Making use of Pandas
Whilst PySpark SQL is the DataFrame technology of choice in the medallion architecture due to its deep integrations with Delta lake, it can often be useful to the initial load and validation steps with Pandas DataFrames before converting to PySpark SQL to write to delta tables. There are a few reasons for this.
First, loading small datasets into Pandas is usually much faster than with PySpark. Second, Pandas has much better support for loading data from Excel sheets. And third, Pandera for Pandas DFs is more mature than for PySpark SQL DFs. For example, there's a useful built-in check called unique for validating that the values in a column are distinct, which until recently was not available for PySpark SQL DFs. Also, you'll notice that the validation messages in the previous PySpark examples don't identify the individual invalid records, this is often very useful when troubleshooting and is something available for Pandas DF (as you'll see shortly). The good news is that the feature gap seems be narrowing. You can refer to their supported features matrix and check out raised issues for the details.
The next example demonstrates the sort of pattern you might use when loading data from Bronze with Pandas and afterwards writing to the Silver layer through a PySpark SQL DF.
import Pandera as pa
from Pandera import Column, Check, DataFrameSchema
import pandas as pd
from datetime import datetime
cities = ["London", "Liverpool", "Manchester", "Birmingham", "Glasgow", "Edinburgh"]
EMAIL_REGEX = r"[^@]+@[^@]+\.[^@]+"
# Define the schema with custom checks using DataFrameSchema API
customers_schema = DataFrameSchema(
{
"ID": Column(int, nullable=False, unique=True),
"Name": Column(str, nullable=False),
"Age": Column(int, Check.in_range(18, 125), nullable=False),
"City": Column(str, Check.isin(cities), nullable=False),
"registration_date": Column(pa.DateTime, nullable=False),
"email": Column(str, Check.str_matches(EMAIL_REGEX), nullable=False),
}
)
# Load data from Bronze into Pandas DF
customers = pd.read_csv("bronze/customer_data.csv")
# validate the data
def validate(schema, df):
try:
return schema.validate(df, lazy=True)
except pa.errors.SchemaErrors as e:
logging.error(f"Data validation failed: {e}")
raise Exception("Data validation failed")
customers_validated = validate(customers_schema, customers)
# If data is valid transform
customers_transformed = process_customers(customers_validated)
# Get spark schema from customers silver Pandera schema
customers_silver_spark_schema = pandera_to_pyspark_sql_schema(CustomersSilverSchema)
# Convert to Spark DF, validate and write to Silver
customers_transformed_spark = spark.createDataFrame(customers_transformed, customers_silver_spark_schema)
customers_silver_spark_schema.validate(customers_transformed_spark)
silver_data_repository.write_customers_to_silver(customers_transformed_spark)
The Pandera schema is defined using DataFrameSchema type, but we could have used the class API here too. The data now has an ID column and the schema demands that it contains distinct values by declaring unique=True. There's no need to define a custom check for the regex match here because that's available out of the box on the Check object, which can only be used in schemas defined using the DataFrameSchema type.
A custom validate function is defined to validate the Pandas DataFrame lazily. If the data is invalid, it logs any validation errors before raising an exception. In contrast to Pandera for PySpark DFs, validation of Pandas DFs is eager (lazy=False) by default. And, when evaluating lazily, Pandera performs all validation before raising an exception containing all validation errors, if there are any.
There's a mini pattern in here that can be useful. CustomersSilverSchema is a Pandera PySpark schema representing the schema of the table in Silver (I haven't shown an implementation because the details aren't important). We use a function, pandera_to_pyspark_sql_schema, to build a Spark schema from it, and then use that when converting the Pandas DF into a PySpark DF. This way, you define your medallion tables once with Pandera and they become the single source of truth. Note that if the Silver layer schema does not define any checks, then validating the Spark DF before writing to Silver is pointless because PySpark performs schema validation itself.
How your code reacts to invalid data is important. In this example we log validation errors before raising an exception to halt processing, but there are other options.
What to do when validation fails?
When responding to invalid data there are two basic goals: 1. prevent invalid data from being written to your Silver or Gold tables and 2. inform people and arm them with the information they need to resolve the issues. There are several different ways you can go about this.
The most basic is probably what the last example demonstrated: log the validation issues and raise an exception. That does the job, however people don't know an error has occurred until they check the pipeline status, and then they have to dig through the log files to figure out what went wrong. A better approach would be to push a notification to the relevant people, informing them of the problem. This could in the form of an email, or a instant message in Slack or Teams, or the like.
Another approach is to write validation errors to separate, dedicated tables. This enables reporting over the errors by surfacing the information in a more accessible form, which can be particularly useful for non-technical stakeholders.
In some scenarios in may not be necessary to completely halt the pipeline. The problematic records could be filtered out and quarantined, whilst allowing the valid rows to continue to be processed. The invalid records can be reported and re-processed later once fixed. Also, some validation issues may not be critical and only warrant a warning. You could classify validation issues by severity and handle them appropriately, for example by logging non-critical problems whilst allowing processing to continue, and only halting for critical issues.
There's a risk with logging that's worth mentioning. When logging errors, it's important to avoid including sensitive information that might be present in error messages. Error logs can often be a vulnerability point for exposing personally identifiable information (PII).
Conclusion
Valid and high quality data is essential for any successful data product. By implementing a robust data validation strategy within the medallion architecture with tools like Pandera, you can catch and handle issues early, keeping your data clean and processes efficient.



