How to access choice labels: Azure Synapse Link Dataverse with PySpark


When you export a table from Dataverse into Synapse using the Azure Synapse Link for Dataverse, the choice columns in your linked tables will display the numerical choice value. This isn't very meaningful to the end-user, what we really want to display in our choice columns is the associated text choice label. This blog post explains how to access the choice labels from Azure Synapse Link for Dataverse using PySpark.
What are choice columns in Dataverse?
A choice column, is a type of column that can be used in a Microsoft Dataverse table. In a choice column, the user can select from a set of options using a drop-down list control.

The set of options to be used within a choice column can be defined locally or globally. A local set of options can be used for a specific choice column in one table only. Whereas, a global set of options can be used by lots of choice columns in multiple tables, and will be synchronised everywhere.
Global choice columns are useful when you have a standard set of categories that can apply to more than one column across tables in your environment. If you know that the set of options will only be used in one place, use a local choice.
When defining the set of options to be used within a choice column locally, you must define both a choice label and a choice value. The choice label is the text the user sees when they use the drop-down list control for a choice column in Dataverse. The choice value is the numerical value stored behind the scenes for that particular choice option.

When you export a table from Dataverse into Synapse using the Azure Synapse Link for Dataverse, the choice columns in your linked tables will display the numerical choice value. This isn't very meaningful to the end-user, what we really want to display in our choice columns is the associated text choice label.

Where are the choice labels stored in the Azure Synapse Link for Dataverse database?
When exporting data from Dataverse using Azure Synapse Link, an OptionsetMetadata table is created in Azure Data Lake Storage Gen2. This table stores all of the local choice labels for your linked Dataverse tables in a column called LocalizedLabel. Each choice label has a corresponding Option value - this value directly maps to the numerical choice values displayed within your choice columns in your linked tables. The OptionsetMetadata table also has an EntityName column and an OptionSetName column. The values in these columns specify which linked table and choice column the choice label relates to, respectively.

Global choice labels are stored in the GlobalOptionsetMetadata table. This table has analogous columns to the OptionsetMetadata table, so a similar pattern to the example in this blog post can be followed in order to access these choice labels.
Given we have all of this information in the OptionsetMetadata table, we can use a join function in PySpark to join the OptionsetMetadata table with your linked Dataverse table and replace the numerical choice values in your linked table with the text choice labels.
Reading tables from Azure Synapse Link into Synapse Notebooks with PySpark
First you will need to read your data from the Azure Synapse Link for Dataverse database into PySpark dataframes in a Synapse Notebook. You will need to read both your linked Dataverse table with the choice columns, and the OptionsetMetadata table which contains the choice labels for all of your linked Dataverse tables.

You can do this through the implementation of the following code:
core_table_df = spark.table(f"{dataverse_db_name}.{core_table_name}")
choice_options_df = spark.table(f"{dataverse_db_name}.{choice_table_name}")
Here is an example implementation of the above code. This is how we would read in a linked Dataverse table called dv_orderdetails and the OptionsetMetadata table into a Synapse Notebook:
Note: There is an issue with parsing DateTime strings in Spark 3.0 and later versions. So, in order to be able to parse DateTime columns from Dataverse, you need to set spark.sql.legacy.timeParserPolicy configuration to LEGACY prior to reading the data.
# Can't parse Dataverse DateTime columns otherwise
spark.conf.set("spark.sql.legacy.timeParserPolicy", "LEGACY")
dataverse_db_name = "dataverse_edfreemansen"
core_table_name = "dv_orderdetails"
core_table_df = spark.table(f"{dataverse_db_name}.{core_table_name}")
choice_table_name = "OptionsetMetadata"
choice_options_df = spark.table(f"{dataverse_db_name}.{choice_table_name}")
Here are the resulting PySpark dataframes with the columns we are interested in selected:


Replacing the choice values with the choice labels
Once you have read in both your linked Dataverse table and the OptionsetMetadata table, you can replace the numerical choice values in your linked Dataverse table with the text choice labels using the following function:
def swap_choice_value_with_choice_label(core_table_df, choice_options_df, column_name, table_name, option_set_name):
# Join your core_table_df with the choice_options_df using table_name and option_set_name as additional join conditions
joined_df = core_table_df.join(
choice_options_df,
(core_table_df[column_name] == choice_options_df['Option']) &
(choice_options_df['EntityName'] == table_name) &
(choice_options_df['OptionSetName'] == option_set_name)
).drop(column_name, 'Option', 'EntityName', 'OptionSetName').withColumnRenamed('LocalizedLabel', column_name)
return joined_df
There are a number of parameters to this function, the first two are your linked Dataverse table core_table_df and the OptionsetMetadata table choice_options_df. The third parameter is the column_name. This refers to the name of your choice column within your linked Dataverse table core_table_df where you intend to substitute the numerical choice values with their corresponding text choice labels.
The final two parameters are the table_name and option_set_name. These values are used as additional join conditions to ensure that only the relevant rows in the choice_options_df are included in the join. This is necessary because the choice_options_df contains the choice values and choice labels for all choice columns in every Dataverse table you have exported via Azure Synapse Link, so we need to specify which linked Dataverse table and choice column we are doing the join on.
You can run an SQL script over the OptionsetMetadata table in Synapse, as seen at the start of this blog post, to determine the values that you need to specify as the function parameters. The table_name value can be found in the EntityName column, and the option_set_name value can be found in the OptionSetName column. These values are equivalent to the schema names for the table and column in Dataverse.
Here is an example implementation of the above code. Given we have our linked Dataverse table core_table_df and the OptionsetMetadata table choice_options_df which we have read in from the Azure Synapse Link Dataverse database, here is how we would replace the numerical choice values for the text choice labels in the dv_product column of the core_table_df:
column_name = 'dv_product' # In this example, this value matches the option_set_name value, however if you choose to define a schema for your dataframe in Synapse, the column_name value could be different to the option_set_name value.
table_name = 'dv_orderdetails'
option_set_name = 'dv_product'
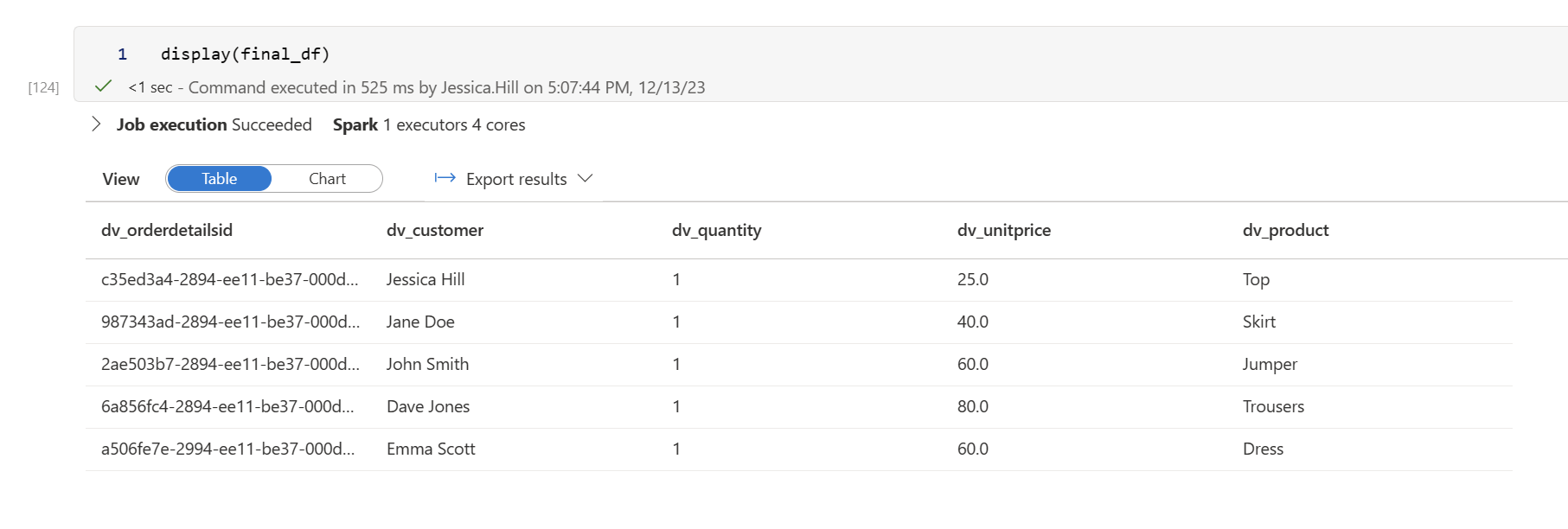
final_df = swap_choice_value_with_choice_label(core_table_df, choice_options_df, column_name, table_name, option_set_name)
And here is the resulting PySpark dataframe:
Conclusion
This blog post has explored how to access the choice labels from Azure Synapse Link for Dataverse using PySpark. It has also described the process of reading tables from an Azure Synapse Link for Dataverse database into Synapse Notebooks with PySpark. The next blog post in this series will explore how to access and transform choice labels in a similar manner using T-SQL through SQL Serverless and by using Spark SQL in a Synapse Notebook.