Big Data LDN: highlights and how to survive your first data conference


I had the chance to attend this year's Big Data LDN conference. Here are some of the highlights from the sessions I attended and some tips to survive your first in person conference!
Data Mesh
Data mesh was by far the most talked about topic in the event. First, it was introduced and defined by Zhamak Dehghani in her talk “Rewire for Data Mesh”, where she covered the history and basics concepts of data mesh. After that, it was interesting to see how different sessions presented a different take on the concept. Here are my three highlights.
Rewire for Data Mesh: atomic steps to rewire the backbone of your organization
In this talk, Zhamak Dehghani described how the management of data in organisations is becoming ever more complex. With more data sources, the uncertainty of the origins and quality of the data grows. Companies are investing a lot of their resources in data and AI, and yet this doesn't seem to impact adoption much.
Dehghani argues that the reason for this is it doesn't matter how much money goes into the management of an organisation's data if the complexity of the data is not addressed. She made the analogy of today's data architectures often resembling a tower of Babel - for data to progress through the pipelines, so many connectors are needed and so much friction needs to be overcome.

Data Mesh was then presented as a solution that embraces the natural complexity of data in an organisation. It does so by following four core principles:
- Domain ownership
- Data as a product
- Self-service data infrastructure
- Federated computational governance
The atomic steps to rewire and get to the target state of a decentralised data share, which the title of the session alludes to, are the following:
- Have data mesh aligned incentives. The idea should be to move away from incentivising having as much data as you can, but instead to incentivise the usage of that data
- Inverse Conway's Manoeuvre. Conway's law is the idea that systems mimic the communication structure of the organisation. Dehghani proposes to implement the inverse of that law – design teams in a way that will drive the architecture that we want to have. In other words, move the responsibility into domain teams.
- Embedded data science. People need an intrinsic motivation for sharing data, and this comes from need. So a solution to this is to embed data science and data sharing into domains.
Dehghani finally shares what she thinks our North Star should be: cross functional and business aligned teams. Technology needs to take a secondary role when implementing a Data Mesh approach, as change will be driven by the culture in the organisation.
Rethinking Master Data Management with Data Mesh
In his talk, Danilo Sato explains how Data Mesh and Master Data Management - two concepts that appear to contradict each other – can be brought together.
Master data is defined as the data that provides the context for business activity. It has four typical implementation styles:
- Consolidation
- Registry
- Coexistence
- Centralisation
Sato explains that most organisations opt for implementing consolidation and centralisation, but these are the two concepts that are the farthest away from data mesh.
With a data mesh oriented mindset, organisations would opt for a mixed approach with coexistence and registry, with a federated governance to support it.
Some of the common mistakes this derives from are trying to fix data quality downstream, trying to force canonical models that represent a unique truth, or trying to solve data management issues by buying a solution - the change needed goes beyond technology.
So, how can we rethink MDM with Data Mesh?
In a traditional Master Data Management approach, the goal is to build a main entity. But creating a single view of a product often proves difficult. Often, the product is too complex to fit in a unique model, and doing so would force a single representation of the product to be accepted, which would be simplistic and inaccurate. This could also lead to data quality issues as different business units might not understand or conform to the unique model used.
The data mesh approach for implementing Master Data Mesh, however, embraces decentralisation.
Danilo Sato calls for the following mindset shift:
- Instead of chasing a single source of truth, have slices of truth owned by the appropriate domains
- Instead of reverting to a canonical model, protect the contextual integrity of models and embrace complexity
- Instead of driving the solution by technology teams, makes sure all parts of the business have aligned goals
- Use data as an integral part of the design and modelling, not just as an afterthought of modelling
- Make sure there is a clear ownership of data, enabling product thinking and team autonomy
Why you don't need a Data Mesh: how to democratise your data with modern Master Data Management
In this talk, Tim Ward provides a more nuanced opinion on the subject. While agreeing with some of the ideas behind data mesh, this talk argues against the concept as a whole.
While advocating for the concepts of domain ownership and data as a product, this talk argues that implementing a federated governance of data won't solve any of the most common organisational problems faced nowadays. Ward reminds us that there is already an abundance of decentralisation within organisations, which indicates that's not the root of the problem.
The main business drivers for implementing data mesh are a lack of data ownership and a lack of data quality, which are basically the same problems Master Data Management is tasked with solving.
So, why are traditional Master Data Management projects failing? Master Data Management was supposed to be about bringing the business to a technology layer, and hence provide a tool for the business, not for IT departments. Instead, traditional MDM can include complex modelling forcing a dependency on the IT department, struggles with the limitation of the data sources, and a long time to hit the market.
Therefore, the conclusion of the session was that master data management is inevitable, as even when there is decentralisation, systems need to be orchestrated in some way. It is clear, however, that there are some fundamental problems with how MDM has traditionally been approached. Bringing in some of the concepts from data mesh, such as decentralisation and thinking of data as a product can help modernise MDM and make its implementation successful.
Data quality and availability
Data creation: how organisations are deliberately creating data to power ML and data applications
In this talk, Yali Sassoon discusses the limitations of working with extracted data and why we should be focusing more on creating the data we need.
Sassoon argues that given the importance of the use of data for modern organisations, the way we think of data is not changing fast enough. Data is often seen as a tangible asset, hence the sometimes used expression “data is oil”. But Sassoon will challenge this. This made me think of Barry Smart's blog post “Data is the new soil”, where he explains that data should be seen as something that needs to be taken care of by data stewards, and that, if well taken care of, will bear it's fruit.

According to Sassoon, when we think of data as oil, we make some dangerous assumptions:
- Each organisation has a limited number of data sources
- When looking to extract value from data, the first step that should be taken is extracting the data
- No data can be used from outside the identified sources
Yali Sassoon then proceeds to challenge that. Some of the limitations that come with working with extracted data are:
- Small data scope. By defining a finite set of data sources, data becomes a limiting factor instead of an enabler.
- Bad data quality. Just like oil, when first collected, data is messy and unusable. However, unlike oil, there is no easy recipe for refining it.
- Interpreting data. Often, a lot of tribal knowledge is needed to understand data, such as the source, and its context.
- Transforming the data. Once the data is extracted from an application or a database, the structure of the data will need to be optimised for the purpose it will be used, which is often not its intended purpose.
- Managing the evolution of data
In order to build robust data products, Yali Sassoon proposes creating data instead of extracting it.
Modern data stack
New terminology made clear
In his talk, James Lupton presented four term currently used in the data sector from the customer's perspective, as he recognises there's often a gap between what things mean and how they are implemented. I found this useful after hearing so many buzz words during the conference.
Data Observability
Data observability is about looking at the health of data, and looking at ways of stopping data downtime.
Typically, vendors describe data observability as the freshness, distribution, volume, schema, and lineage of the data. But data observability nowadays wants to look at the bigger picture, including the connections and relationships between the system databases and data pipelines. This talk argues that data observability should be able to capture what has been broken, not only that something is broken.
Active metadata
Active metadata is presented as the next generation of data catalogs. Instead of being passive, where a person needs to access a system to find metadata, active metadata is intelligent, action oriented (it drives alerts when needed), and API enabled.
Reverse ETL
Just like its name indicates, reverse ETL is ETL done in the opposite direction. Instead data entering operational systems, it leaves them.
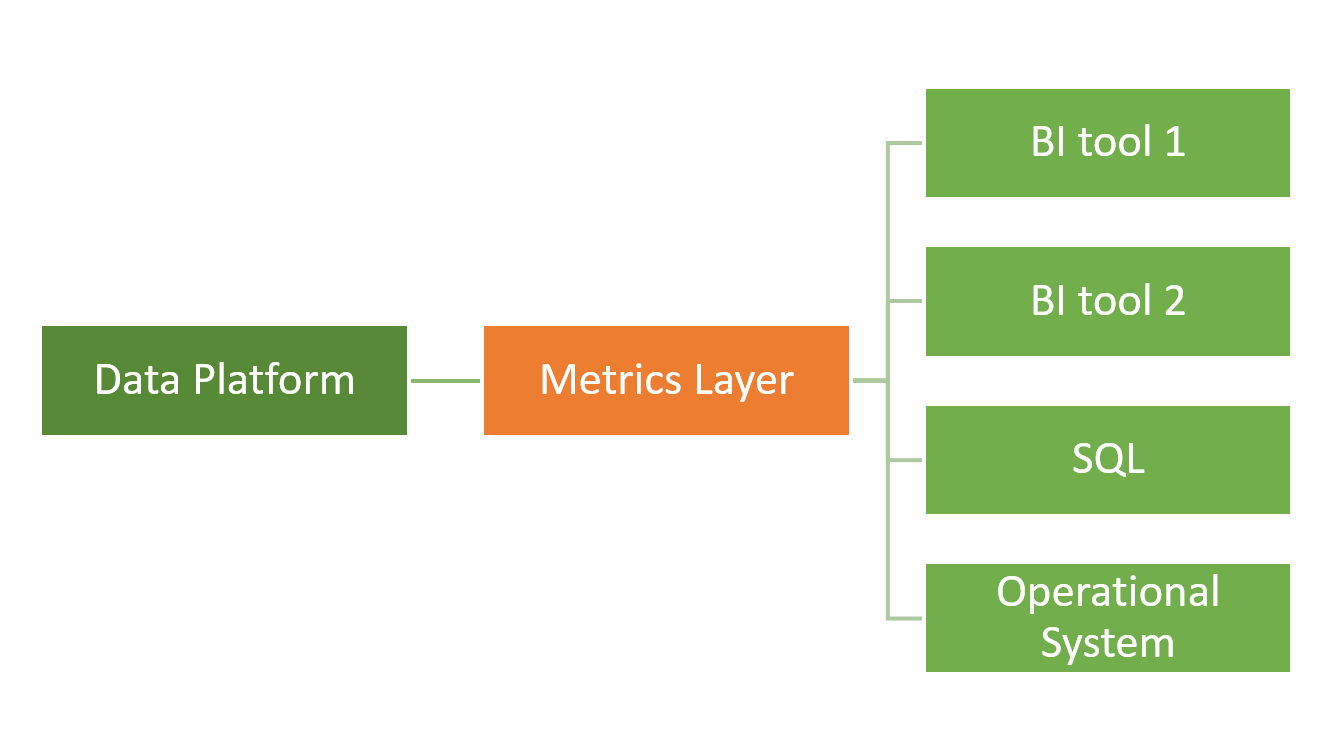
Metrics Layer
A metrics layer is an added layer in the data pipeline whose purpose is to centrally define all metrics used in reporting and how each metric should be aggregated.
Women in data
I attended two talks around the topic of women in data:
Fairy tale lessons and how they apply to your career, by Robin Sutara
You've got to pivot your career, just like your products: how I got into data, by Chanade Hemming
I found it very refreshing to hear how both talks coincided in saying that a successful career doesn't need to be a linear one.
Some of the lessons I took away from their stories are:
- Trial and error is needed to find your passion. If you're curious about something but don't know much about it, try it out!
- Invest in building a strong foundation. Building a strong network will help you develop your skills and open opportunities for you in the future.
- Know your strengths. Recognising what's a good fit for you (in terms of roles, company culture, ways of working, etc) will set you up for success.
- Appearances aren't always what they seem. Everyone has a personal life outside of work, and sometimes one gets in the way of the other. Career progression might not be your biggest priority at some points in your life for many reasons, and that's okay.
My first in person data conference!
This was a new experience for me, as it was my first time attending a data conference in person. Here are some key things I observed and that might be useful for others going to a conference for the first time:
- Make a plan beforehand
The schedule is tight, and you won't have much time between sessions to decide where to go next. Also, arriving late or just before the session is about to start will most likely mean you won't get in, as sessions are often over-subscribed. Make sure you look at all the sessions available in advance and make a note of the ones you want to attend. This will make it less stressful, and you'll get to hear the ones you're actually interested in.
- Be prepared to introduce yourself
Most people you meet there will ask you what you do, and “I work in tech” or “I work in data” will not do it, because that'll be everyone there! So be ready to explain in a concise yet detailed enough way what your role is, what your company does, and your responsibilities (and maybe what you're trying to get out of the conference).
- Talk to people
I must admit I struggled with this one, but you shouldn't be scared of talking to people. Apart from a conference, these events are also great networking opportunities. Exhibitors will be delighted to talk to you about their product, and even if it's not related to what you do, you might discover some cool bit of technology you didn't know existed!
- Bring snacks
Once you start walking from room to room and try to get to all the sessions you want to go to on time, you will barely have time for a break. Pack a snack to have on the go!



