Insight Discovery (part 4) – Data projects should have a backlog


TLDR; The traditional, bottom-up, data modelling approach to data warehousing leads to compromised data platforms that are hard to evolve, expensive to run, and don't meet the needs of the business. Endjin's Insight Discovery process helps you to ask the right questions of the business, so that you can design a data platform that fully meets their needs.
Insight Discovery
This series of posts, and the process that they describe, will help you ensure that your data projects are successful. That the time, money and energy that you or your organisations are investing in strategic data initiatives are well spent and that they deliver real business value.
They describe a different way of thinking, a shift in mindset, in how to approach data projects, that puts the consumer and the outputs front and centre of the process.
In the previous post in the series I talked about how to capture and define actionable insights, which form the requirements backlog for the delivery of our data projects.

In this post I'll look at how to priotise that backlog, so that you can guarantee that what you do first will add value straight away.
Insights should be prioritised
As with any backlog, before we start anything, we should think about prioritisation. Because not all insights are equal. It might be that we don't have the data to provide the evidence that we've identified. It might be that we have the data, but it's not at the right granularity level, or we can't get hold of it fast enough to support the notification schedule that we need.
If we go back to the questions we identified for the call centre manager in the previous post:
- How busy are we now?
- How busy are we likely to be tomorrow?
- What would the optimal team size be?
What's interesting here is that each of these questions are different, yet all of them would be useful.
And, if we dig a little deeper, we can see that each question builds on the next to add a higher level insight:
- The first question is asking about current state. It's descriptive - what's already happened?
- The second question is asking about the future state. It's predictive - what do we thing is going to happen?
- And the third question is asking for an answer. It's prescriptive - what should we do about it?

So, you can also get the same insights in different ways, and in different levels of sophistication.
Which is why you need to prioritise. And there's two axes that are useful here:
- The business impact
- The complexity to deliver
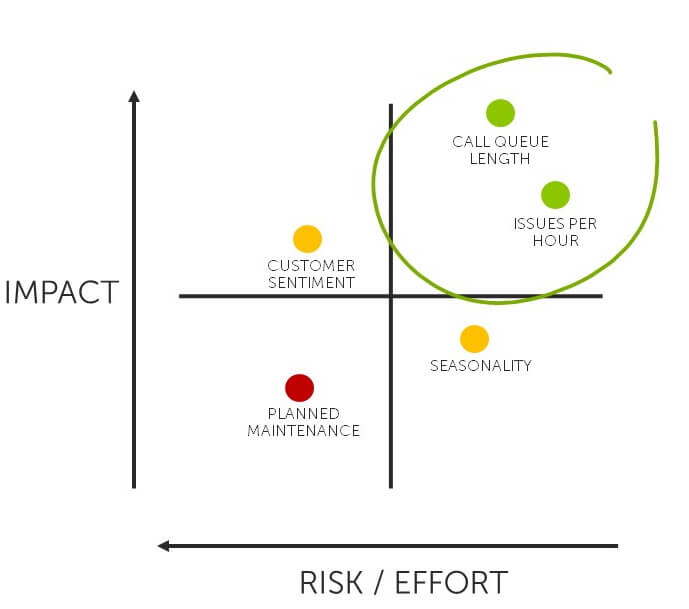
Being able to answer the question "What would the optimal team size be?" would clearly have a huge business impact. But in order to do that, you may need to create insights that don't currently exist - we may need to capture a lot more data, there may be sophisticated modelling needed, there may be an element of experimentation to see if this is even feasible - that we can predict that with good enough confidence for it to be useful. So it's probably going to be very complicated. And you might want to through all your resources at this - it may be significant enough to justify the time & money to figure it out. But you need to make that prioritisation decision in context with everything else.
By asking the business what they need, you haven't constrained yourself by what's currently possible. Because what's currently possible might not be what they need at all. But now you can prioritise accordingly.
Obviously the best starting point is in the top right of the matrix - high impact, low effort insights. That's where you want to start your delivery, as you're now guaranteeing that what you do first will add value straight away. Which leads to adoption, and further investment. And then you just keep going through this process - discover the insights needed, prioritise, deliver.
If you've had any experience of software delivery projects then this is probably all starting to sound very familiar - defining top down requirements, prioritising and delivering incremental pieces of value. This delivery model is well established and proven in software delivery in agile, iterative development processes. And all I'm talking about is applying the same techniques to data project delivery. But you can only do this by focussing on outputs and needs, rather than the low level data.



