Computer Networking Essentials for Developers: the Web - Part 2


We're using computer networks and the Internet all the time. Here at endjin, much of our work is done in Azure – a cloud platform that we communicate with over the internet and have some degree of control over the internal networking that our cloud-based applications depend on.
The vast majority of the workings of networks are abstracted away from us, however considering we use them so much and are so dependent on them, especially as software engineers, it seems reasonable that we should have at least some understanding of how it all works.
The aim of this series of posts is to give an introduction to computer networks, the Internet and the Web, at a scope that is relevant to the software developer. Based on my brief foray into networking, it's obvious that it is a massive and complex subject, with many layers of details – many of which I will not cover (and do not understand) in order to keep things relevant.
In my previous post in this networking series I introduced the Web – an application that utilises the facilities provided by the Internet (discussed in the first post) to send its own content types between Internet hosts, the most important of which is the web page (i.e. HTML documents), but there are others.

I mentioned at the end of that post that if you could magic-up all of the technology discussed in the first two articles, that the resulting websites would not have many of the features of the websites you're probably used to – interactiveness, fancy colours and fonts, images, videos, etc. In this post I'm going to discuss the other components of the Web that are needed for all that stuff, namely: different content types, Cascading Style Sheets (CSS), and JavaScript (JS).
Web Content
So, besides HTML documents, what other things can the be sent over the Web? We know from our own experience that browsers can display images and videos. In fact, to a web server and browser the things they send and receive in HTTP message bodies are just bunches of bits. The way they differentiate between the different content types – say an image and an HTML file – is by looking at the content's MIME (Multipurpose Internet Mail Extension) type, which specifies the type of data that the bits represent.
An MIME type consists of two parts: a type and a subtype, and has the following format: type/subtype. The type represents the general data category of the content in question, e.g. text or image. The subtype specifies the specific flavour of the more general data type represented by type, such as html or png, with the corresponding full MIME types being text/html and image/png, respectively. Other examples of MIME types include, audio/MP4, video/MP4, application/octet-stream (meaning the type is unknown), and text/plain. You can find a full list of all official MIME types here.
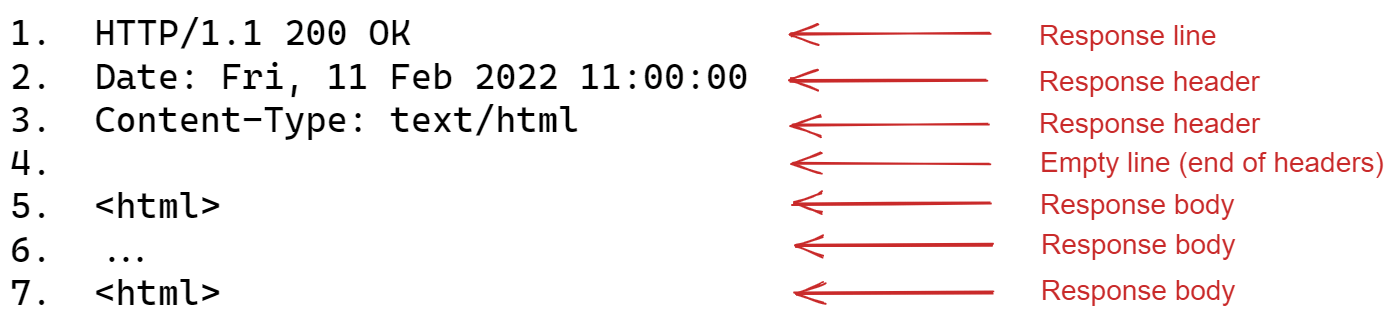
It's obviously important for the browser to know the type of data it is receiving in order to know what to do with it. The image below shows the HTTP response example shown in the previous post in this series; you can see that the MIME type of text/html is contained in the content-type response header – this is what the browser will use to decide how to display the data.
Static Vs Dynamic Content
Up to now I have only covered the case where a browser requests a specific file (or any piece of web content) from a server. For example, in the example HTTP request from the previous post - shown below, the client is requesting the file index.html from the internet host www.google.com. As a result the server will either respond with the requested resource, or will give some reason – via the response's status code and message – explaining why it hasn't returned the requested resource.

This is known as serving static content – the web server simply fetches the file from disk and sends a copy to the client. In the case of static content, every client that requests a given piece of static content will receive the same data, and will therefore render the same thing. Examples include blog sites.
Dynamic content
Alternatively, instead of just fetching a resource from disk and sending a copy to the client, the server can run some code (i.e. an executable) and return the output of that to the client. In this case, the server is said to be serving dynamic content; the content is dynamic in the sense that the HTML (and other) files are produced on the fly by code executing on the server. This allows for web sites to be customised to clients; every website that requires a personal login is served dynamically – the content being sent to the client is dependent on the login data provided, and different clients will receive different content from the server.
Web development frameworks, written in various programming languages, are used to produce web pages dynamically, examples include Laravel (using PHP), ASP.NET (using C#), and Ruby on Rails (using Ruby). These are referred to as server-side web development frameworks, as the code is running on the server (we'll get to client-side frameworks later).
Program arguments for dynamic content
As I mentioned, to serve content dynamically, the server runs some executable file (i.e. a program); when making a request to a URL representing an executable file, the client can pass arguments to the program – values for the parameters that the program takes (the client has to pass information in, otherwise it makes no sense – the content produced would be the same each time, which is static, not dynamic).
How the client passes those arguments depends on the type of HTTP request. For GET requests, the program arguments are placed after the file path in the URL representing the executable file. The example shown below identifies an executable file called cars living on internet host www.thebestcars.com, and is being called with two arguments: bmw and true for the program parameters type and price_ascending respectively. The ? character after the file path in the URL separates the file path from the arguments; different arguments are separated by an & character. The section of the URL after the ? symbol is referred to as the query string.

For POST and PUT requests, parameter arguments to be sent to an executable file are contained in the HTTP request body.
CSS
Up to now we have seen how all sorts of data types, in addition to HTML files, can be sent over the Web, and how servers can serve content dynamically to clients – both making the web richer. In these next sections we're going explore how the Web is made prettier and more interactive.
CSS (Cascading Style Sheets) is a style sheet language used to style a markup document. In other words, it's a language made for adding style to HTML documents; think colours, fonts, symbols, and more.
CSS is a language in the same sense that HTML is: it's essentially plain text that is interpreted by the browser, instructing it to display certain things in certain ways.
Styling HTML with CSS
In-line with HTML
You can simply write CSS instructions inline to the HTML elements representing your web page by using the style attribute inside the elements. In the example HTML file below I've added a style attribute to the <div> element containing an unordered list element (<ul>) with the CSS instruction colour:blue, which is going to make all text inside that <div> element blue, meaning the text in the list. In addition, in the second list item element (<li>) I have added another style attribute with the CSS instruction: font-style:italic, which is going to make the text for that list item italic.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>My HTML Page!</title>
</head>
<body>
<div>
<h3>A list of of topics in this blog post:</h3>
</div>
<div style="color:blue">
<ul>
<li>Web content types</li>
<li style="font-style:italic">CSS</li>
<li>JavaScript</li>
</ul>
</div>
</body>
</html>
This basic example demonstrates how easy it is to style HTML with CSS.
Internal to the HTML document
Alternatively, the CSS for styling an HTML document can be added in the <head> section of the document within a <style> element, and be referred to from other elements in the <body> of the document.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>My HTML Page!</title>
<style>
li {
color:blue
}
.italic {
font-style: italic
}
</style>
</head>
<body>
<div>
<h3>A list of topics in this blog post:</h3>
</div>
<div style="color:blue">
<ul>
<li>Web content types</li>
<li class="italic">CSS</li>
<li>JavaScript</li>
</ul>
</div>
</body>
</html>
The example above produces the same webpage as the previous example using this different method of embedding the CSS in the document. The CSS instructions here say that every <div> element should display blue text, it also declares a CSS class that makes text italic, which can be used inside other HTML elements where you want to apply it - you can see this in the second <li> element, again making the text there italic.
External to the HTML document
The previous method for styling the same webpage in exactly the same way as the first method was definitely neater. Another option for styling your HTML document with CSS is to write the CSS in a separate file (an external style sheet) and refer to it from the HTML document. To use an external CSS file, add a link to it using <link> tags inside the <head> section of your document.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>My HTML Page!</title>
<link rel="stylesheet" type="text/css" href="StyleSheet.css">
</head>
<body>
<div>
<h3>A list of of topics in this blog post:</h3>
</div>
<div>
<ul>
<li>Web content types</li>
<li class="italic">CSS</li>
<li>JavaScript</li>
</ul>
</div>
</body>
</html>
The same example HTML document shown above demonstrates this. I have pulled out the contents of the <style> element from the previous example and saved it in a separate file called StyleSheet.css. The new <link> element in the <head> section of the above document is referring to that style sheet, meaning we can use the CSS defined in it, just like before – which I have in exactly the same way as previously, because it's essentially the same style sheet except now it's stored in a separate file, whereas before it was in the same file as the HTML itself.
This is the neatest and most common way to style HTML documents; having tonnes of CSS in the same file as your HTML would make a complete mess, and this way it's easier to maintain and make changes.

One question that arises here: how does the client get the CSS files that it needs from the server? The answer: the browser will detect the <link> element inside the markup document and will automatically send a GET request to the URL specified in the href attribute there. In this case, a CSS file is simply another piece of web content to be requested by browsers and served by servers over HTTP.
JavaScript
CSS is for styling web pages, JavaScript is for bringing them to life. It's a programming language that can be executed by a browser – every browser has their own JavaScript engine for interpreting and executing the code - meaning the code is executed on the client's machine (client-side).
JavaScript is used to manipulate HTML, meaning it can alter the web page. If you think about what the means in terms of website performance: the webpage can be changed by code running on the client's machine, i.e. without sending a HTTP request to the server and waiting for its response. This is how JavaScript makes pages interactive and more dynamic (in a different sense to the type of dynamism mentioned earlier).
Consider a basic example with and without JavaScript to demonstrate this: say your website has a form for the user to submit information to the server, and the form has some input validation – the name can't contain numbers, must be greater than zero characters, etc. Without JavaScript: the user fills out the form and hits submit; the data is sent to the server through a POST request and code running on the server performs the validation. If the validation fails, the server responds to the client informing the user of the reasons for failure; the form is then filled in correctly and re-sent. This requires at least two HTTP transactions and the user has to wait for the page to reload to know if he or she has filled in the form correctly. Now with JavaScript: the input validation is simply performed on the client side and the user can only send the form once all validation has passed – a single HTTP transaction and no lengthy waiting to see the result of input validation.
Just like I showed with CSS, JavaScript code can be inserted in-line with HTML elements, embedded in the header section, or stored in a separate file to the HTML, I'm going to show an example of each of these using the same JavaScript code.
In-line with HTML
As an example we're going have a simple web page that displays a button that, when clicked, displays the current date using some JavaScript code. In other words, when the client interacts with the web page in a certain way, some code is executed on the client-side that modifies the HTML of the page being displayed.
<!DOCTYPE html>
<html>
<head>
<title>My HTML Page!</title>
</head>
<body>
<button type="button"
onclick="document.getElementById('date').innerHTML = Date()">
See the date
</button>
<p id="date"></p>
</body>
</html>
The web page defined by the above HTML has a button that displays “see date”; the button element has an onclick attribute, which is an event attribute that triggers some action when the event is detected; the event in this case is the user clicking the button, and the action is to execute the JavaScript code specified in the double quotes.
If you look at the JavaScript code, it is accessing the HTML element with the id of date, which is the <p> element further down, and is assigning the content of that element with the result of Date(), which is a built-in JavaScript function that returns the current date. So this will display the current date on the page when the button is clicked, as described.
Internal to the HTML document
Alternatively, the same JavaScript code can be wrapped inside a function and placed in a <script> element inside the <head> section; the function can then be called from the button element – producing the same results as the previous example. The code below demonstrates.
<!DOCTYPE html>
<html>
<head>
<title>My HTML Page!</title>
<script>
function ShowDate() {
document.getElementById('demo').innerHTML = Date();
}
</script>
</head>
<body>
<button type="button"
onclick="ShowDate();">
See the date
</button>
<p id="date"></p>
</body>
</html>
External to the HTML document
As with CSS code, having JavaScript code mixed in with HTML is extremely messy, and makes maintaining and changing code more difficult. The cleanest way to have JavaScript code interact with the markup, as with CSS, is to have it in separate files that are linked to from the HTML file – this time using <script> elements. This way JavaScript files are just another form of Web content to be requested by web browsers and served by web servers. The browser will detect the <script> elements and automatically request the content identified by the URL specified in the src attribute of the <script> tag, just like with CSS files. The example below demonstrates this.
<!DOCTYPE html>
<html>
<head>
<title>My HTML Page!</title>
<script type="text/javascript" src="ScriptFile.js"></script>
</head>
<body>
<button type="button"
onclick="ShowDate();">
See the date
</button>
<p id="date"></p>
</body>
</html>
The basic example demonstrates how code running on the client side can manipulate HTML and consequently change the page being rendered. You can imagine how this approach can be used with more sophisticated code to produce fancier website features like hover menus, interactive charts, and so on.
(Note: in the example above, the URL being used in the src attribute of the <script> tag is simply a path to a local file, this is fine because I'm running these examples locally. The same is also true in the case of the CSS example earlier. For an actual website out in the wild, the JavaScript file would live on a machine different to that of the client's, therefore the URL would look like a familiar URL - containing a http scheme, etc.)
The DOM
The DOM (Domain Object Model) is the interface through which JavaScript code interacts with and modifies the markup of a web page. It's a representation of the HTML document in a tree structure that makes it easier for developers to interact with the markup programmatically. The main API that the DOM exposes is the document object, which represents the HTML document; this object has methods and properties, like document.getElementById() used in the JavaScript examples above, that can be used to programmatically interact with and modify HTML elements.
Using JavaScript to interact with the browser
As well as interacting with the HTML document representing the web page, JavaScript code can, more generally, interact with the browser to do things like show pop-up windows, request access to the webcam, and send HTTP requests. The browser exposes APIs for code to interact with, like the screen, window and history objects; these objects form the BOM (Browser Object Model), of which the DOM is a part.
One important aspect of the interaction between JavaScript code and the browser, in terms of creating responsive web apps, is the ability for code to send HTTP requests in the background. These are referred to as AJAX (Asynchronous JavaScript And XML) (which is just a generic term used to refer to this method of sending HTTP requests with JavaScript code) calls and they allow the webpage to stay responsive whilst a HTTP transaction with the server is happening in the background, meaning parts of the web page can be modified without refreshing the whole page - resulting in a better user experience.
Consider the following scenario to demonstrate the benefits of using AJAX: let's say there is a web page currently loaded on the client that contains a button that, when clicked, requests additional data from a server to be displayed in the page. One way of updating the page with the new data is by doing a full HTTP request, where the server responds with a new HTML document and the new data, i.e. a page refresh. Alternatively, upon clicking the button, you could have some JavaScript code send a HTTP request to the endpoint asynchronously - meaning the UI is still responsive whilst the request is happening – and when the response containing the data is received, JavaScript code on the client side will process the result and update the HTML appropriately to display the new data. This way the user doesn't have to wait for a page refresh to see the updated page.
JavaScript frameworks
Just like there are server-side web development frameworks, some of which I mentioned towards the beginning of the article, there are also client-side JavaScript frameworks. Frameworks in general are libraries of code, written in the language that they pertain to, that developers can use to be more productive. Popular client side JavaScript frameworks, i.e. for producing JavaScript code to run in a browser on the client side, include Angular.js, React.js and Vue.js.
Server-side JavaScript
Up to now we have discussed JavaScript exclusively in the context of it running in a browser on the client-side to modify HTML, and so on. However, JavaScript is a general purpose programming language and so it's possible for it to be used – just like you can use C#, Python, Ruby, etc – on the server-side in Web development. Browsers contain JavaScript engines that execute JavaScript code in the browser, likewise servers can contain JavaScript engines for executing JavaScript code on a server. Node.js is an example of a server-side JavaScript framework.