Benchmarking Azure Synapse SQL Serverless with Polyglot Notebooks


There is a new service in town that promises to transform the way you query the contents of your data lake. Azure Synapse Analytics comes with a new offering called SQL Serverless allowing you to query your data on-demand with no need for pre-provisioned resources.
When we heard about the new service we were keen to get involved, so for the last 10 months we've been working with the SQL Serverless product group to provide feedback on the service and to help ensure it meets our customers needs. During this time we've put it through it's paces by implementing a range of real-world use cases. We were particularly interested to see how it stacked up as a replacement for Data Lake Analytics, where to date there has been no clear and easy migration path.
Background
In 2016 we developed a solution on Azure to generate insights into the health of a telco's network and the impact of network issues on customer experience. We did this by continuously ingesting and analysing telemetry produced from the devices that make up their network.
The solution was developed using Azure Data Lake Analytics which is no longer being actively developed by Microsoft so an alternative needs to be found.

Azure Synapse SQL Serverless is a new offering. Like Azure Data Lake Analytics, SQL Serverless is SQL-based and provides query and data processing on a consumption basis. We were interested to know how it could help with operational workloads and chose this specific project as it represents a typical IoT problem that we see all the time - lots of data coming in, continuously monitoring and generating insights.
In order to be considered a replacement we wanted to understand the performance characteristics of the service with regard to various factors such as representative data volumes, file sizes and formats. Parquet, CSV and an alternative CSV parser known as CSV 2.0 are supported. Since our raw input is in an unsupported binary format, we need to decide the best format for our processing needs.
Method
A pre-existing Azure Data Lake Analytics query was ported over to SQL Serverless. This was a relatively straightforward process. The only complexity was in some data type conversation logic. With a bit of work we were able to convert these over to TSQL equivalents.
To replicate the real-world scenario the query was decomposed into a set of views. Views in SQL Serverless are just like standard SQL Server views. They allow you to encapsulate complexity and promote reuse. We created a view that read raw data from the data lake to hide details such as the physical files containing the data. Subsequent views were overlaid to progressively perform the required transformations and aggregation logic.
We then replicated these views for each of the supported parsers:
- Parquet
- CSV
- CSV 2.0
The dataset contained ~50 million rows and was pre-parsed into both Parquet and CSV formats. To test the effect of file sizes we replicated the data as a single file (~ 2GB) and separate hourly partitions resulting in files ~46 MB each.
The query was executed 10 times against each combination of parser and file source, once in series and once with all 10 queries running concurrently.
This equated to a total of 12 individual test runs.
| Parser | Source | Execution |
|---|---|---|
| Parquet | Single File | Series |
| Parquet | Single File | Parallel |
| Parquet | Multiple Files | Series |
| Parquet | Multiple Files | Parallel |
| CSV | Single File | Series |
| CSV | Single File | Parallel |
| CSV | Multiple Files | Series |
| CSV | Multiple Files | Parallel |
| CSV 2.0 | Single File | Series |
| CSV 2.0 | Single File | Parallel |
| CSV 2.0 | Multiple Files | Series |
| CSV 2.0 | Multiple Files | Parallel |
One of the great things about SQL Serverless is that from the client's perspective it looks just like any another SQL Server Database. This means that you can use any tools or languages that can talk to SQL Server. I chose to use .NET as it is my language of choice.
To allow me to document findings I conducted the experiment using Jupyter notebooks powered by Polyglot Notebooks (formerly known as .NET Interactive). If you have not used Polyglot Notebooks I highly recommend it.
To allow me to document findings I conducted the experiment using Jupyter notebooks powered by Polyglot. If you have not used Polyglot Notebooks I highly recommend it.
If you are interested, here's a peek at the notebook.
Notice that you can intersperse executable .NET code, visualisations and commentary - very cool.
Results
Here are some of our findings.
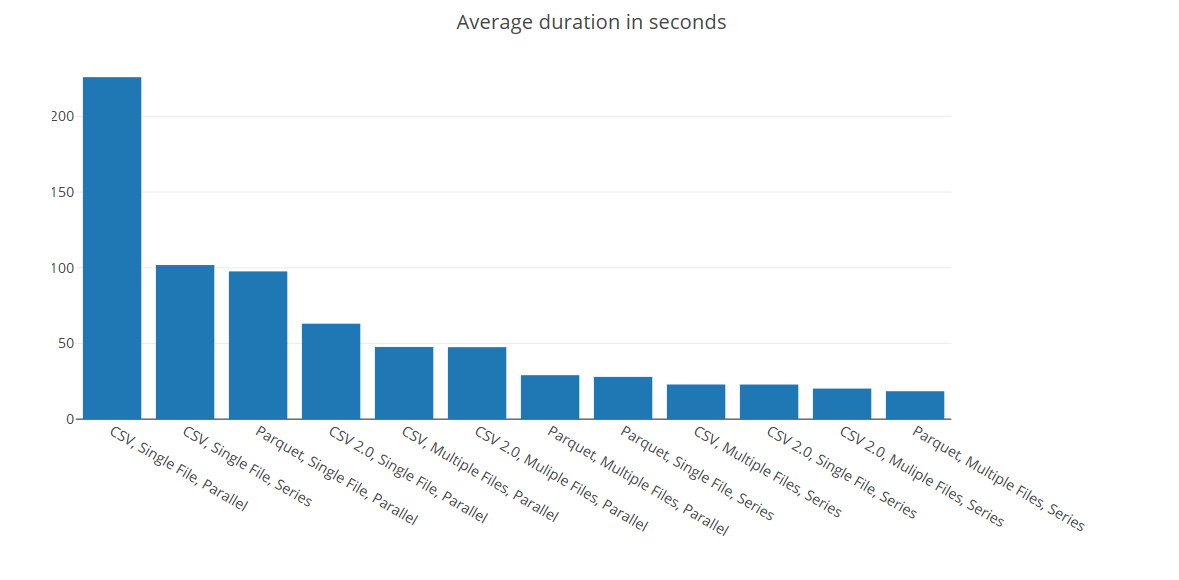
This chart shows the average time it took to execute the query.
Observations:
- We can see that there is significant difference in query performance from the worst performing to the best performing combination.
- Querying a single CSV file 10 times in parallel resulted in an average query duration of 226 seconds whereas multiple Parquet files queried in series was only 18 seconds.
- In general querying a single file 2GB file is slower than the same 2GB spread across multiple smaller files.
- CSV performed the worse, Parquet and CSV 2.0 shared the top spots in terms of performance.
To help explain what is going on, we need to dig a bit deeper. Firstly, what is going on with those parallel runs?
Here is a breakdown of the worse performing parallel runs:
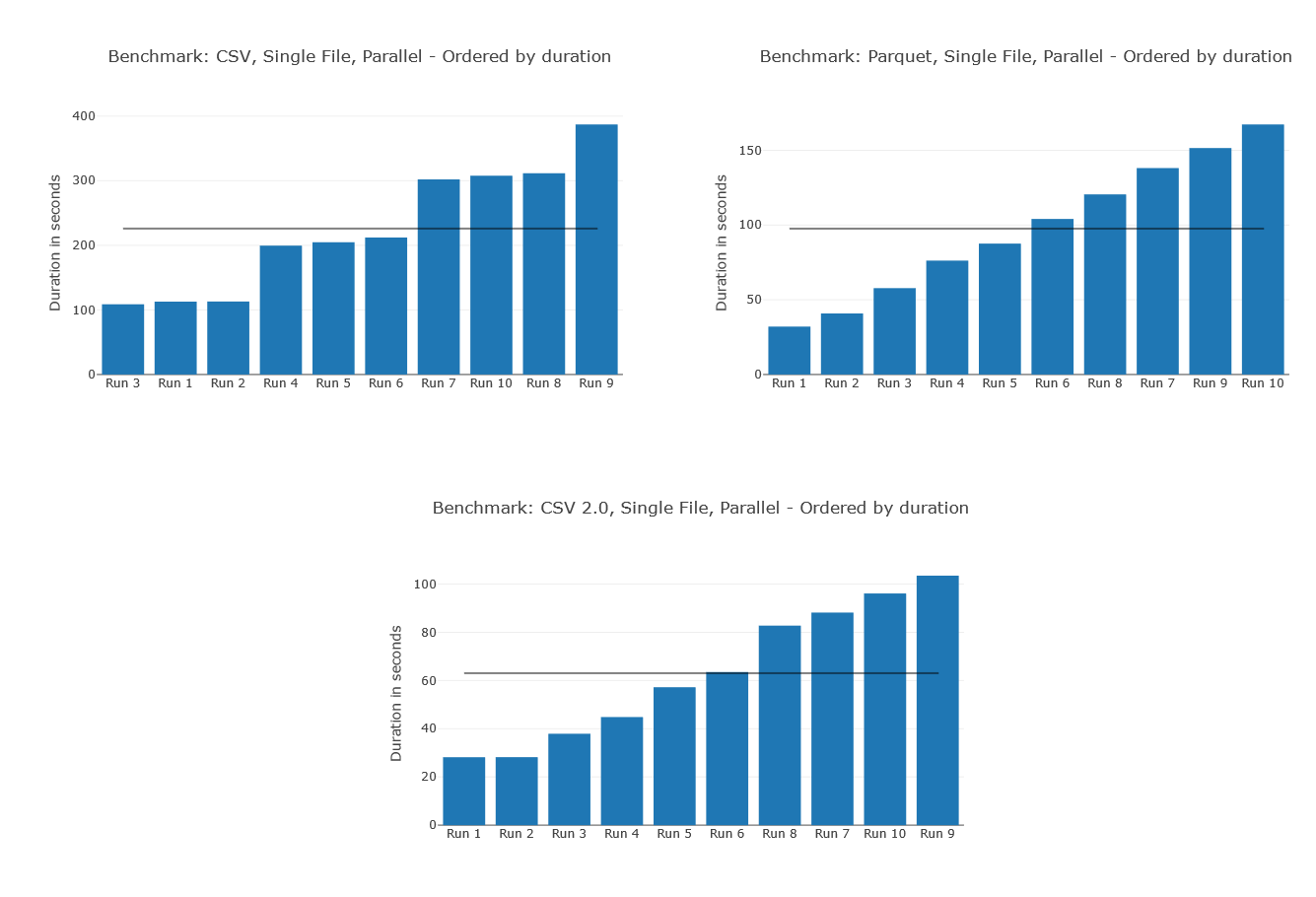
You'll notice that I've ordered these from smallest to highest duration, why didn't I keep with the run order? Remember, these are queries that are run in parallel so we can't guarantee which query SQL Serverless starts processing first. By ordering by duration you can see there is a clear pattern. The more queries that we run, the longer the average query took and this follows a remarkably linear progression. This indicates that there is some form of resource contention going on.
These three examples have one thing in common, they are all querying a single large file. We can see from the first graph that you get much better performance when splitting the same data over smaller files.
When raising this with Microsoft they confirmed that there are currently some inefficiencies when querying the same file at the same time. I suspect that job scheduling is attempting to run jobs close to where data is cached. In non-parallel scenarios this would make sense but for highly parallel scenario this may cause jobs to be queued and would perhaps explain the pattern we are seeing here.

This is not necessarily a bad strategy. In fact we can see it work really well when we look at the performance of over many smaller files. It's also worth pointing out the storage accounts impose their own throughput limits and without caching you may end up simply moving the problem.
In reality, I suspect that most will never see this behaviour. However, I can think of a few scenarios where this might be more apparent, for example, large scale highly responsive data architectures may trigger concurrent pipelines or perhaps when running highly concurrent simulations.
Moving on, let's take a closer look at the best performing scenarios for each of our three parsers.
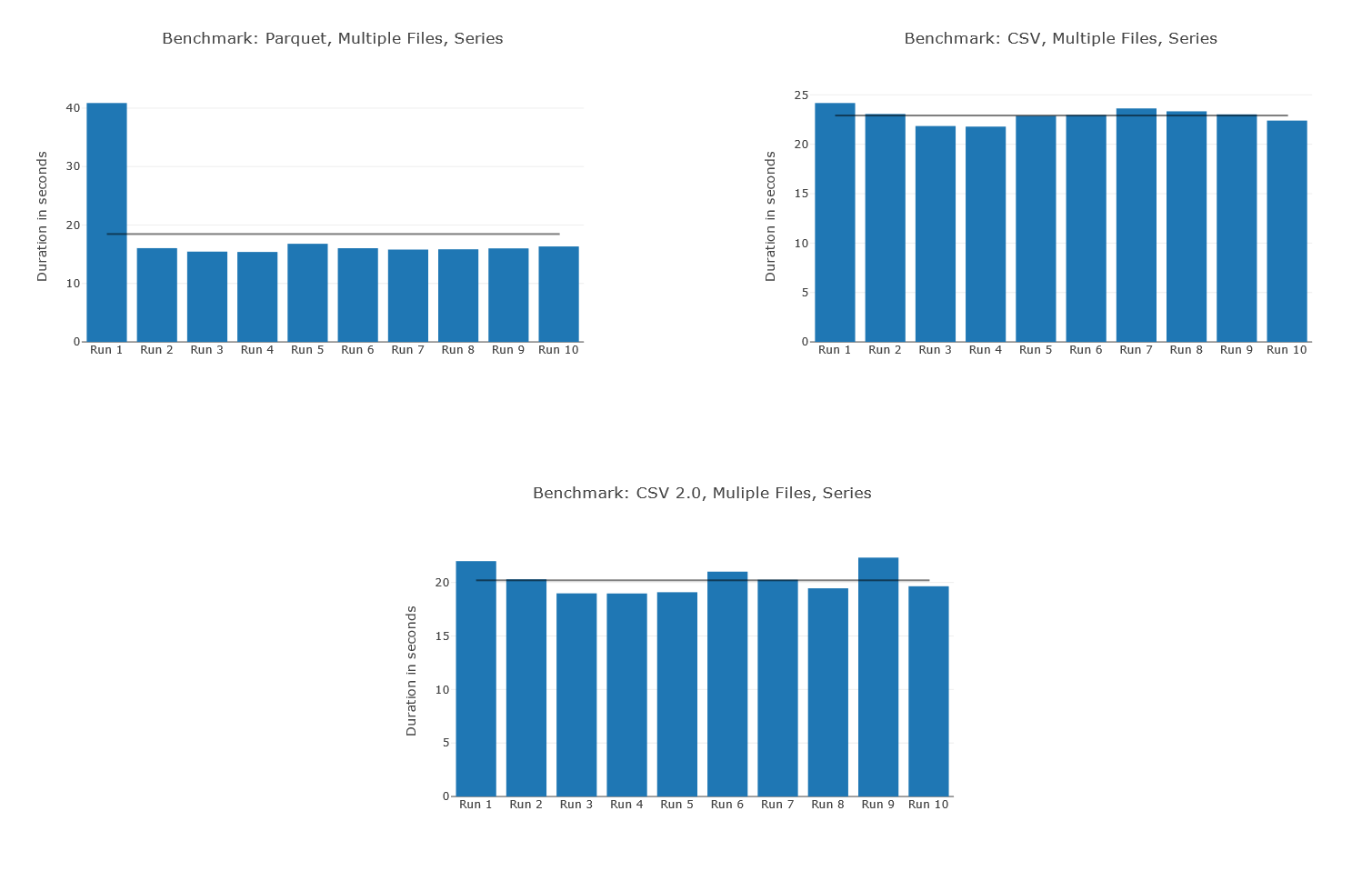
The first thing that stands out is the time it took for the first Parquet query. Parquet differs from CSV in that SQL Serverless will generate statistics and use these to optimise query execution. This process takes a bit of time for the first query but the pay back is that subsequent queries are faster. This could explain why it took so much longer the first time.
If we look at the average times discounting the first run we can see that Parquet is clearly the fastest when querying multiple files.
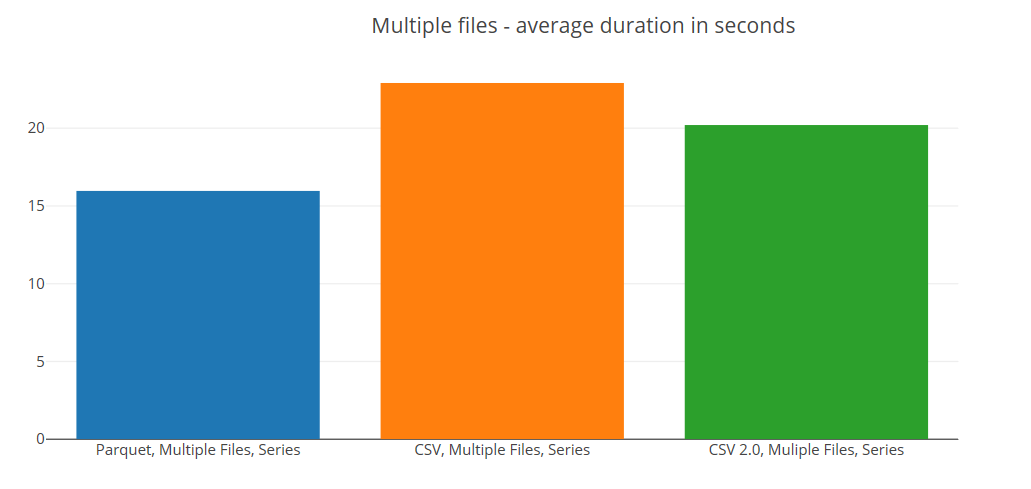
But what if you don't have the luxury of nicely partitioned files. What if you have large files > 1GB? The following plot shows the comparison of each parser over the single file.
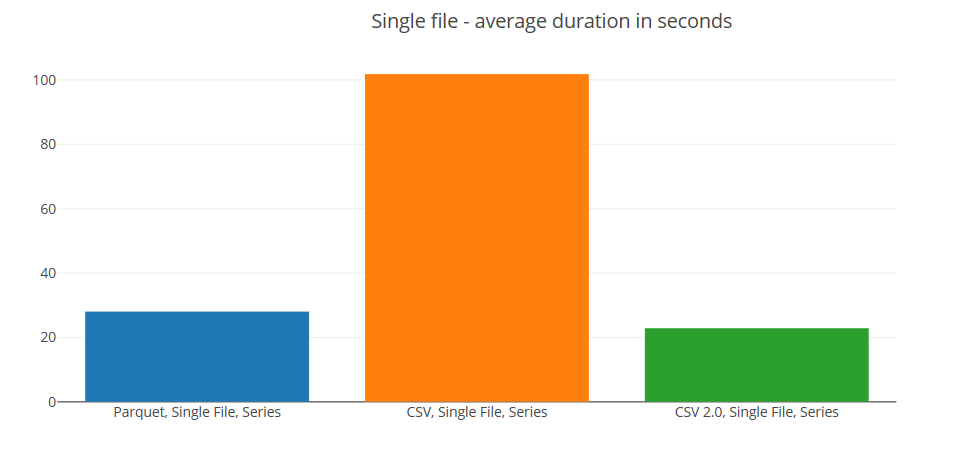
Here we can see that the CSV 2.0 parser wins the standard CSV parser significantly behind.
It's worth pointing out that the query under test reads all columns from the source files. With Parquet it's possible to read a subset of columns but with CSV you have no option but to read all columns for each row. The ability to be selective when reading columns is likely to have a significant impact, especially when querying tables with lots of columns. Querying a subset of columns would mean we could be reading much less data with Parquet, so I would expect this result to be very different in this scenario. However, it's clear that that the performance of the CSV 2.0 parser is very impressive. If you are interested in why it's so good, check out this paper from Microsoft which explains the theory behind it.
CSV is by far the most common format for landing data into data lakes so it's great to see this option available. Be aware that it is not as flexible as the main CSV parser so if you need more control you may not be able to use it.
A word on pricing
SQL Serverless is priced at $5 per terabyte processed. When we scale up the full solution we end up processing 60GB of data per day. That equates to just over $9 or £6.80 per month. While this doesn't include Azure storage costs you have to agree that is pretty compelling. Also, with Parquet you will only be charged for the columns of data you read so there are even more potential savings to be had.
Summary
SQL Serverless performance is very impressive. Whether you are planning on using it for exploring your data lake or integrating within your operational data pipelines.
The first rule for optimising performance is to reduce the amount of data you need to read in the first place. This requires you to partition your data using folders so that you can 'eliminate' the partitions that you know don't contain the data you are interested in.
Parquet was the best for all round performance - if you already have data in Parquet format this is a no brainer. If you have wide tables and you are only querying a subset of columns then Parquet is almost definitely the format to use. In addition, since SQL Serverless can generate statistics for Parquet, you get the benefit of optimisations within the query engine.
Highly concurrent processing over the same files may incur an additional overhead. Optimise file sizes to reduce the impact or reduce the level of job concurrency.
It may be worth considering converting your raw data into Parquet to get the maximum performance from SQL Serverless.
CSV 2.0 is a very fast CSV parser, for some of our tests it came out on top. For CSV processing we recommend you give this a go. However, be aware it doesn't offer the full flexibility of the standard CSV parser, so if you need full control over the CSV layout then you may need to use the standard CSV parser.
You may get different results from us depending on the nature of your data. So always experiment to make sure you optimise for your own needs.
Want to get started with Synapse but not sure where to start?
If you'd like to know more about Azure Synapse, we offer a free 1 hour, 1-2-1 Azure Data Strategy Briefing. Please book a call and then we'll confirm the time and send you a meeting invite.
We also have created number of talks about Azure Synapse:
- Serverless data prep using SQL on demand and Synapse Pipelines
- Azure Synapse - On-Demand Serverless Compute and Querying
- Detecting Anomalies in IoT Telemetry with Azure Synapse Analytics
- Custom C# Spark Jobs in Azure Synapse
- Custom Scala Spark Jobs in Azure Synapse
Finally, if you are interested in more content about Azure Synapse, we have a dedicated editions page which collates all our blog posts.



