Data modelling with Power BI - Loading and shaping data


I have recently written a series of blog post on DAX and Power BI. But in order to effectively work with the data we need to structure the underlying data model as best to support higher level representations we need. Data modelling includes loading, shaping, cleansing and enhancing the data.
Loading data
In Power BI we can load data from multiple sources:
- Databases
- Files
- Web
- Azure
- Online services
- Power BI datasets & dataflows
There are also two options for data loading: import or direct query.
In direct querying a direct connection is established to the data source. In this mode the data stays in the source, and it's queried each time the report is loaded. This does restrict you in a couple of ways:
- You are limited to one database
- You can't add calculated tables on the model

You can however add calculated columns to the model.
Best practices
There are a few best practices for data loading. It is a good idea to reduce the memory used by the model as quickly as possible. To achieve this, you can:
- Reduce the rows
- Reduce the columns
It can also be a good idea to merge tables which have a common column. This can reduce the number of tables and therefore the complexity within the model.

Shaping data
There are many different ways in which we can shape data to support better reporting. Some of these can be done on import and some are done once the data has been loaded. This can include:
- Combining tables with the same schema
- Filtering rows / columns
- Appending queries
- Merging queries
- Renaming columns
- Fixing data types
For example...
We can connect to an excel workbook:
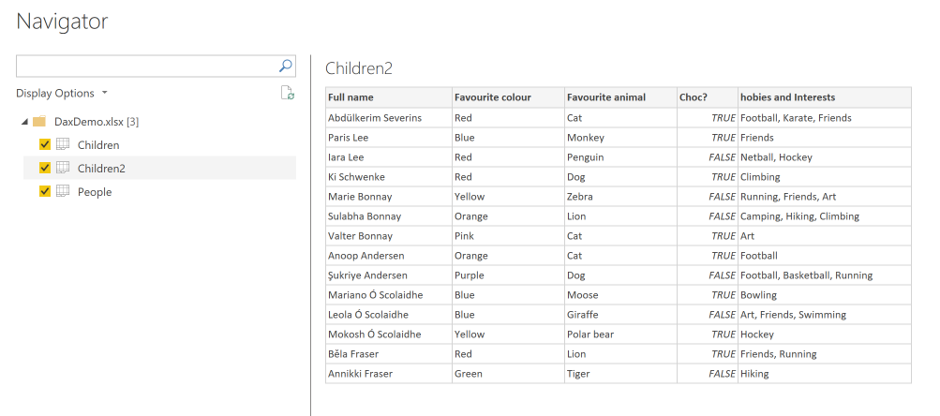
And from this navigator we can transform the data via the query editor. We can see the steps performed on the data in the query editor:
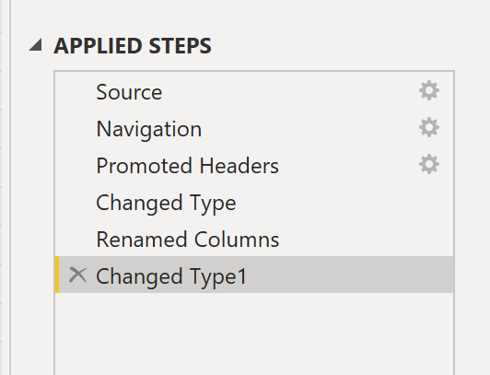
We can even rename the steps to make it clearer what's been done to the data:

Power BI is usually pretty good at guessing the types of the data, but sometimes these types need to be updated. Using this query editor we can remove null data, replace values, etc.


We can see all the individual steps in the query. These include removing blank rows, replacing empty values with nulls, and splitting the name column in to first and last name. After these transformations the data looks like this:

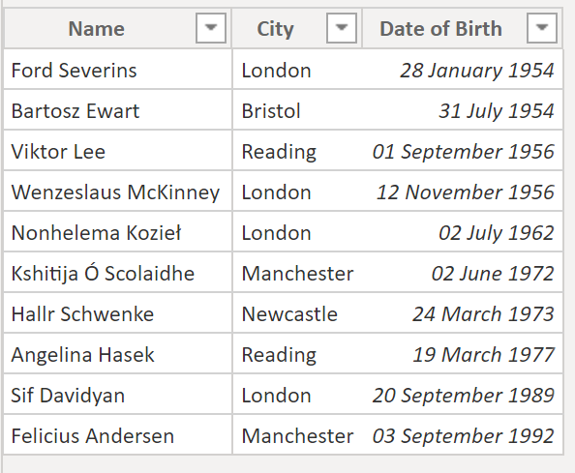
We can also see that there are values in this table which are in a list form. We also need to take a look at the model and see if our table structure makes sense. In our model we have the above table, along with two others. One for the parents:
And one linking the children with their parents:

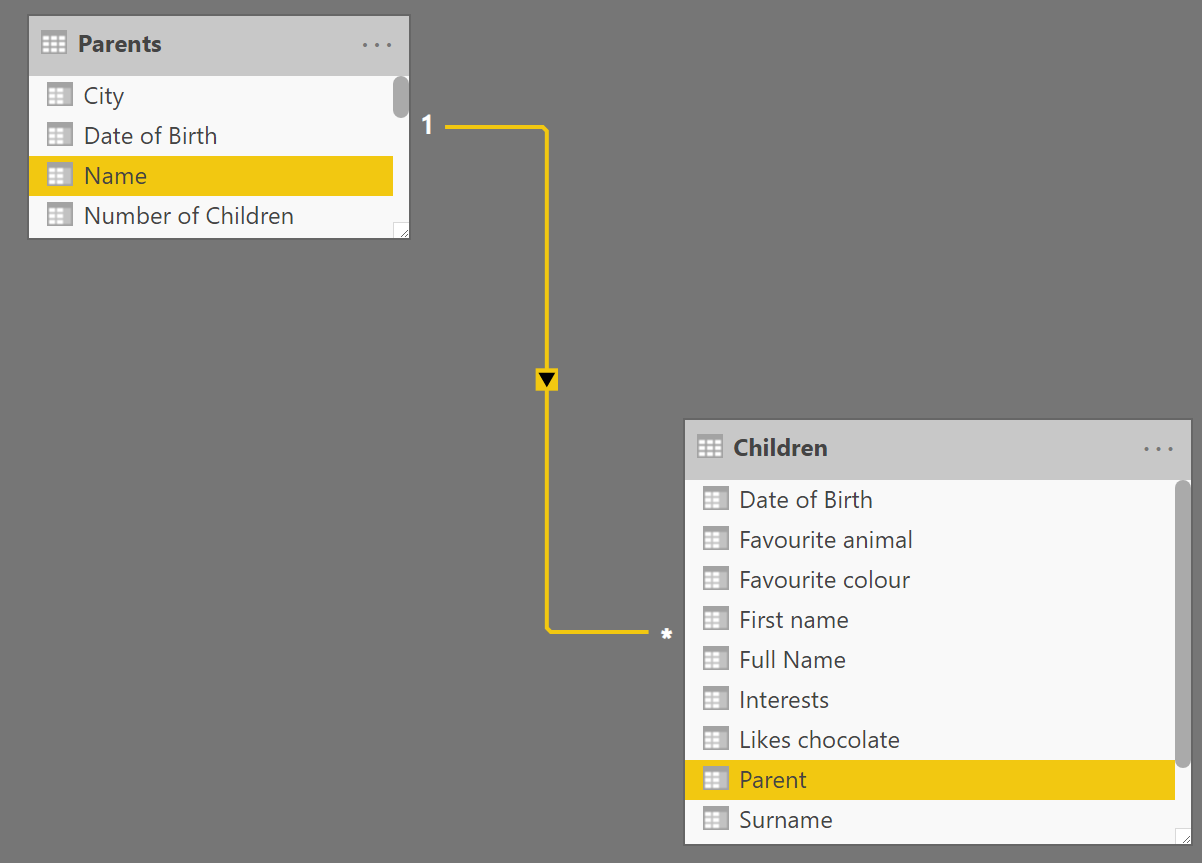
Now looking at this model we have three tables:
- Parents - which contains information about parents, their date of birth and the city they live in.
- Children - which contains the children and connects those children with their parents.
- Children2 - which contains information about the children (their favourite colour, animal, etc.)
It would make sense to merge the two tables which contain data about the children:

And once we've done that we can then see the merge in the applied steps (including the removal of duplicate data and renaming of the expanding Children2 columns).

Now we have two tables: parents and children. These tables can be linked in the data model:
Once we've done this, we can add additional values to the parents table based off of their children:

The final thing we could do is expand the listed values in the "Interests" column. A list like this will be difficult to represent in the visuals because you will end up with a filter for each permutation:

Duplicating the table copies all of the query steps into a second table. If we instead referenced the table, then each change in the first table would propagate into the second. Once we have duplicated it, we can perform the following steps:
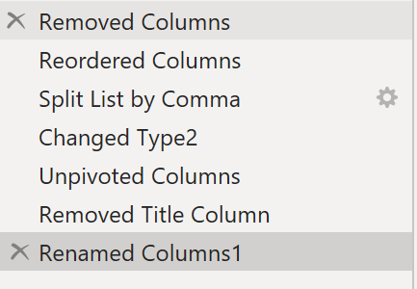
Which leaves us with an "Interests" table like this, which is linked to our children table.

With our data model now complete we can set the Children2 table (which we merged with the Children table) to be hidden in report view and our data model looks like this:

And we can now start building up interesting visuals, combining values from both tables:

We have built up a model which allows us to support fairly complex visualisations but which is also simple enough to be discoverable.