Building a secure data solution using Azure Data Lake Store (Gen2)


This is the blog to accompany my video
Here at endjin we work with a lot of clients who need to secure crucial and high-risk data. Over the years we have developed techniques and best practices which allow us to be confident in delivering solutions which will meet security requirements, including those around legal and regulatory compliance.
There are a few key principles involved when securing data:
- Least privilege permissions – This means enforcing restriction of access to the minimum required for each user/service. It also means limiting the number of human users because each additional user which has direct access to data increases the risk of exposure.
- Identity – This is a key part of any security solution. Identity allows us to establish who or what is trying to access data.
- Security alerting - If we can alert around security breaches and vulnerabilities, it means we can proactively respond to risks and concerns as they evolve.
- Data isolation and control - This is important not only for security, but also for compliance and regulatory concerns.
Azure Data Lake allows us to easily implement a solution which follows these principles.

The benefits of ADLS
Built on Azure Storage
Azure Data Lake Store (Gen2) is built on the existing infrastructure around Azure Storage. This means that it can take advantage of the security features which are already baked into the platform.
Azure Active Directory
These include Azure Active Directory (AAD) and Role Based Access Control (RBAC). AAD allows us to control identity within our solution.
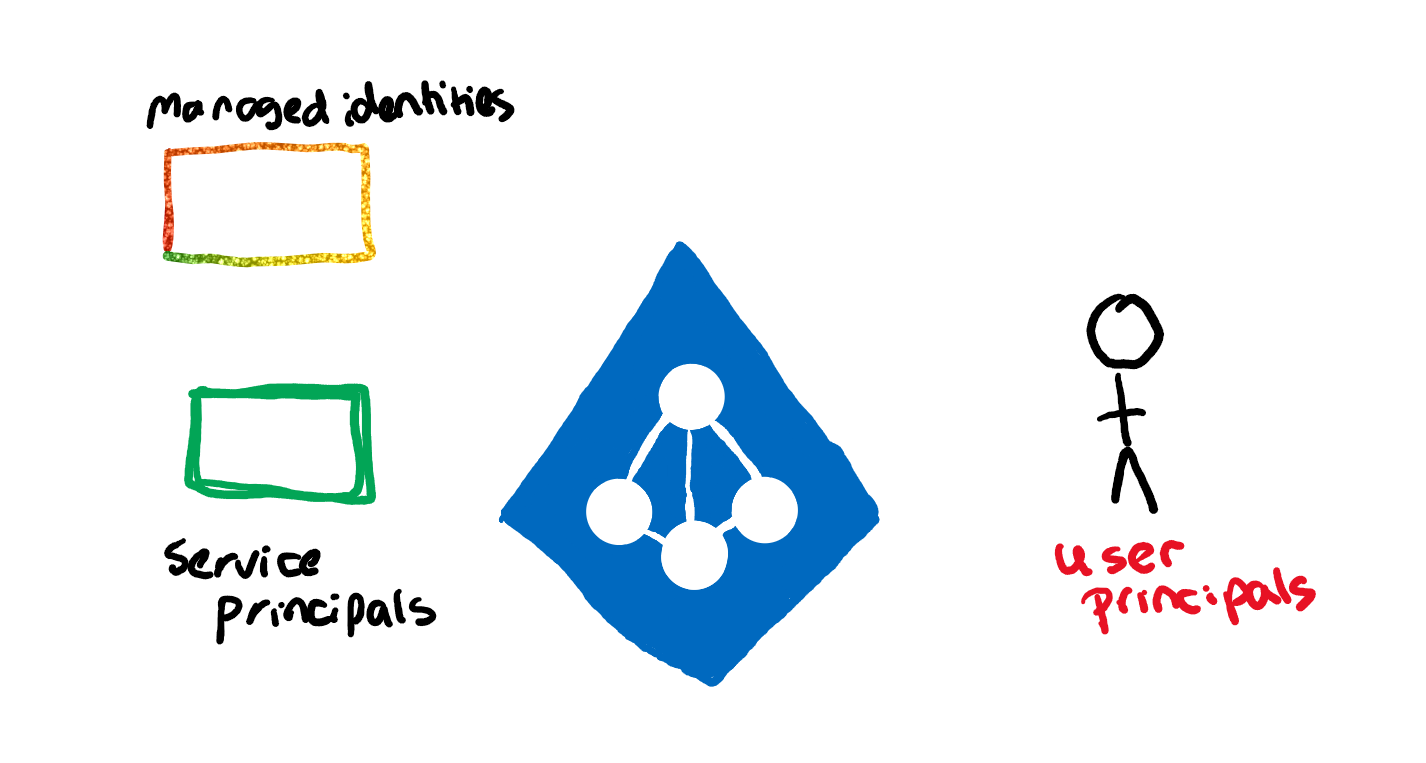
Each human user is assigned a user principal. Apps and services are assigned service principals. A specific flavour of service principals are managed identities. Managed identities are service principals for applications which are completely managed for you. Where normally, if a service needs to connect via a service principal, the credentials for the principal would need to be stored by the service. With managed identities, the identity is linked directly to the service. This removes the need for you to manage credential storage and management. For more information around identity in AAD, see this blog.
Combining this with RBAC means that we can give specific identities the well-defined permissions within the data lake.
Multi-protocol SDK
There is also a new version of the Blob Storage SDK (called the multi-protocol SDK) which can also be used with Azure Data Lake. This SDK handled all of the buffered reading and writing of data for you, along with retries in case of transient failure, and can be used to efficiently read and write data from ADLS. This is in the Azure.Storage.Blobs NuGet package. There are some limitations around the multi-protocol SDK around controlling the features which are specific to ADLS. For example, access control lists can't be controlled, and atomic manipulation isn't possible. However, there is a second (preview) SDK (in the Azure.Storage.Files.DataLake namespace) which allows the control of these features.
Low-cost storage
Azure Storage is a low-cost storage option. There is an increased cost in enabling the ADLS specific features, but it is still a very cost-effective option for storing data, with a lot of power behind it. Also included in Azure Storage is the life-cycle management system. This means that you can migrate data between hot easily accessible storage, and into colder and archive storage as data access requirements change to save a huge amount in data storage of older data.
Reliability
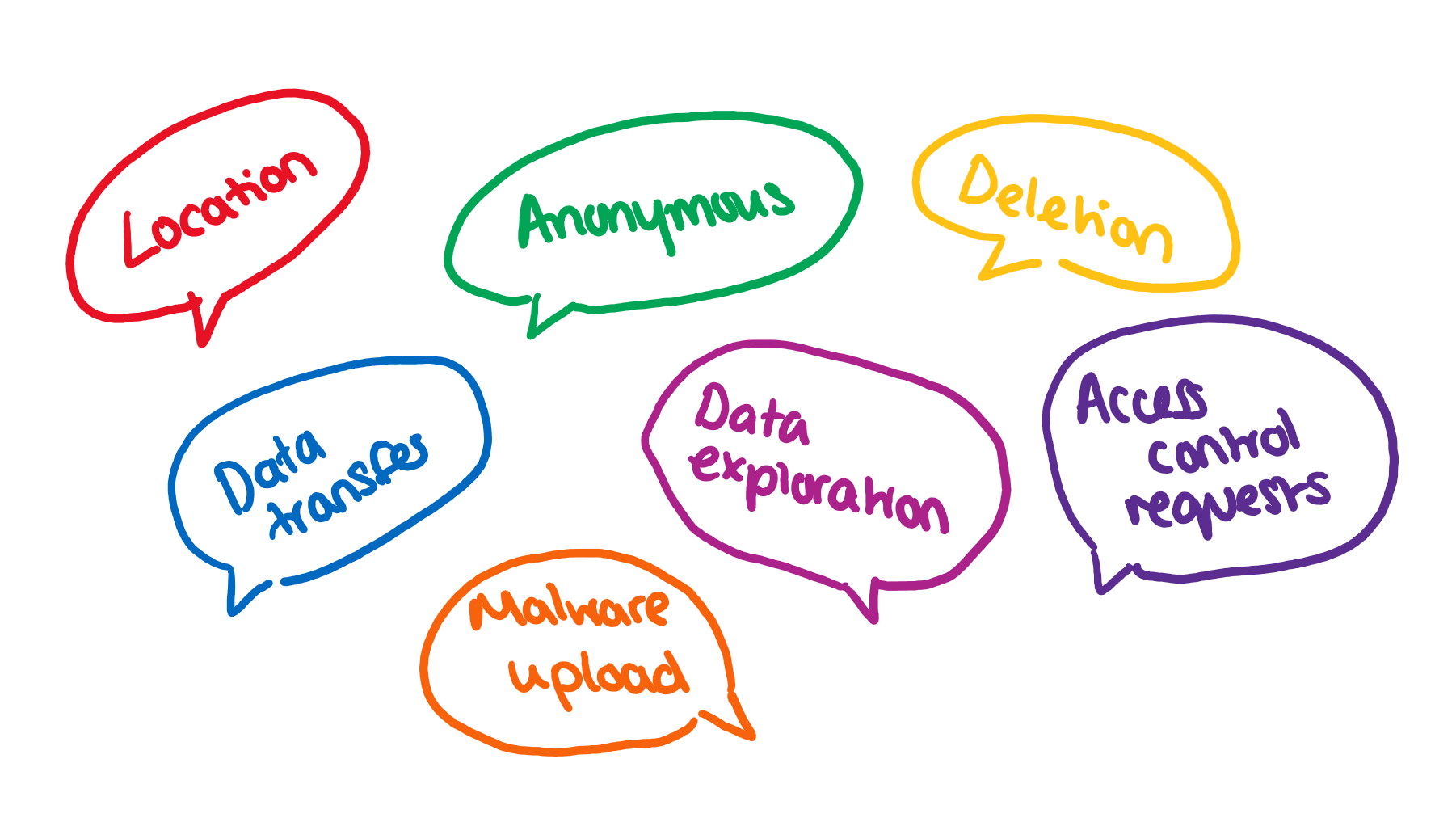
Alongside cost, Azure Storage allows us to take advantage of the in-built reliability features. The first of these is around geo-redundancy. Using Azure Storage, we have the option to create copies of data to prepare for natural disaster or localised data centre failure. Traffic can be rerouted in these cases to increase reliability and safety via data backup. The second feature which is built into the platform is Advanced Threat Detection. This integration allows you to detect a huge variety of threats, for example:
- Anonymous access
- Deletion
- Access control requests
- Data access, transfer or exploration anomalies
- Location based anomalies
- Malware uploads
You can also trigger alerts based on when these threats are identified which allows you to quickly identify and mitigate risks.
Performance
One of the main differences between standard Blob Storage and Azure Data Lake is the introduction of hierarchical namespace. This means that data can be organised in a file system like structure. For performance, this means that we can organise the data in order to reduce the data which needs to be queried and increase the performance of those queries.
ADLS is also optimized for analytical workloads. The introduction of atomic renames and writes means that fewer transactions are needed when carrying out work with the data lake. This means that each process can happen with fewer transactions, increasing processing speed.
Reliability
I have already mentioned the geo-redundancy features which are enabled via Azure Storage.
The atomic rename feature also allows for increased reliability. In many systems, we need to protect against failure by preventing partial file writes from propagating through the system. This is often achieved by creating a new file, writing data to it, and once the file is complete renaming it to signify that it is now complete. The atomic rename ability means that file updates and versioning can be easily achieved.
Scalability
Blob storage is massively scalable, but there are some storage limits. The current limits are 2 petabytes in the USA and Europe, and 500 petabytes in most other regions. However, there was an announcement at Microsoft Ignite in November that we will now be able to chain blobs together meaning that we can continue past the current storage limit. This essentially means that the storage will be infinitely scalable as we can just keep connecting more storage accounts.
Alongside this, big data analytics platforms (such as Spark and Hive) are increasingly relying on linear scaling. For linear scaling, the analytics clusters add more nodes to increase processing speed. However, to increase processing speed in this way relies on the storage solution also scaling linearly – and the elastic scaling of blob storage means that the amount of data which can be accessed at any time isn't limited. The hierarchical namespace also allows isolation of data, which further allows the parallelisation of processing.
Security
There are several features of ADLS which enable the building of secure architectures.
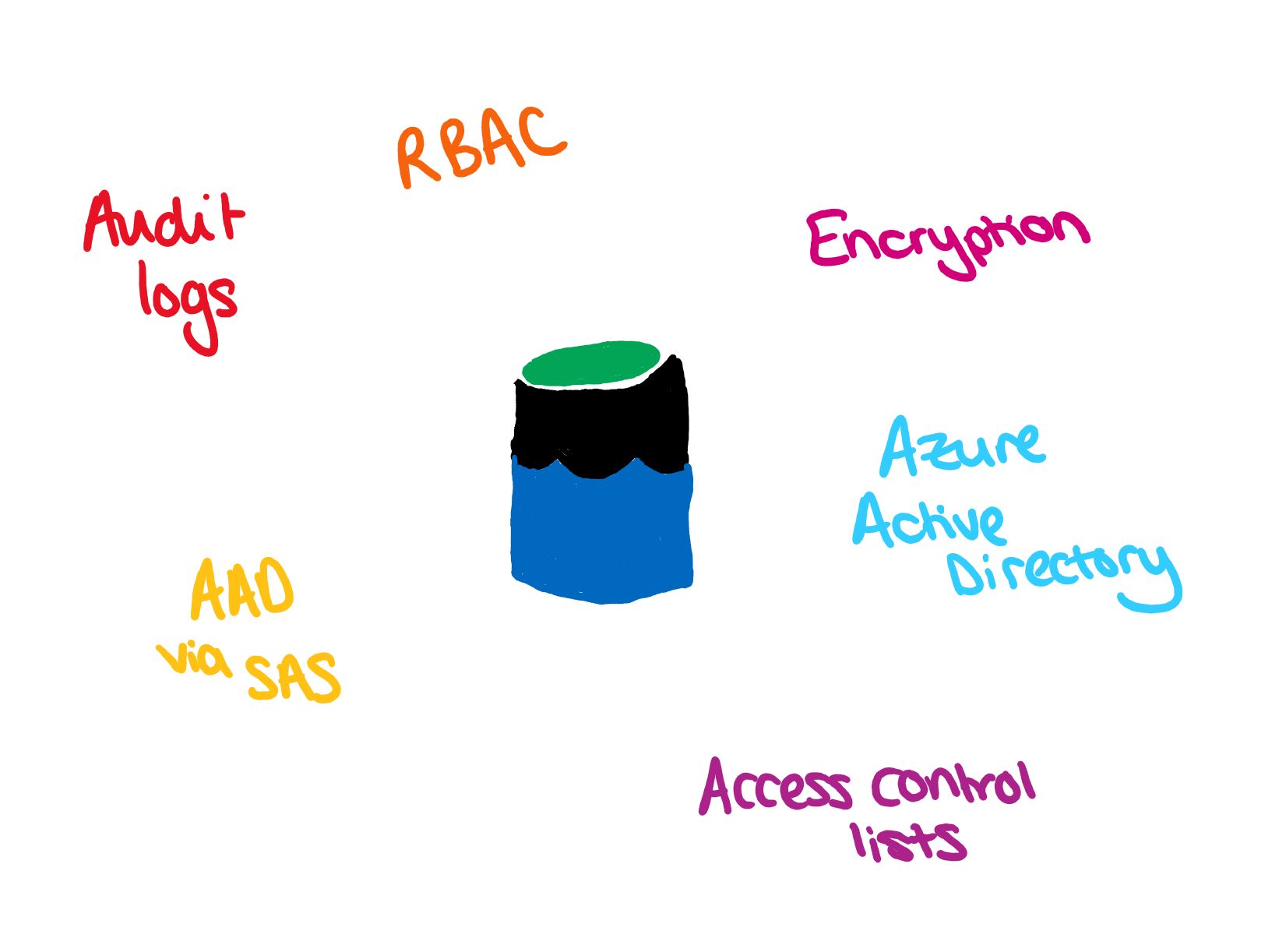
Access control lists
As I've already mentioned, AAD allows role-based access control. Azure Data Lake also provides some additional security features outside of these role-based claims. Access control lists provide access to data at the folder or file level and allows for a far more fine-grained data security system. They enable POSIX style security, which means that permissions are stored on the items themselves. Specific identities can be given read or write access to different folders within the data lake.
These folders can be applied to groups as well as to individual users or services. Using AAD groups means that access to folders can be controlled by adding/removing services from these AAD groups. It also enables for example a "developers" group to be given access to the development data and giving new team members the correct permissions/removing members' access is as simple as adding/removing them from the group.
Permissions on a parent folder are not automatically inherited. It can be set up so that any new children added to the folder will be set up with the same permissions, but this does not happen automatically and will not be applied to any existing children. This is another argument for the use of AAD groups rather than individual identities, as permissions are set on new items at the time of creation so updating these permissions can be an expensive process as it means changing the permissions on each item individually. It is also worth noting that execute permissions are needed at each level of the folder structure in order to be able to read/write nested data in order to be able to enumerate the parent folders.
An important next step in securing your data through these access control lists is giving thought to your data taxonomy. A well-defined data taxonomy allows you to organise and manage data (and is enabled by the hierarchical namespace features), isolating data as necessary. This data isolation also allows greater access control, where services can be only given access to the data they need to be. It also opens up governance possibilities where regulations around access and data isolation can be easily met and evidenced.

It is worth mentioning that if the same user/application is granted both RBAC and ACL permissions, the RBAC role (for example Storage Blob Data Contributor which allows you to read, write and delete data) will override the access control list rules.
Shared Access Signatures
There is also a feature, which is currently in preview, where SAS tokens can be created from AAD credentials. Previously these could only be created using Azure Account keys, and though these SAS tokens could be applied at a folder level, the access cannot be controlled other than be regenerating the account keys. AAD credential pass through allows role-based permissions to be passed via SAS tokens.
Encryption
Alongside the features around access control, all data is encrypted both in transit and at rest by default. This means that your data is encrypted using the latest encryption techniques, which are updated as the latest technology becomes available.
Audit
Finally, all changes made in the ADLS account are fully audited, which allows you to fully monitor and control access to your data. This combined with the insights from Azure Threat Detection allows you an incredible amount of insight into the accessing and updating of your data.
Interoperability
The fact that ADLS can be accessed via the common SDK means that anything which integrates with the Azure Storage SDK can also integrate with Azure Data Lake. This allows integration with any systems which are already based around the existing Azure Storage infrastructure.
I have talked about the fact that ADLS allows you a hierarchical namespace configuration. This also means that by using standard naming conventions, Spark, Hive and other analytics frameworks can be used to process your data. For example, Spark supports querying over a structured date organisation (e.g. year=YYYY/month=MM/day=dd etc.), meaning data can be queried over multiple partitions. The enabling of hierarchical namespaces means that standard analytics frameworks can run performant queries over your data.
Finally, there is the option of integrating with other services via Azure Event Grid. The feature is in preview but change notifications can be automatically consumed by Azure Event Grid, and routed to other subscribers allows complex data analytics to be performed over these events.
Cost
I have already mentioned the fact that ADLS is built on one of the cheapest available cloud storage solutions and have highlighted that there is a higher cost involved in enabling the ADLS features. However, I think it is worth calling out specifically that this is one of the advantages of using Azure Data Lake.
A secure architecture in practice
We often use Azure Functions when carrying out our data processing. Azure Functions is a serverless offering which is capable of complex data processing. The application of serverless principles, combined with the PAYG pricing model of Azure Functions allows us to cheaply and reactively process large volumes of data. An example of an Azure Function which reads data from a file can be seen here:
public static class AdlsDemoApp
{
[FunctionName("AdlsDemoApp")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
string fileName = await GetFileName(req);
var containerName = Environment.GetEnvironmentVariable("ContainerName");
var blobUri = Environment.GetEnvironmentVariable("BlobUri");
var tenantId = Environment.GetEnvironmentVariable("TenantId");
var tokenCredential = new DefaultAzureCredential(
new DefaultAzureCredentialOptions()
{
InteractiveBrowserTenantId = tenantId,
ExcludeInteractiveBrowserCredential = false
});
Uri containerUri = new Uri($"{blobUri}{containerName}/");
var blobContainerClient = new BlobContainerClient(containerUri, tokenCredential);
var encodedFile = HttpUtility.UrlEncode(fileName);
var blobClient = blobContainerClient.GetBlobClient(encodedFile);
BlobDownloadInfo download = await blobClient.DownloadAsync();
string content;
using (StreamReader reader = new StreamReader(download.Content))
content = await reader.ReadToEndAsync();
return content != null
? (ActionResult)new OkObjectResult(content)
: new BadRequestObjectResult("No content.");
}
private static async Task<string> GetFileName(HttpRequest req)
{
string fileName = req.Query["fileName"];
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
dynamic data = JsonConvert.DeserializeObject(requestBody);
fileName = fileName ?? data?.fileName;
return fileName;
}
}
This uses the new Azure Blob Storage SDK and the new Azure.Identity pieces in order to authenticate with AAD. The DefaultAzureCredential class is part of the Azure.Identity namespace, and will automatically try to authenticate:
- Using environment variables
- Using a managed identity
- Using a shared access token
- Via interactive browser
It will try these methods in the order shown here (interactive browser authentication needs to be specifically enabled via the DefaultAzureCredentialOptions).
Once deployed, the function will automatically authenticate via its managed identity, which means that they don't need to store any credentials in order to authenticate. The managed identity is enabled by going to the identity section from the Azure Functions App:
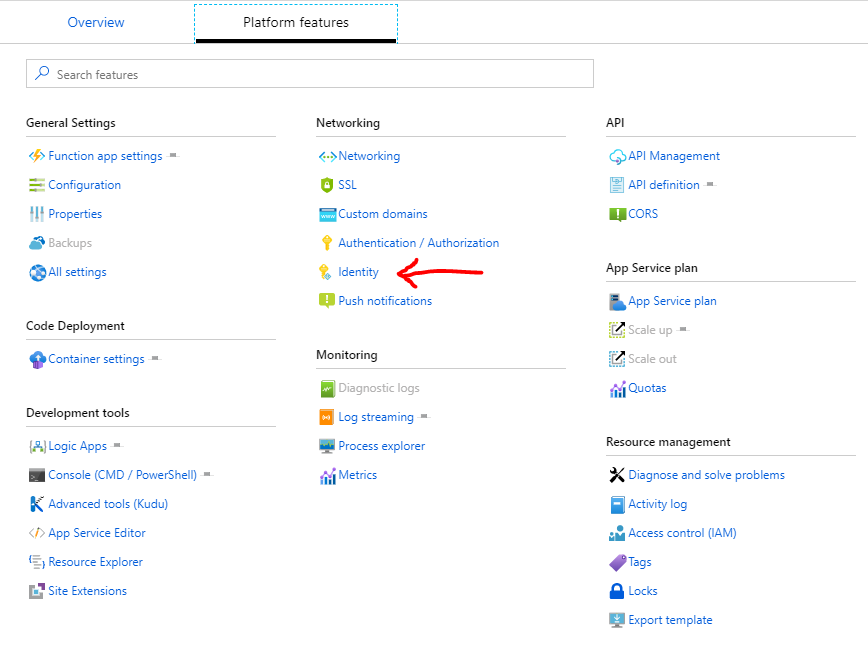
There is also the option of passing through the user credentials via an auth header and using these to access ADLS rather than authenticating using the function's managed identity. This means that access to the data is provided by the identity of the user who is calling the function. Generally, we advocate the use of managed identities and authenticating as the function. This is because this reduces the number of users who have access to the actual data, in line with the principles of least privilege access. Not only this, but it means that if you authenticate to the function, and then the function controls the authentication to ADLS, then it separates these components and provides a lot more freedom over access control.

So in this way, Azure Functions authenticate via AAD, and then use their identity to connect to the data lake.
Azure Data Lake Store then provides fine grained security control using access control lists, AAD groups and a well-defined data taxonomy which means that services have access to only the data they need. We can manage access control lists via storage explorer.
If we add the function's managed identity to the sample1 folder, and give is read and execute access:
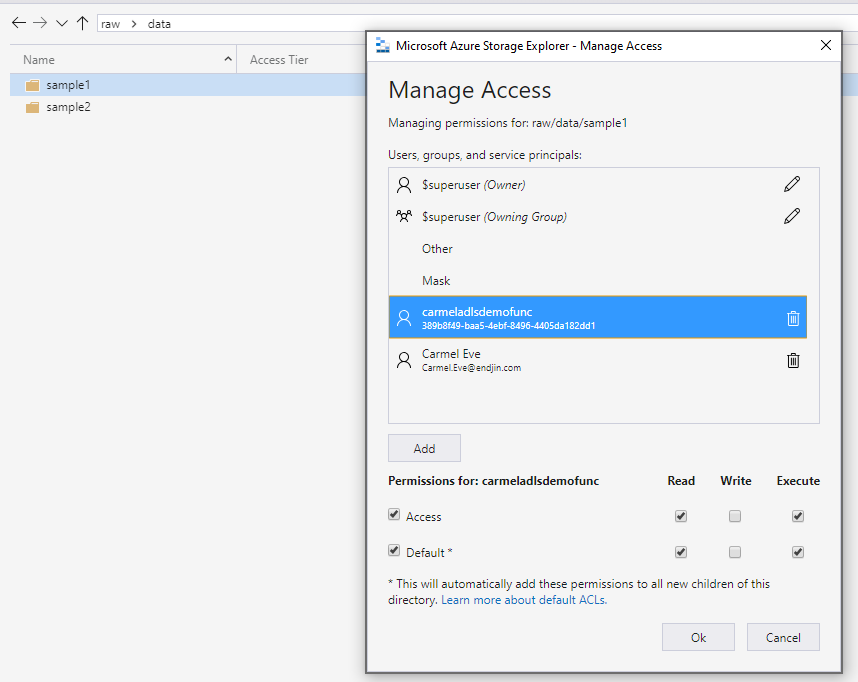
And also give the identity access all the way down through the folder hierarchy (this means that the function will be able to enumerate each folder). It is worth mentioning here that these access control lists can be controlled from within the portal, but you cannot set them at the file system level, and the execute permissions will also need to be set at this level in order to allow the function to reach the data it needs.
Once these permissions have been set, the function will be given read access to any new files added to the raw/data/sample1 folder, but will not be able to write to these files and will not be able to read data for anywhere else in the data lake.
Finally, abnormal access and risks are tracked, and alerts are raised via Azure Threat Detection, which can be enabled via the portal:
This means that risks can be tracked and mitigated as and when they emerge.
Overall
I hope this has provided a good insight into using Azure Data Lake to provide a secure data solution. As already mentioned, alongside this blog I have made a video running through these ideas.



