Snowflake Connector for Azure Data Factory - Part 1


Update, June 2020: Since writing this post Microsoft has announced an official Snowflake connector. You may still find this post useful if you are doing anything out-of-the-box, but otherwise I would recommend using the official connector. Documentation can be found here.
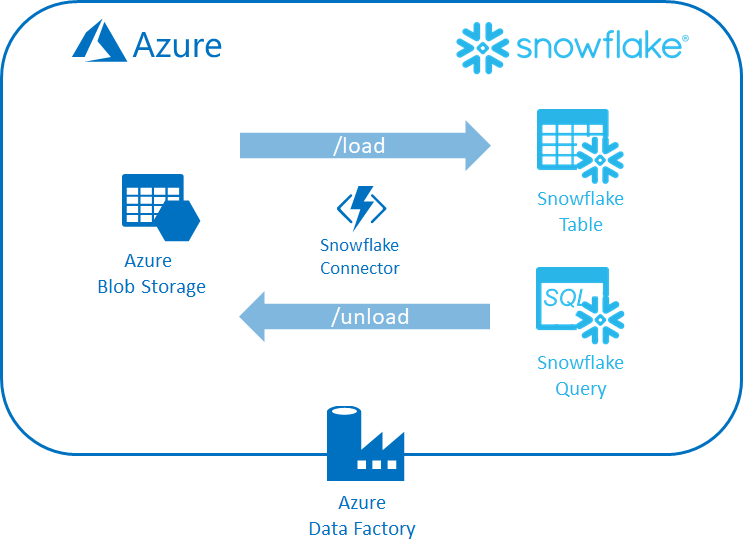
If, like me, you are a fan of Azure Data Factory and love Snowflake then you are probably disappointed that there isn't a native Data Factory connector for Snowflake.
While we wait for an official connector from Microsoft we have no alternative but to roll our own. In this blog post I will walk you through the process of doing just that. We will create a connector that can be used by Azure Data Factory to move data into Snowflake as well as being able to run Snowflake queries and export the results.
Solution Overview
Specifically, the connector will be able to:
- Copy data from an Azure Storage container or S3 bucket into a Snowflake table (AKA Data Loading)
- Run a Snowflake query and extract the results into Azure Storage container or S3 bucket (AKA Data Unloading)

I highly recommend you familiarize yourself with the process of loading and unloading data from Snowflake before proceeding.
Step 1. Create a General Purpose Snowflake Client
The connector will be written for .NET so will make use the ADO.NET Snowflake nuget package. First we will create a simple client that encapsulates the details of connecting to and issuing commands against Snowflake.
This class takes the Snowflake connection string, details of how to construct the connection string can be found on the Snowflake .NET Github page.
The client takes a collection of commands to execute, this is important since the ADO.NET client does not support submitting multiple statements in a single query. Therefore, expect to encounter an error if you tried to submit the following:
Instead, each command must be a single sql statement. If we were to execute the statement above using a separate connection our context would be lost. In effect our calls to USE DATABASE and USE SCHEMA would have no effect. We therefore require a simple way to execute batches of statements using the same connection which is why ExecuteNonQuery accepts one or more statement.
ExecuteNonQuery is handy but a bit general purpose so let's decorate it with some helper extension methods:
This adds two public methods that allow us to load and unload data from Snowflake, taking care to construct the necessary SQL statements.
We now have a client that can perform the basic operations we require to move data to and from Snowflake. The next step is to make this available to Azure Data Factory.
Step 2. Create an Azure Function Data Factory 'Connector'
Azure Data Factory can call out to HTTP endpoints to perform activities that are not natively supported. We will take advantage of this by hosting our Snowflake client in an Azure Function.
Before we get to that, lets define some POCOs that represent commands we wish to execute.

If you already know how to load and unload data into Snowflake, the commands should be self-explanatory. If you don't then I refer you to my previous advice to read up on the subject (links above).
The LoadCommand represents a request that instructs Snowflake to read one or more files from an external stage and to insert the contents into a target Snowflake table.
The UnloadCommand represents a request to execute a query and save the results to an external stage.
In practice, the stage needn't be external, however, since we are interested in moving data to and from Snowflake the chances are you will want to setup a stage for an Azure Storage container or S3 bucket.
Now we can go ahead an create our Azure Functions. We will start with a function to load data into Snowflake:
The load function accepts a json payload that deserializes into LoadCommand. This is validated and used to construct a corresponding call to SnowflakeClient.
Likewise our unload function:
Step 3. Test the functions
We can now go ahead and test the function using Postman.
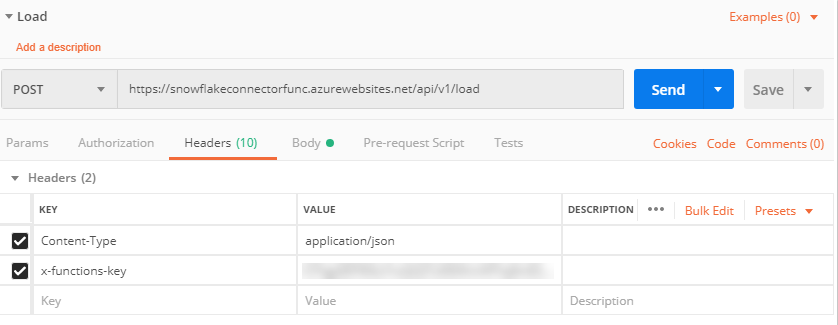
Remember to set the x-functions-key header since the function is protected with a function key.
Note: You may be wondering why I have specified `force` as true in the payload. Snowflake automatically tracks which files are loaded and by default Snowflake will ensure that any given file is loaded only once, subsequent calls will have no effect. This is very handy when you consider running an Azure Data Factory pipeline, this means there is no need to issue any calls to clean-up data you have previously imported if you need to re-run the pipeline due to a subsequent failing activity. This is just one example of how the folk at Snowflake have really considered how people use data in the real world. Of course if you do need to run a file in more than once, you can specify the `force: true` which is what I've done here.
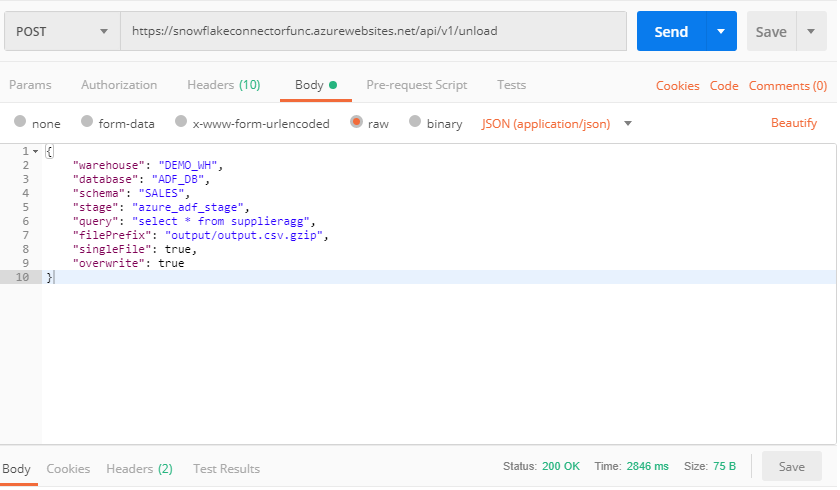
To unload data we call the unload endpoint:
WARNING: It is important to guard against the risks associated with SQL string concatenation especially when user input is involved. Always ensure that end users cannot indirectly alter SQL statements by manipulating user inputs or that the risk is otherwise mitigated.
Wrap up
We have successfully written a function that allows us to easily load data into Snowflake from an Azure Storage container or S3 bucket as well as querying Snowflake and exporting the results. In the next post I'll wire it up into a Data Factory pipeline.