Snowflake Connector for Azure Data Factory - Part 2


Update, June 2020: Since writing this post Microsoft has announced an official Snowflake connector.
You may still find this post useful if you are doing anything out-of-the-box, but otherwise I would recommend using the official connector.
Documentation can be found here.
In the last post, I explained how to create a set of Azure Functions that could load data into Snowflake as well as execute Snowflake queries and export the results into your favorite cloud storage solution. In this post I will show how we can use these functions in Azure Data Factory to plug Snowflake into your wider cloud data strategy.

A Quick Recap
In the last post we created an Azure Function app containing 2 HTTP endpoints:
v1/Load- submits a request to Snowflake to load the contents of one or more files into a Snowflake tablev1/Unload- submits a request to Snowflake to execute a query and unload the data to an Azure Storage container or S3 bucket
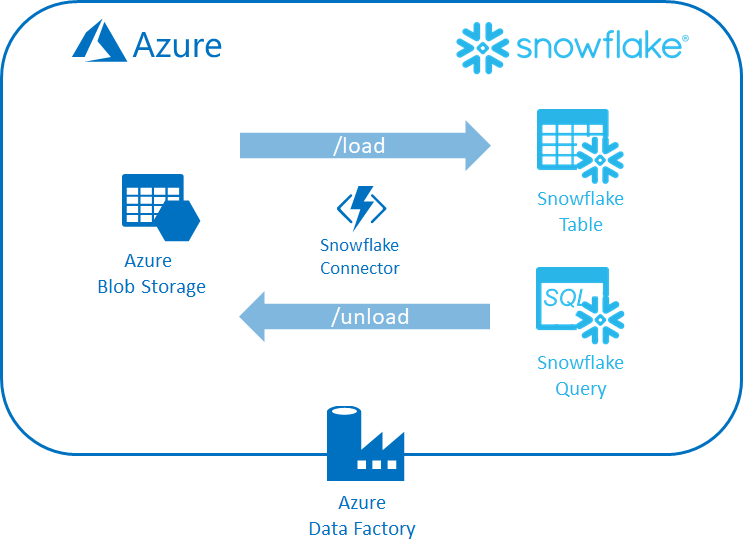
The pipeline will first load an input file stored in an Azure Blob into a Snowflake table. It will then execute a Snowflake query that generates aggregated data and stores the results in our Azure Storage container as another Azure Blob.
Snowflake database
The target Snowflake database comprises of:
- A table called
LINEITEMwhich will be populated from the input file - A view called
SUPPLIERAGGwhich returns aggregated supplier information from theLINEITEMStable - An external stage called
AZURE_ADF_STAGEwhich references our target Azure Storage account.
You can use the following script to set up the Snowflake environment.
<azure storage container url>should be replaced with the URL to your Azure Storage container.<azure storage container sas token>should be replaced with a valid SAS token.
Now that the target database has been setup we can go-ahead and create the pipeline.
Data Factory Pipeline
The first thing is to setup a linked service to our Snowflake connector Azure Function app.
Create a new Azure Function linked service:
Specify the Function app and function key:

Add a new pipeline. To make the pipeline a bit more generic we are going to add some parameters:

inputPath: the relative path to the file we are loading into SnowflakeoutputPath: the relative path to the output file that will contain the results of our querydatabase: the name of the target Snowflake databasewarehouse: the name of the Snowflake virtual warehouse to use
Next we require an Azure Function activity that will load the data from source blob storage account:
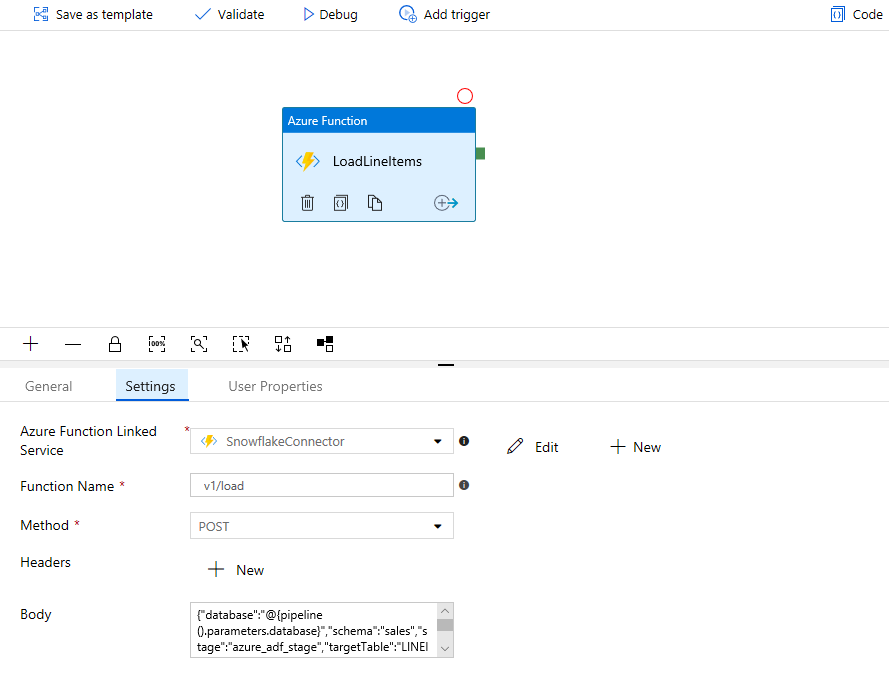
The body property represents the request we need to submit to the connector. Since our pipeline is dynamic we will need to to use an ADF expression to construct the request.
{
"database":"@{pipeline().parameters.database}",
"schema":"sales",
"stage":"azure_adf_stage",
"targetTable":"LINEITEM",
"files":["@{pipeline().parameters.inputPath}"],
"warehouse":"@{pipeline().parameters.warehouse}"
}
WARNING: It is important to guard against the risks associated with SQL string concatenation especially when user input is involved. Always ensure that end users cannot indirectly alter SQL statements by manipulating pipeline inputs or that the risk is otherwise mitigated.

Before running the pipeline you will need to upload a file containing sample data into your target storage account.
You should now be able to run the pipeline, when the pipeline finishes you should find the LINEITEM table has been populated.

Next, add another activity to run a query that returns aggregate supplier information.
Add a second Azure Function activity to the pipeline:

This time the request body expression should be:
{
"database":"@{pipeline().parameters.database}",
"schema":"sales",
"stage":"azure_adf_stage",
"query":"select * from SupplierAgg",
"filePrefix":"@{pipeline().parameters.outputPath}",
"overwrite":true,
"warehouse":"@{pipeline().parameters.warehouse}"
}
After running the pipeline again, you should find the output file containing the query results have been written to blob storage.

Note that by default Snowflake will use gzip compression when writing files. Compression options are defined either in the format type options of the copy command or when creating the stage.
So there you have it. You can now harness the power of Snowflake within your data pipelines.
All the code in this series is available on Github.
If you have any questions or if there is any specific Snowflake topic you would like to see covered in a future post then please let me know in the comments section below.