Overflowing with dataflow part 1: An overview


In a recent project, I was asked to produce a tool for importing a fairly large amount of data at once, this data then needed to be processed and exported. After much refactoring, I achieved a solution I was satisfied with which used TPL dataflow to execute the processing in parallel. Before I talk specifically about TPL dataflow (this will now be the subject of a following blog as this one grew slightly unwieldly as time went on), I thought I'd give a brief overview of dataflow in general.
Please excuse the coming awful puns, I couldn't stop them once they started flowing
Since I started this blog my understanding of dataflow has developed, and exactly how I picture it working has changed. However, my initial interest in the subject has only grown and its definitely taking a place of pride in my growing list of exciting things I've learnt this year. I think it's a highly expressive and understandable way of representing data processing.
The crucial thing to understand when using dataflow, is that the data is in control. In most conventional programming languages, the programmer determines how and when the code will run. In dataflow, it is the data that drives how the program executes. The movement of data controls the flow of the program (as Mark Carkci put it in his book on Dataflow & Reactive programming systems, "data is king").
The main components in a dataflow model are blocks (which are activated by the arrival of data) and links (here I am using the TPL dataflow syntax, these fundamental concepts are called many things, most broadly nodes and arcs). These concepts are easily represented with the aid of a diagram.
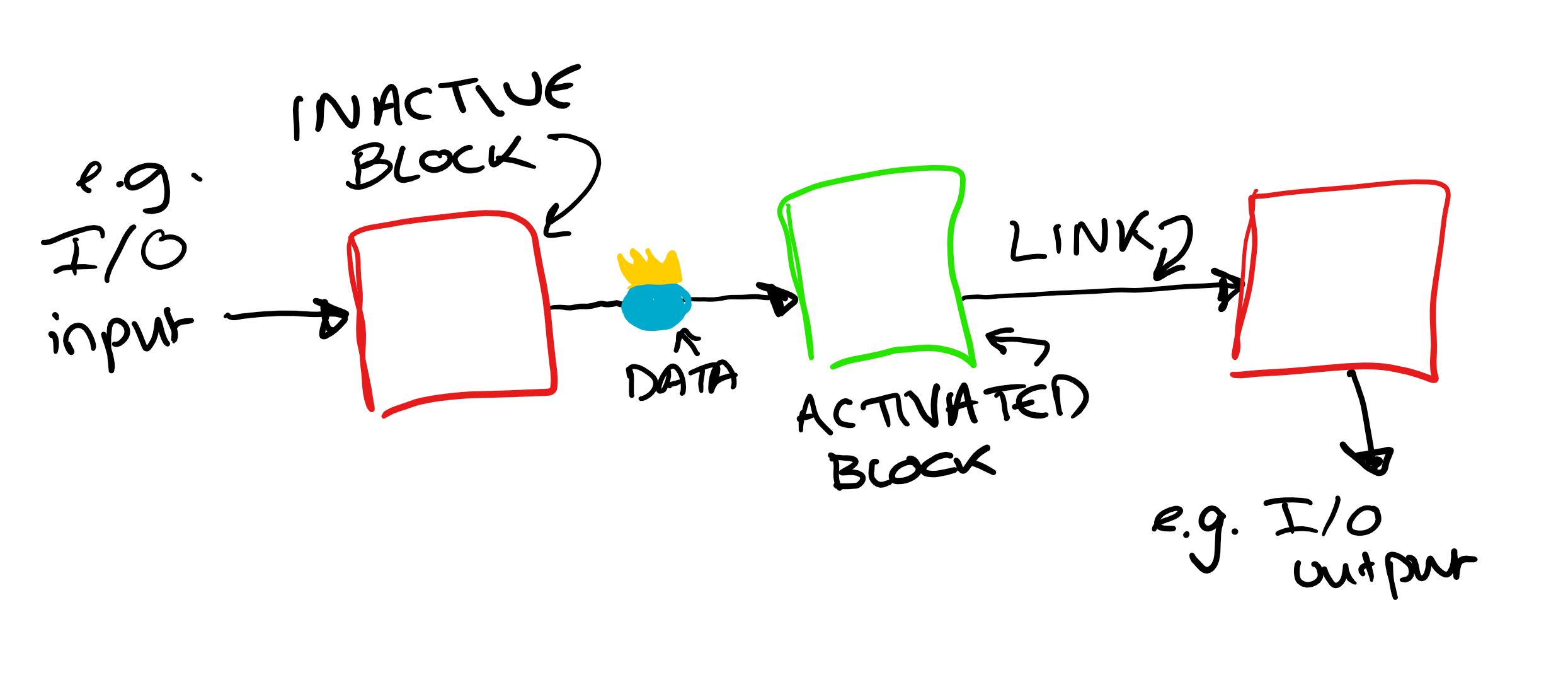
My name's Sher-block Holmes, it is my business to process your data
Blocks contain the code which does the processing of the data. When data arrives at a block, it causes the code it contains (or internal method) to execute. Blocks generally have input and output ports. It is data arriving on an input that causes the execution, and then any results are placed onto the output port. This output port can then be connected to other blocks via links. The overall conditions for a block to execute are such that there needs to be data waiting on the input, and there must be space on the output for the result.

There are different types of block which build up a dataflow model. One of the crucial ideas is compound blocks. This means blocks which are built up of other blocks. This allows us to build up complex systems out of more simple entities These compound blocks can be thought of as small dataflow programs within the wider context. Compounds blocks are important because they firstly make code more understandable, and secondly maximise code reuse. Both of these concepts are critical in the building of any sustainable program.
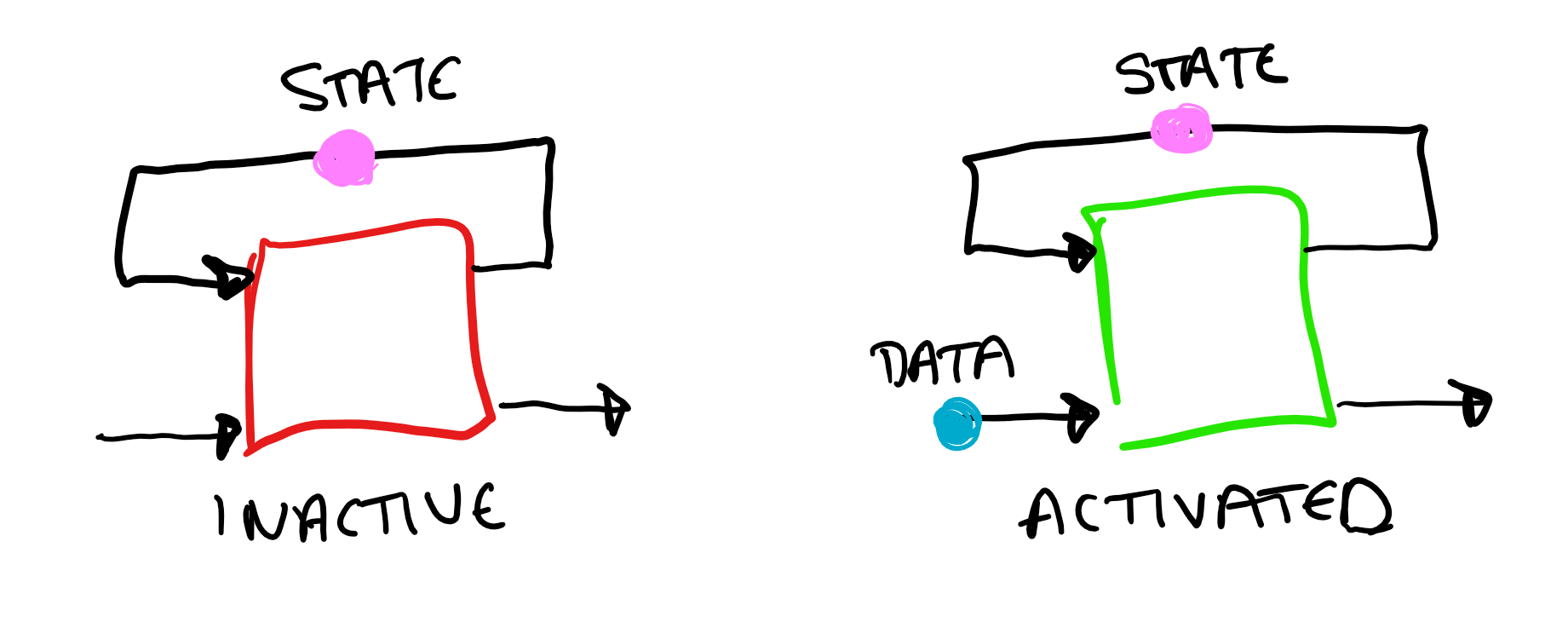
Another important thing to consider is the difference between functional and stateful blocks. Functional blocks hold no state. If you put the same piece of data through you will always get the same output. Functional blocks can act like stateful blocks, however this requires multiple inputs/outputs…
It is possible for blocks to have multiple inputs and outputs, though this is not intrinsically supported in TPL dataflow. If a block has multiple inputs, then a firing pattern is needed to tell the block when to execute. This defines which inputs need data on them in order for the block to activate. For example, if a block has three inputs you could define a condition that there must be data on input 1, and then on one of either 2 or 3 for the block to execute. For multiple inputs, we update our overall conditions of execution to require the firing pattern to be met, and for there to be space on the output.
For a functional block to act like a stateful block, it needs at least two inputs. To retain state, one of the block's outputs is linked up to one of its own inputs and the state is passed back. The firing pattern would then be such that the block needs a data input and a state to execute.
If only I could think of a way to link these paragraphs together
Data moves between blocks by travelling down the links. In this way, a processing pipeline can be constructed. The transferred data can either pushed or pulled down the links. Usually in dataflow systems the data is pushed (the producer offers up the data when it is ready, *cough cough* Rx *cough cough*). In TPL dataflow these links work through message passing.

In a message passing system, messages are stored in a first-in-first-out queue. Each message must be received before the following one can be accessed. Usually each message is only read once, once it has been received it is removed from the queue. Multiple senders can add to the queue. The data will then just be processed sequentially with no regard for where the messages originated. You can also hook up multiple readers to a message passing channel, however when a message is read by any one of the receivers, it will be removed from the queue and will not be read by the others. In order to send the same message to multiple receivers you would need a block that has one input and sends a copy of the data down multiple output channels.
Make way for the king!
And now onto the data itself… There are boundless possibilities for the types of data that could be processed using dataflow. However, in general, it is highly recommended that immutable data is used. The reason for this is two-fold:
- Immutable data eliminates concurrency issues surrounding reading/writing.
- If data is mutable, a deep copy needs to be made every time the data is sent to multiple blocks, which can be expensive and time consuming.
Now, it is not always possible for data to be completely immutable. But in these situations, care must be taken, especially when processing is being done in parallel.
Putting all of these pieces together, we have a reactive and highly configurable system for processing data. Look out for my next blog on how to implement these concepts using TPL dataflow!