Using Python inside SQL Server


Hello everyone. Before Christmas I played around with SQL Server 2017's inline Python integration capability. This capability was announced early last year, with the corresponding integration with R already being possible for a number of months. The main benefits from this are the abilities to:
- Eliminate data movement (having to transfer data samples from a database to a Python IDE using local compute resources)
- Easily operationalize Python code inside SQL
- Achieve enterprise grade performance and scale (much faster mechanism than ODBC)
So the huge benefit is the ability to stay within your preferred IDE, connect to a SQL Server instance and do the computations on the SQL Server Machine. So no more clunky data transferring! To address the second point – operationalizing a Python model/script is as easy as calling a stored procedure. So any application that can speak to SQL Server can invoke the Python code and retrieve the results. Awesome!
In this blog I will provide a few, simple examples which make use of this capability to carry out some simple Python commands. I shan't go through the installation and set-up of the Machine Learning Services feature, because it has already been done elsewhere. Instead, I'll just point you to the Microsoft docs.
Syntax
The Python integration is enabled by the 'sp_execute_external_script' stored procedure, which is enabled as part of the installation & configuration process detailed in the link above. The stored procedure and its parameters look like this:
sp_execute_external_script
@language = N'language',
@script = N'script'
[ , @input_data_1 = N'input_data_1' ]
[ , @input_data_1_name = N'input_data_1_name' ]
[ , @output_data_1_name = N'output_data_1_name' ]
[ , @parallel = 0 | 1 ]
[ , @params = N'@parameter_name data_type [ OUT | OUTPUT ] [ ,...n ]' ]
[ , @parameter1 = 'value1' [ OUT | OUTPUT ] [ ,...n ] ]
The official details of this stored procedure can be found through the link I've posted at the bottom of this page. Although I'll explain the parameters here in my own words and include any comments I think are worth knowing:
- @language = The language that you want to use. Currently R or Python
- @script = This is where the script goes. Be careful! Indentations are important in Python. Even if the stored proc parameter is indented, you must write the script as you would in your preferred Python IDE (i.e. push the code all the way to the left with correct indentations).
- @input_data_1 = T-SQL query that specifies the input data
- @input_data_1_name = The name you want to give the dataset which is used inside the Python script. The default is 'InputDataSet'.
- @output_data_1_name = Whatever the name of the variable in the Python script which contains the data you'd like to be returned to SQL Server. This must be of type pandas* DataFrame (or pandas Series, naturally).
- @parallel = Enables parallel execution of scripts. Some functions already handle parallelization, and in these cases this parameter should stay at the defualt zero. Best to do further reading into the functions you're using to make this decision.
- @params = List of the input parameters used in the Python script and their corresponding data types.
- @parameter1 [,...n] = List of values for the input parameters. So Python_variable_1 = Value_1 (which can, of course, be an unspecified input parameter of the stored procedure). So Python_variable_1 = SP_variable_1. I find naming these variables different things helps avoid any confusion.
Note: Pandas is a popular data wrangling library for Python. It's imported in the Python script by default (invisibly), although if you want to name it as 'pd', or some other alias, you will need to state that explicitly.
Examples
So let's see how this works with a few examples.
Example 1
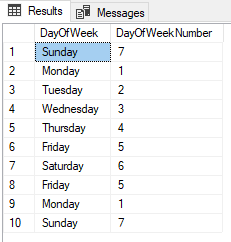
The first example is a script that maps the day number (1-7) to the day of the week (Mon-Sun) (which is based on this example. Please refer to these docs for licensing agreements). I've modified it a little so that there's less going on than in their example.
So some input data is inserted with this command:
DROP TABLE IF EXISTS DaysOfWeek
CREATE TABLE DaysOfWeek (
[DayOfWeek] nvarchar(10) NOT NULL
)
GO
INSERT INTO DaysOfWeek VALUES
('Sunday'),
('Monday'),
('Tuesday'),
('Wednesday'),
('Thursday'),
('Friday'),
('Saturday'),
('Friday'),
('Monday'),
('Sunday')
GO
Which, as you can see, is just a table with one column.
The day mapping query looks like this:
EXEC sp_execute_external_script
@language = N'Python',
@script = N'
OutputDataSet = InputDataSet
global daysMap
daysMap = {
"Monday" : 1,
"Tuesday" : 2,
"Wednesday" : 3,
"Thursday" : 4,
"Friday" : 5,
"Saturday" : 6,
"Sunday" : 7
}
OutputDataSet["DayOfWeekNumber"] = pandas.Series([daysMap[i] for i in OutputDataSet["DayOfWeek"]], index = OutputDataSet.index, dtype = "int32")
',
@input_data_1 = N'SELECT * FROM DaysOfWeek',
@input_data_1_name = N'InputDataSet'
WITH RESULT SETS (("DayOfWeek" nvarchar(10) null,"DayOfWeekNumber" int null))
Now, since the default value for the parameter '@input_data_1_name' is 'InputDataSet', I needn't have it in there. But I do. Oh well. :) The other point worth mentioning in this example is the WITH RESULT SETS command at the bottom. To quote the docs for the stored procedure:
"By default, result sets returned by this stored procedure are output with unnamed columns. Column names used within a script are local to the scripting environment and are not reflected in the outputted result set. To name result set columns, use the WITH RESULTS SET clause of EXECUTE."
Which is a bit annoying, but again – oh well.
The output of this query (found in the 'Results' pane in SSMS) looks like this:
In-lining the whole Python script is all well and good if the script is short – but how about when you have a large script? This would look messy inside a stored procedure. To that end, I took it upon myself to figure out how to package up a Python file and to be able to import it within the script.
This is done in the normal Python way: Create a folder and insert a blank 'init.py' file along with your Python files which include the definitions you have created. Now this folder needs to be placed somewhere Python (or SQL in this case) can see it.
Now an easy way to do this in a Python IDE is finding out what the system paths are using the sys.path function. Then you can either just plonk your packaged folder somewhere along one of those paths, or use the sys.path.append command to add a custom directory to the system paths so that the interpreter can find the file.
However, the only way I've got it working inside SQL is by putting the custom package inside the SQL Server's own PythonPath that is created when the Python Machine Learning Services feature is installed. Of course, this isn't ideal, as the package could be wiped if there is an update or reinstallation of SQL Server.
So, ideally, the custom packages would be placed outside the install folder – but we (my colleagues and I) are yet to find a way to get this working. I've reached out to the Microsoft Developer Network, but if anyone reading this has any solutions/suggestions, I'd be very grateful to hear them!
Anyway, after placing the packaged-up files inside the PYTHON_SERVICES folder inside the SQL instance directory, all you have to do is import the module and invoke its definition.
In Spyder, the definition looks like this:
def map_days(InputDataSet):
import pandas
OutputDataSet = InputDataSet
global daysMap
daysMap = {
"Monday" : 1,
"Tuesday" : 2,
"Wednesday" : 3,
"Thursday" : 4,
"Friday" : 5,
"Saturday" : 6,
"Sunday" : 7
}
OutputDataSet["DayOfWeekNumber"] = pandas.Series([daysMap[i] for i in OutputDataSet["DayOfWeek"]], index = OutputDataSet.index, dtype = "int32")
return OutputDataSet
And invoking it directly in SQL:
EXEC sp_execute_external_script
@language = N'Python',
@script = N'
from MyPackages.pysql_examples.day_mapper import map_days
OutputDataSet = map_days(InputDataSet)
',
@input_data_1 = N'SELECT * FROM DaysOfWeek',
@input_data_1_name = N'InputDataSet'
WITH RESULT SETS (("DayOfWeek" nvarchar(10) null,"DayOfWeekNumber" int null))
Which produces the same output as the previous example.
One can easily make this into a stored procedure with an input variable that takes a table of the same schema as our sample table, as shown in the code here:
DROP PROCEDURE IF EXISTS MapDays2;
GO
CREATE PROCEDURE [dbo].[MapDays2] (@DaysOfWeekTable nvarchar(max), @RowsPerRead INT)
AS
EXEC sp_execute_external_script
@language = N'Python',
@script = N'
print(" ******************************** \n This is one batch of the dataset. \n ********************************")
OutputDataSet = InputDataSet
global daysMap
daysMap = {
"Monday" : 1,
"Tuesday" : 2,
"Wednesday" : 3,
"Thursday" : 4,
"Friday" : 5,
"Saturday" : 6,
"Sunday" : 7
}
OutputDataSet["DayOfWeekNumber"] = pandas.Series([daysMap[i] for i in OutputDataSet["DayOfWeek"]], index = OutputDataSet.index, dtype = "int32")
',
@input_data_1 = @DaysOfWeekTable,
@input_data_1_name = N'InputDataSet',
@params = N'@r_rowsPerRead INT',
@r_rowsPerRead = @RowsPerRead
WITH RESULT SETS (("DayOfWeek" nvarchar(10) null,"DayOfWeekNumber" int null))
The other parameter @r_rowsPerRead determines the number of batches in which to execute the code. So if your dataset has 10000 entries, and you set the @RowsPerRead parameter as 5000, the stored procedure will execute the script twice. This is especially good for large datasets and limited compute resources. The first 'print' command tries to show this capability in the output after the stored proc has been executed.
So we execute using a command like the following:
EXEC MapDays2 @DaysOfWeekTable = 'SELECT * FROM DaysOfWeek', @RowsPerRead=5;
And, in the 'Results' pane, we have the same output as before. In the 'Messages' pane, where any written output from the Python script is stored, we see this:

Which shows that the query has been executed in two batches.
Example 2
The second example is a simple script that generates a list of random numbers based on start number, end number and length. Here's the query for this:
DECLARE @Start_Value INT = 0
EXEC sp_execute_external_script
@language = N'Python',
@script = N'
import numpy as np
import pandas as pd
Start = 10 ##Change the value to 10 from the initialized value of 0
random_array = np.array(np.random.randint(Start,End+1,Size))
pandas_dataframe = pd.DataFrame({"Random Numbers": random_array})
',
@output_data_1_name = N'pandas_dataframe',
@params = N'@Start INT, @End INT, @Size INT',
@Start = @Start_Value, @End = 100, @Size = 20
WITH RESULT SETS (("Random Numbers" INT not null))
I've purposefully created a mix of declared variables and constants, to show that everything can be altered inside the script if needs be. For example, I declared the variable @Start_Value as an integer equal to zero before entering the stored procedure, but then inside the stored procedure I changed its value to 10. Likewise, the constants I've set for @End and @Size will stay the same unless you say otherwise.
Here's the output of this query:

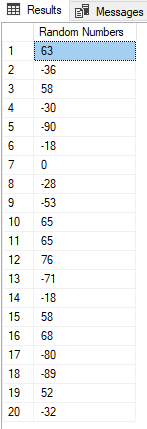
Which, as you can see, is a list of length 20 with random integers between 10 and 100. This query can again be easily changed into a stored proc, with all 3 variables passed in as arguments:
DROP PROCEDURE IF EXISTS GenerateRandomNumbers;
GO
CREATE PROCEDURE GenerateRandomNumbers (@Start_Value INT, @End_Value INT, @Size INT)
AS
EXEC sp_execute_external_script
@language = N'Python',
@script = N'
import numpy as np
import pandas as pd
random_array = np.array(np.random.randint(Start,End+1,Size))
pandas_dataframe = pd.DataFrame({"Random Numbers": random_array})
',
@output_data_1_name = N'pandas_dataframe',
@params = N'@Start INT, @End INT, @Size INT', --Params the Python script uses
@Start = @Start_Value, --LHS must match up with params inside Python script
@End = @End_Value, --RHS must match up with procedure params
@Size = @Size
WITH RESULT SETS (("Random Numbers" INT not null))
And a sample execution:
EXEC GenerateRandomNumbers @Start_Value = -100, @End_Value = 100, @Size = 20;
Which returns, as expected (or unexpected?):
Example 3
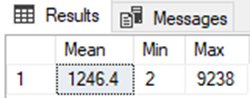
The final example, and the simplest of the lot, calculates a few values (mean, min, max) from a list. Here's the query:
EXEC sp_execute_external_script
@language = N'Python',
@script = N'
mylist = [124, 9238, 23, 1244, 2, 98, 13, 103, 774, 845]
list_mean = sum(mylist) / float(len(mylist))
list_min = min(mylist)
list_max = max(mylist)
print(" The mean value is: {0} \n The minimum value is: {1} \n The maximum value is: {2}".format(list_mean,list_min,list_max))
OutputDataSet = pandas.DataFrame({"Mean": [list_mean], "Min": [list_min], "Max": [list_max]}, columns = ["Mean","Min","Max"])
'
WITH RESULT SETS (("Mean" float not null, "Min" float not null, "Max" float not null))
So the output in the 'Results' pane is:
And the output in the 'Messages' pane is:

That example draws an end to this blog about the Python integration in SQL. Although very simple, I've tried to structure the examples to cover all the stuff that I was confused by when I first used this feature.
Then again, I hadn't really used SQL much before I started looking into this Python integration! Before I sign off, below I've listed a few resources I found helpful whilst learning about this feature. The last link points to the github repo which contains all the source code:
- sp_execute_external_script: https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-execute-external-script-transact-sql - stored proc docs
- Machine Learning Services with Python in SQL: https://learn.microsoft.com/en-us/sql/machine-learning/sql-server-machine-learning-services - Includes the information needed to get started with Python in SQL, including tutorials. If you are going through the Taxi Fare experiment, refer to the github repo for accurate versions of the code: https://github.com/Azure/Azure-MachineLearning-DataScience/tree/master/Misc/PythonSQL
- Advanced Analytics in SQL documentation as a pdf: (no longer available)
- Video about Python in SQL from Microsoft: https://www.youtube.com/watch?v=FcoY795jTcc - Microsoft video going through the details of Python in SQL, its benefits and use cases. Also goes through the tutorial upon which the DaysOFWeekExample above is based. Helpful video.
- Non-Microsoft blog: https://www.sqlshack.com/how-to-use-python-in-sql-server-2017-to-obtain-advanced-data-analytics/ - Helpful blog written by Prashanth Jayaram with some nice examples.
- Source code repo: https://github.com/edfreeman/PySQL_Examples
Hope this blog helps, and thanks for reading!