Data validation in Python: a look into Pandera and Great Expectations


Data validation is the process of verifying that data is in an acceptable state for downstream processing (analytics, visualisations, machine learning, etc). It's important for data to conform to the expectations of downstream consumers so that they can use it with confidence; poor data quality issues that go unresolved can have significant deleterious impact on production systems.
Pandera and Great Expectations are popular Python libraries for performing data validation. In this blog post I'll provide a broad overview of the features of each library, demonstrate how to create some basic validation tests with them, and provide some thoughts as to which one you should use.
Data validation - a typical scenario
The type of scenario we're going to look at is one that is typical in the data processing world (i.e.: data science & engineering), for which these libraries are designed. Generally, it looks as follows: you've ingested some raw data that could have quality issues, before going on to do useful things with the data, like analytics and visualisation, you need to verify that it's of adequate quality and meets the expectations of downstream consumers.
Take the following boat sales data, an edited extract from this Kaggle dataset, containing 7 columns: 'Id', 'Price', 'Currency' 'Boat Type', 'Year Built' 'Length', 'Number of visits in the last 7 days'.
| Id | Price | Currency | Boat Type | Year Built | Length | Number of views last 7 days |
|---|---|---|---|---|---|---|
| 0 | 3337 | CHF | Motor Yacht | 2017 | 4.0 | 226 |
| 1 | 3490 | EUR | Center console boat | 2020 | 4.0 | 75 |
| 2 | 3770 | CHF | Sport Boat | 0 | 3.69 | 124 |
| 3 | 25900 | DKK | Sport Boat | 2020 | 3.0 | 64 |
Some validation rules immediately come to mind:
- The values in the 'Id' column should be distinct from one another
- The values in the 'Price' column should be of type int
- The 'Currency' and 'Boat Type' are categorical variables, therefore those columns should only take values from defined sets
- None of the columns should have missing data
These are the basic sorts of the validation rules you want to check your data against. You could go on to define slightly more sophisticated rules, such as:
- The number values in the 'Year Built', 'Length' and 'Number of view last 7 days' columns should fall within some sensible range for each column
What do you want in a data validation tool?
At a basic level, you want to be able to define validation rules (i.e. expectations of the data) - like the ones described, validate data against the rules, and have the tool inform you about cases that do not pass the validation. Based on the output of the validation, you can then go on to address the failing cases by whatever means you like. As we'll see though, the two packages under question can do quite a bit more than that.
Let's take a look at the two tools under question in this blog post, starting with Pandera.
Pandera
From their official documentation:
A data validation library for scientists, engineers, and analysts seeking correctness.
You can download Pandera from PyPI. When I did this, it resulted in a total of 12 packages being installed on my machine. Pandera provides a DataFrameSchema type, which provides an easy way for you to define a set of validation checks against the columns in your data. After creating the schema object you can use it to validate against data frame types; the library supports validating against data frame type objects from multiple providers, however we'll just looking at the Pandas DataFrame in this blog.
Implementing validations for boats sales data
Let's implement the basic validation rules described earlier inside a Pandera schema.
schema = DataFrameSchema(
{
"Id": Column(int),
"Price": Column(int),
"Currency": Column(float, Check.isin(["CHF", "EUR", "DKK", "£"])),
"Boat Type": Column(str, Check.isin(boat_types)),
"Year Built": Column(int, Check.in_range(1950, 2022), coerce=True),
"Length": Column(float, Check.in_range(0.5, 110.0)),
"Number of views last 7 days": Column(int, Check(lambda x: 0 <= x < 3500)),
},
unique=["Id"],
)
The code above captures the data validation tests suggested at the start of the post in a Pandera schema. The code is quite succinct and doesn't look too dissimilar to Pandas code, which is nice. It could also have been written in YAML or JSON; the library provides functions for converting schemas between the different languages, too.
Pandera provides lots of built in checks, some of which I've used above, like Check.is_in and Check.in_range. You can define your own Check by passing a lambda with boolean return type - see the Number of views last 7 days example above (which could have also been accomplished with the built-in Check.in_range). You can also define your own extension methods so that they appear in the Check namespace.
You can validate your data against tests by simply passing your DataFrame to the validate method on the DataFrameSchema object.
validated_df = schema.validate(boat_sales_df)
Schema inference
Pandera schemas can be written from scratch using Python, as shown above, however you can see how that would become quite tedious and time consuming. To help with this, Pandera provides an infer_schema function that scans your data and generates a DataFrameSchema with some basic checks; this is intended to provide a starting point for you to tailor and further develop.
You can use the infer_schema function, then the to_script() method on the resulting DataFrameSchema, which converts it to a Python script.
inferred_schema = pa.infer_schema(boat_sales).to_script()
print(inferred_schema)

Here's the schema Pandera generated:
schema = DataFrameSchema(
columns={
"Id": Column(
dtype="int64",
checks=[
Check.greater_than_or_equal_to(min_value=0.0),
Check.less_than_or_equal_to(max_value=9887.0),
],
nullable=False,
unique=False,
coerce=False,
required=True,
regex=False,
description=None,
title=None,
),
"Price": Column(
dtype="int64",
checks=[
Check.greater_than_or_equal_to(min_value=3300.0),
Check.less_than_or_equal_to(max_value=31000000.0),
],
nullable=False,
unique=False,
coerce=False,
required=True,
regex=False,
description=None,
title=None,
),
"Currency": Column(
dtype="object",
checks=None,
nullable=False,
unique=False,
coerce=False,
required=True,
regex=False,
description=None,
title=None,
),
"Boat Type": Column(
dtype="object",
checks=None,
nullable=False,
unique=False,
coerce=False,
required=True,
regex=False,
description=None,
title=None,
),
"Year Built": Column(
dtype="int64",
checks=[
Check.greater_than_or_equal_to(min_value=0.0),
Check.less_than_or_equal_to(max_value=2021.0),
],
nullable=False,
unique=False,
coerce=False,
required=True,
regex=False,
description=None,
title=None,
),
"Length": Column(
dtype="float64",
checks=[
Check.greater_than_or_equal_to(min_value=1.04),
Check.less_than_or_equal_to(max_value=100.0),
],
nullable=True,
unique=False,
coerce=False,
required=True,
regex=False,
description=None,
title=None,
),
"Number of views last 7 days": Column(
dtype="int64",
checks=[
Check.greater_than_or_equal_to(min_value=13.0),
Check.less_than_or_equal_to(max_value=3263.0),
],
nullable=False,
unique=False,
coerce=False,
required=True,
regex=False,
description=None,
title=None,
),
},
checks=None,
index=Index(
dtype="int64",
checks=[
Check.greater_than_or_equal_to(min_value=0.0),
Check.less_than_or_equal_to(max_value=9887.0),
],
nullable=False,
coerce=False,
name=None,
description=None,
title=None,
),
dtype=None,
coerce=True,
strict=False,
name=None,
ordered=False,
unique=None,
report_duplicates="all",
unique_column_names=False,
title=None,
description=None,
)
Using Pandera to identify data issues
I've copied the autogenerated schema script shown above and placed it in its own Python file (boat_sales_schema.py) within a folder (schemas). Now I'm going to import the schema into a Jupyter Notebook and see how we can use it to better identify issues in our data.
If you use the default DataFrameSchema.validate method, you may get a very long error message from which it can be quite difficult to ascertain an understanding of the underlying issue. This is especially true if you're working in notebooks where a cell's output size is limited, causing the error message to be truncated. Also, the default behaviour of validate is eager, meaning the validation will be halted as soon as an issue is found, this way you don't get to see all the validation failures.
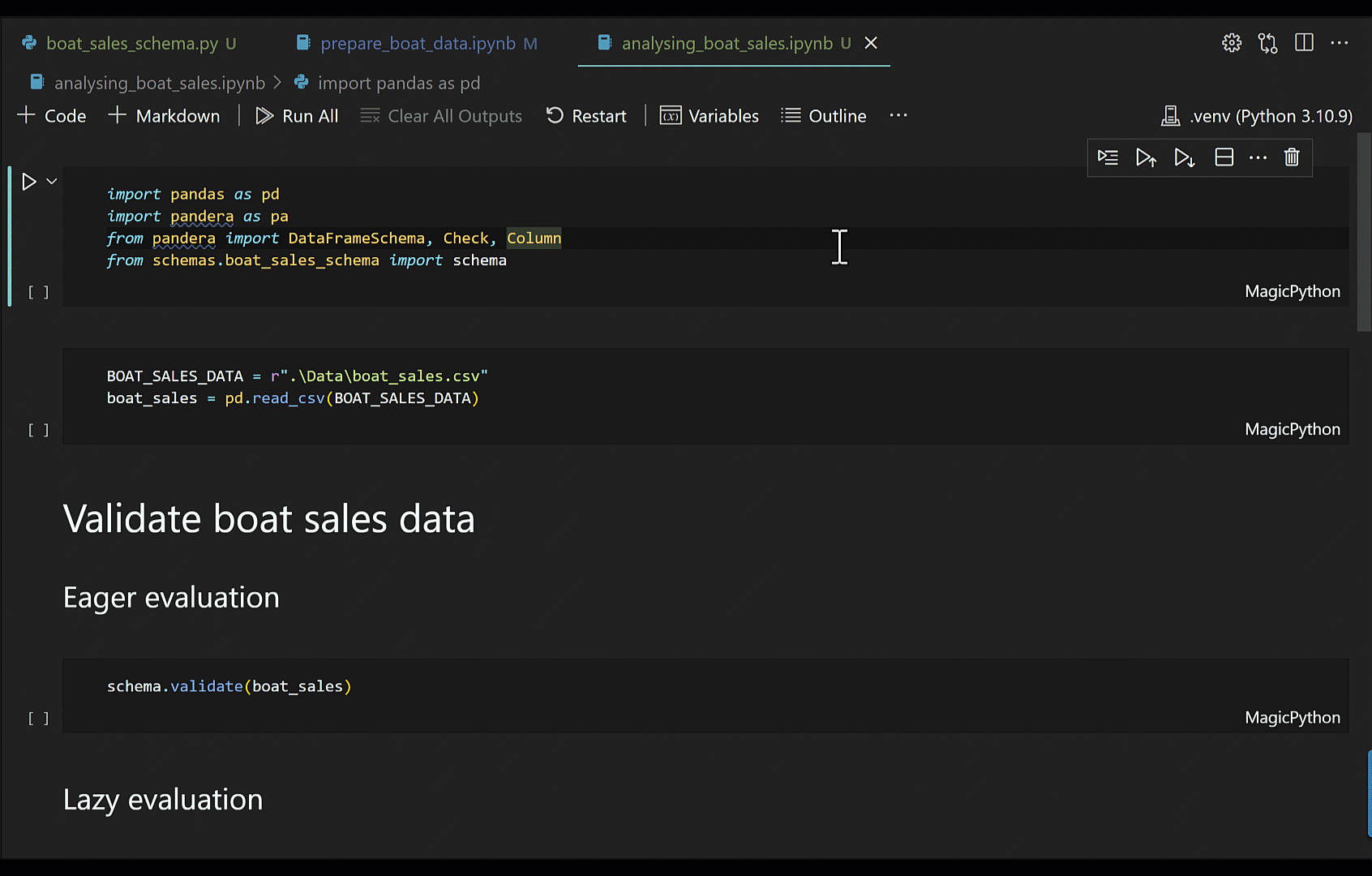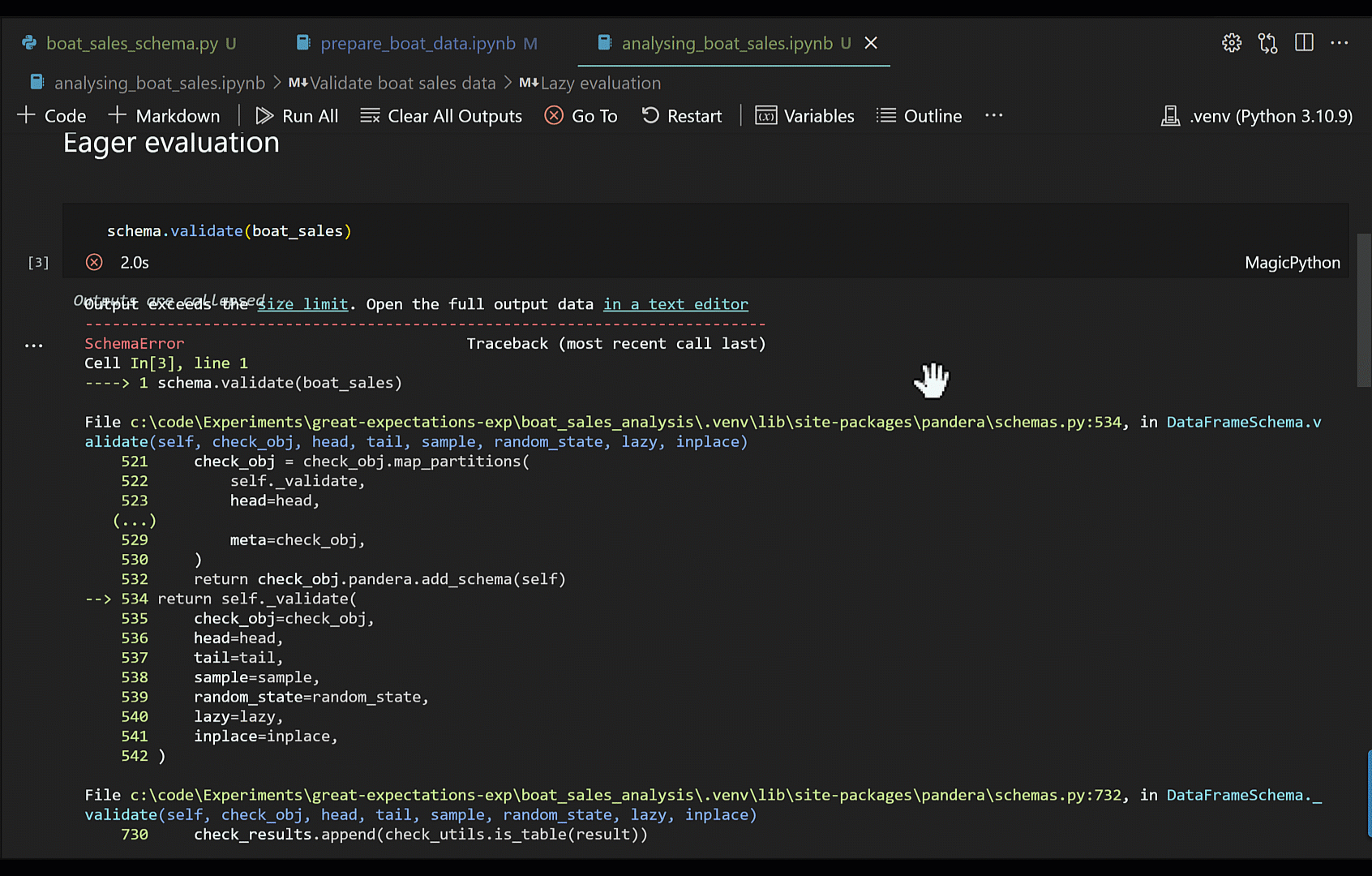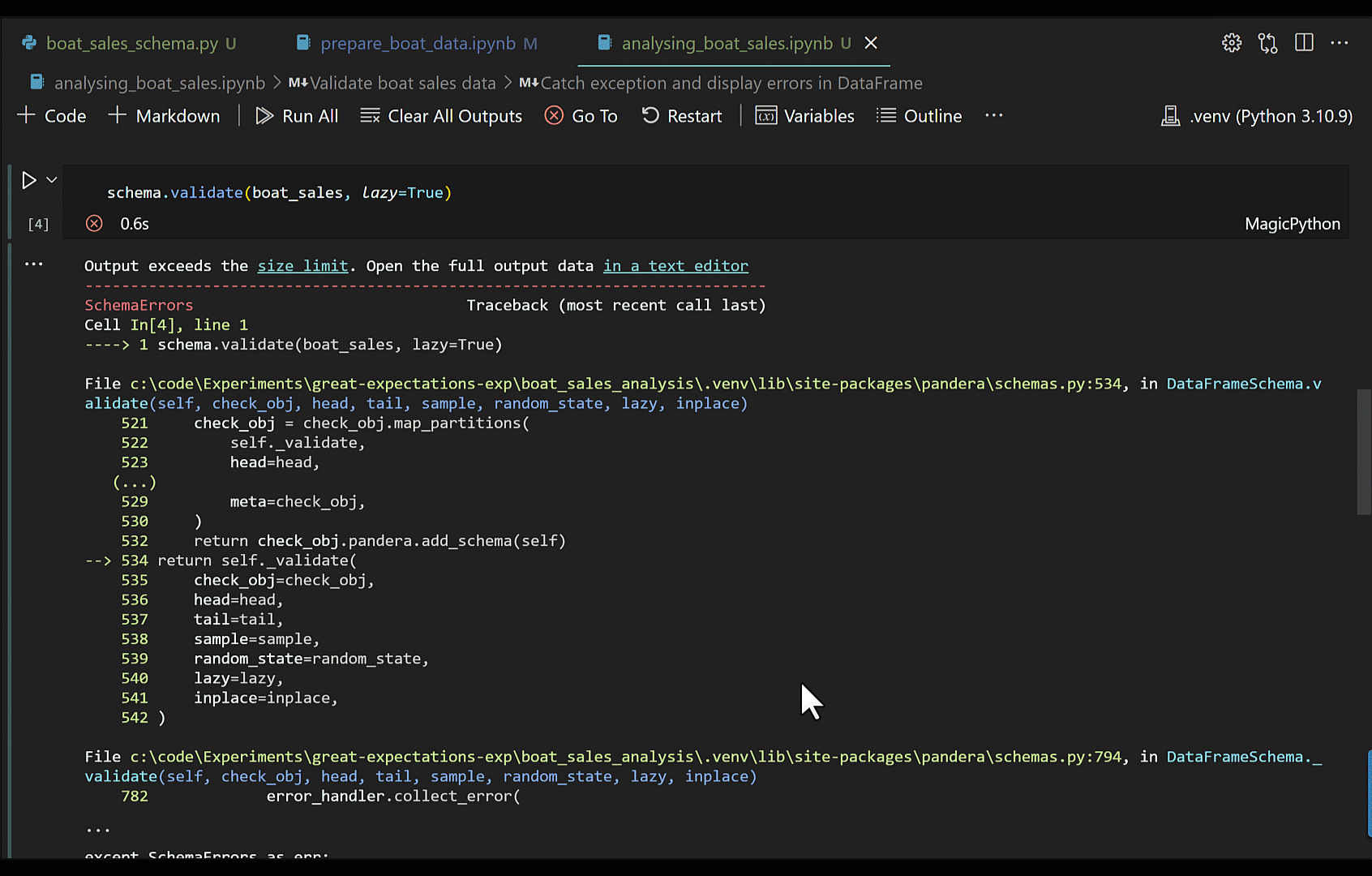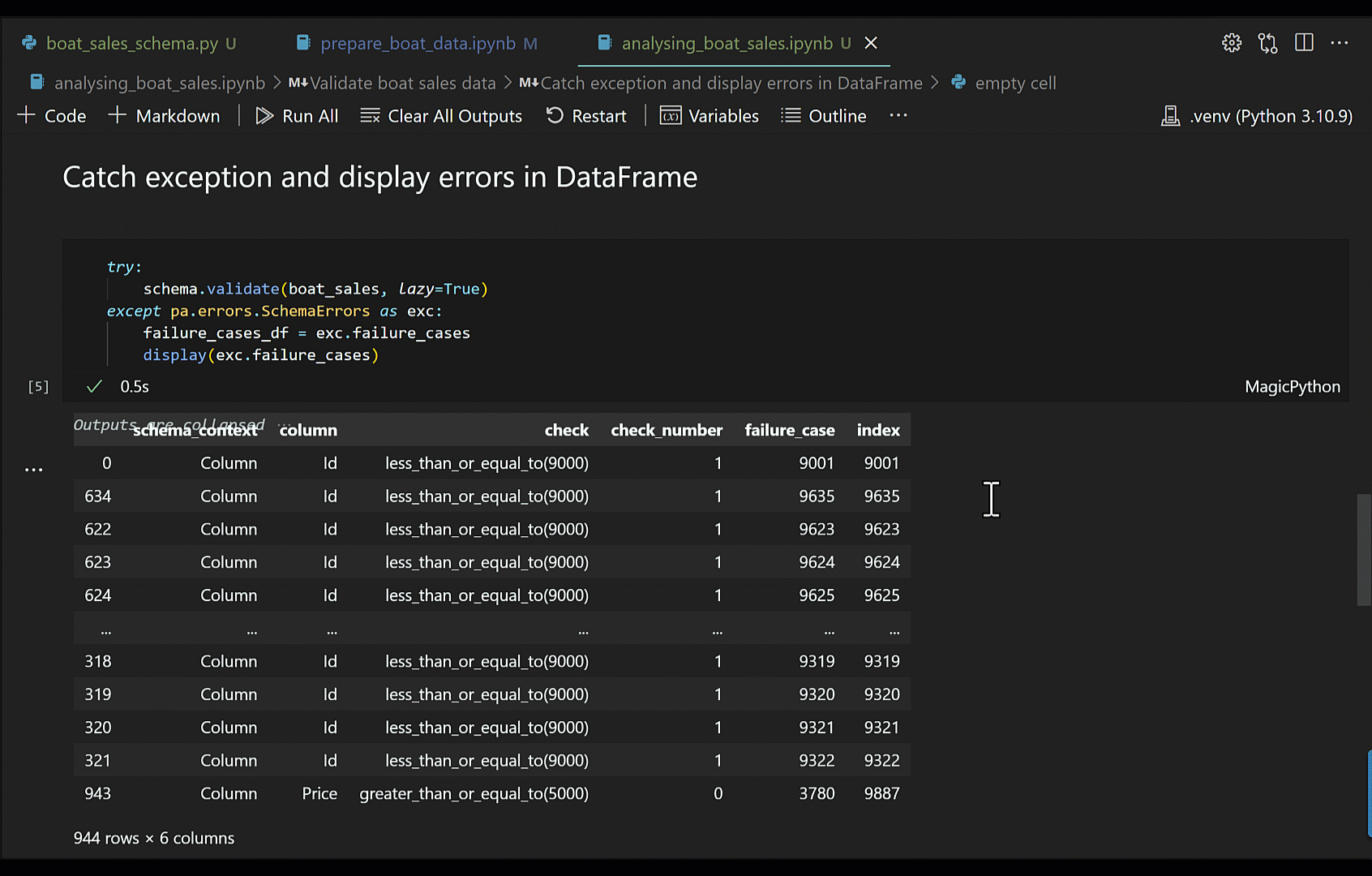
To work around this, I suggest you set lazy=True in validate, and use a try-except to catch any SchemaErrors exceptions; you can then pull out the failure cases from the exception into a DataFrame for better readability.
try:
schema.validate(boat_sales, lazy=True)
except pa.errors.SchemaErrors as exc:
failure_cases_df = exc.failure_cases
display(exc.failure_cases)
The GIF below shows the different approaches described in a Jupyter Notebook.
Pandera summary
In summary Pandera is a nice library, with great documentation, that provides a familiar, easy-to-use API for writing validation tests in Python. The learning curve is shallow, allowing you to become productive quickly; it didn't take me very long at all to download the package and get to a state where I had some basic tests to run against my data.
Great Expectations
From their official documentation:
Great Expectations is the leading tool for validating, documenting, and profiling your data to maintain quality and improve communication between teams
Great Expectations (GE) can also be downloaded from PyPI; I counted a total of 107 package installs when installing this into a fresh environment, which took some time; the package also comes with its own CLI. So, it's clear from the start that this is a pretty hefty package. The official documentation is great, and plentiful. A quick scan of the documentation reveals a whole host of terminology, definitions and concepts, as such, the package demands quite a bit of effort from the new user to get started.
First you need to create a Data Context, which is like a GE project inside your Python project that houses everything to do with data validation (configuration, validation results, etc). Next, you create a DataSource, which is like a reference from the data context to a dataset for use later on; the actual dataset can be a file on disk or a database connection (which is pretty neat) - I've just pointed it to local csv file. You're guided through this setup process via the CLI, after a number of multiple choice selections, GE will open a Jupyter notebook in the browser for further configuration of the Data Source. Running all cells in the notebook (i.e. following the default config) results in some YAML being added to the great_expectations.yml file, which is like the master configuration for the GE project.
Next, you need to create an Expectation Suite. An expectation is just a validation test (i.e.: a specific expectation of the data) and a suite is a collection of these. GE provides multiple paths for creating expectations suites; for getting started, they recommend using the Data Assistant (one of the options provided when creating an expectation via the CLI), which profiles your data and automatically generates validation tests. Once again, GE will launch a notebook in the browser for you to configure the Data Assistant - shown in the GIF below.

Upon running all cells, an expectation suite JSON file is generated, this file defines the expectations that GE generated for us. Running those notebook cells also caused a HTML file to be generated, this is what GE calls a Data Doc. A Data Doc contains the results from running an expectation suite against a batch of data, i.e.: it's a local web page showing the test results. In this case, the Data Doc has been generated by validating the Expectation Suite against the data batch that was used to automatically generate the suite, so we expect all tests to have passed.

Part of the generated Data Doc is shown in the GIF above. You can see that GE has generated some table-level expectations for us, as well as column-level ones. Let's take a look at some of these. For the Boat Type column we have: "values must never be null.", "values must always be greater than or equal to 6 and less than or equal to 42 characters long.", and "values must match this regular expression: [A-Za-z0-9\.,;:!?()\"'%\-]+.". The second of these is interesting; my immediate response was that this is useless - you wouldn't be interested in checking that the number of characters in the name of the boat type is within some range, however perhaps a name with 1 or 2 characters would be suspicious; I think in this case you would want to consult your stakeholder with the domain expertise, which may be necessary in many cases anyway. The generated regex doesn't offer much either, it will match against more-or-less any any sequence of characters; for example, it will match the string abc123DEF,.?!(). Moreover, I don't think it's necessary to check that the name of a boat type conforms to some pattern, again though, this may be one for the domain expert.
For the Currency column we have: "values must belong to this set: EUR CHF £ DKK.", which is one of the tests that I suggested at the beginning of the post, so that's good. We also have: "fraction of unique values must be exactly 0.0006743088334457181.", that's plain wrong - it's not valid to expect the fraction of boat sales that use a given currency to be exactly equal to some value.
So, although we can see GE has generated plenty of expectations for us, many of them don't make much sense or are overly stringent for this data. I think that's fine, though. The point of the data assistant (or schema inference in the case of Pandera) is to generate a suite for you to refine and develop; it removes the need to write lots of boiler plate and provides a platform for you to build on. I'd rather have too many generated expectations than too few, since it's easier and quicker to edit and delete than it is to write new ones.

So, at this point, we'd like to go in and edit and delete some of those expectations. There's a couple of ways you can do this:
- You can edit the JSON definition of the expectations directly (below is the JSON object representing the "values should not be null" expectation on the
Boat Typecolumn, to give you an idea of what they look like)
{
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {
"column": "Boat Type"
},
"meta": {
"profiler_details": {
"metric_configuration": {
"domain_kwargs": {
"column": "Boat Type"
},
"metric_name": "column_values.nonnull.unexpected_count",
"metric_value_kwargs": null
},
"num_batches": 1
}
}
}
- You can edit the expectations interactively with a batch of data.
(You can also create the expectation suite in the first place using these two methods.)
The second option is what's recommended in the docs. By 'interactively', they mean that you can edit some python code in a notebook, run it against a batch of data, and see the result. Let's see what that looks like.
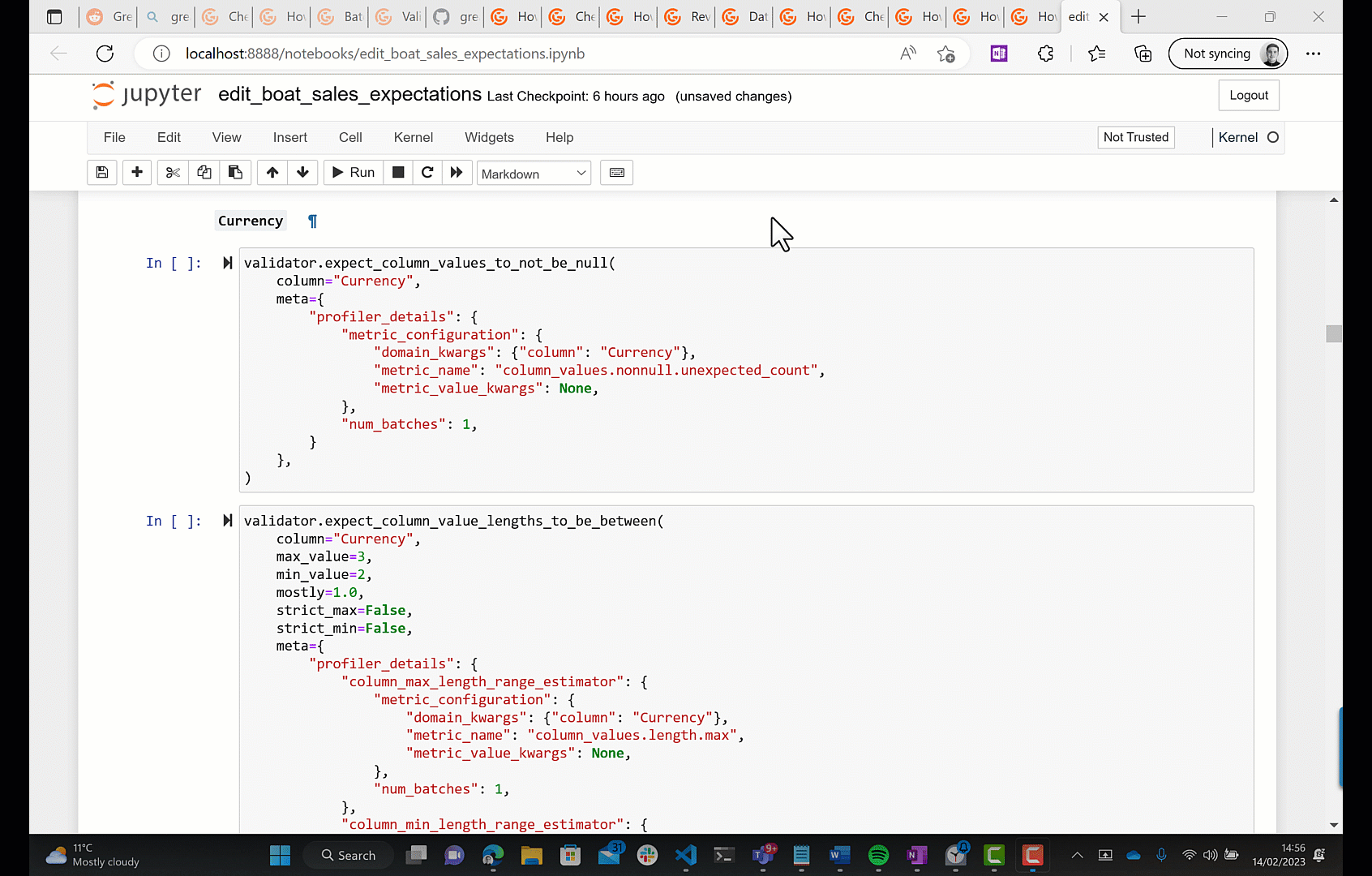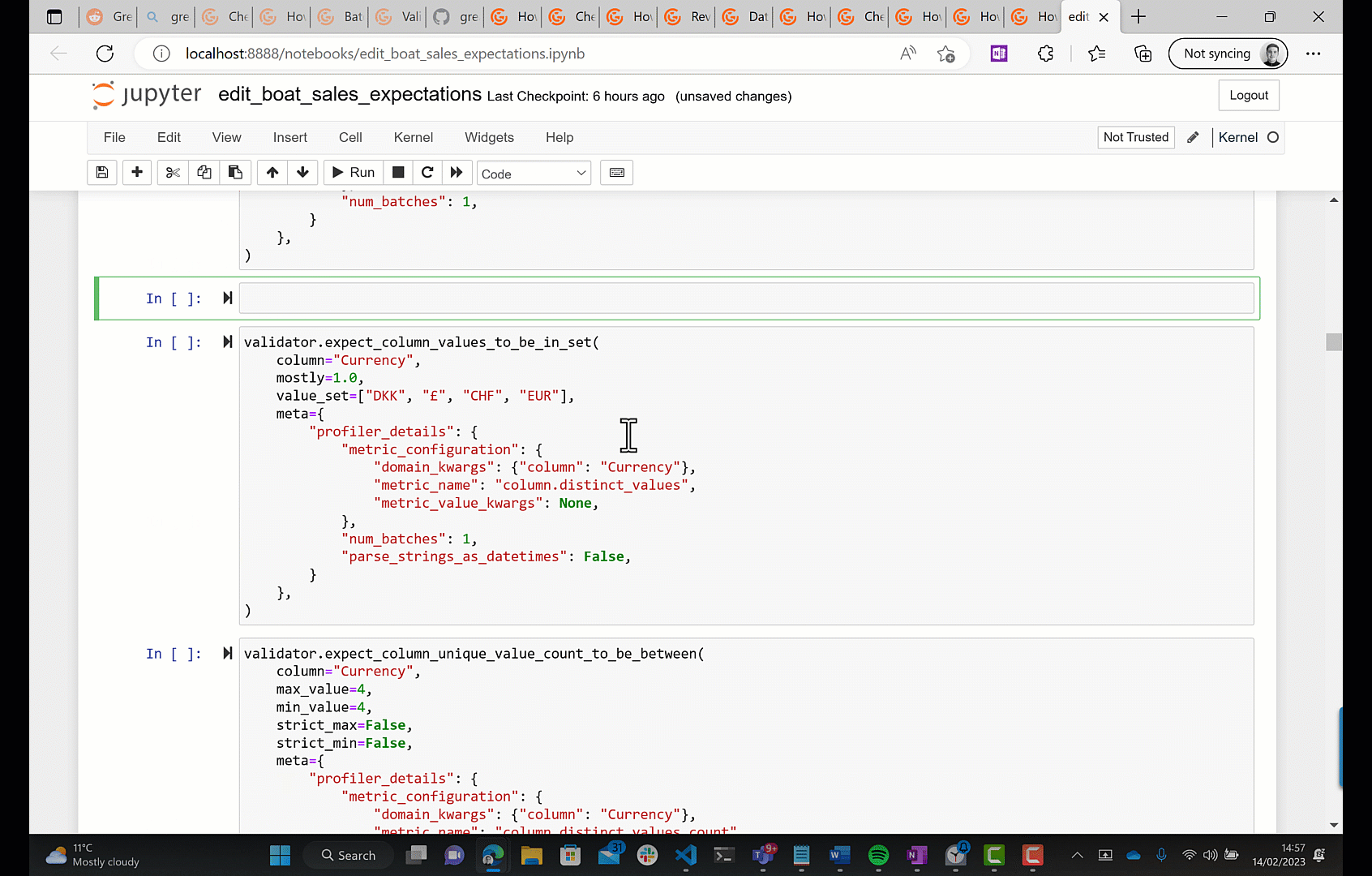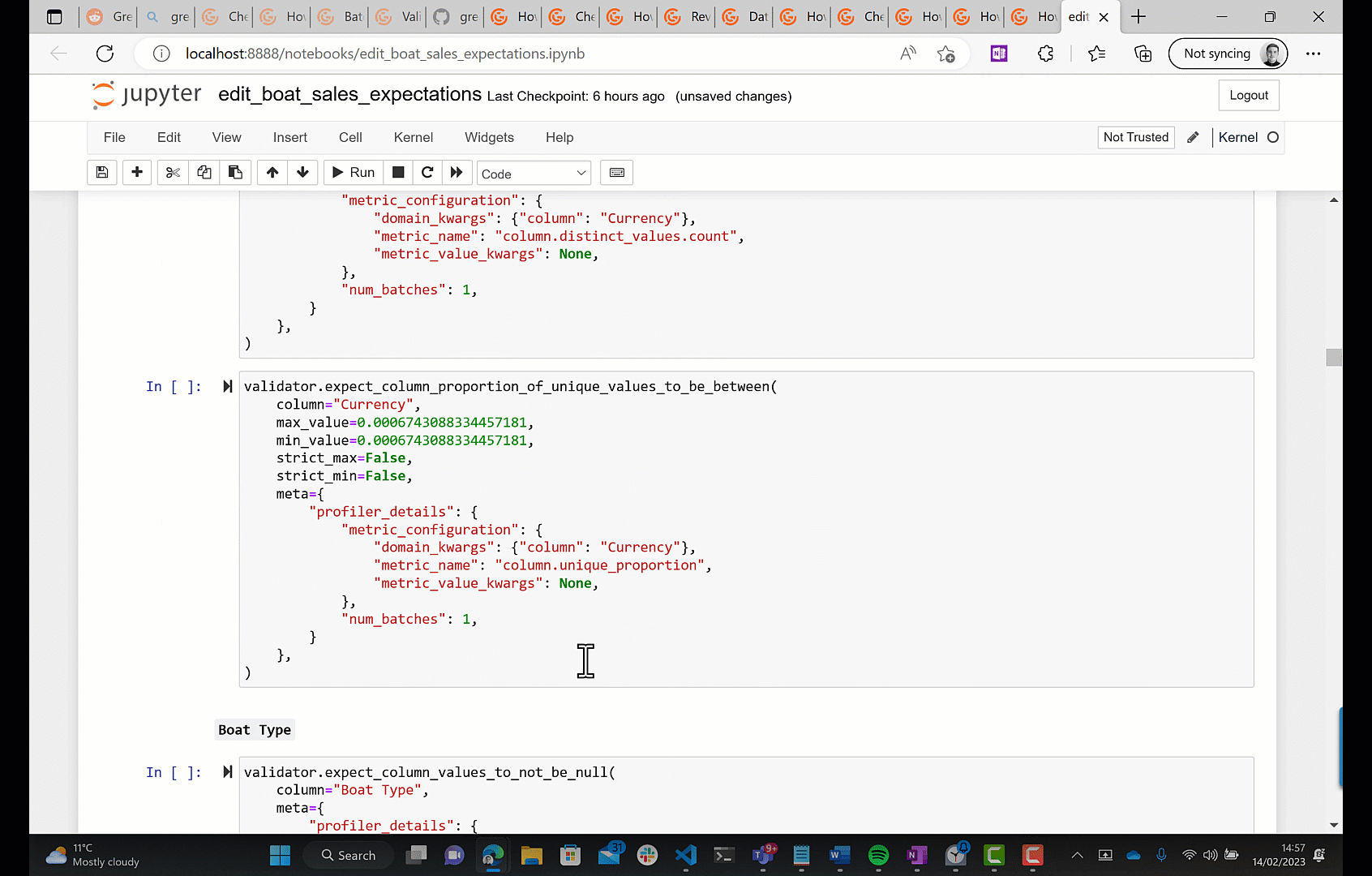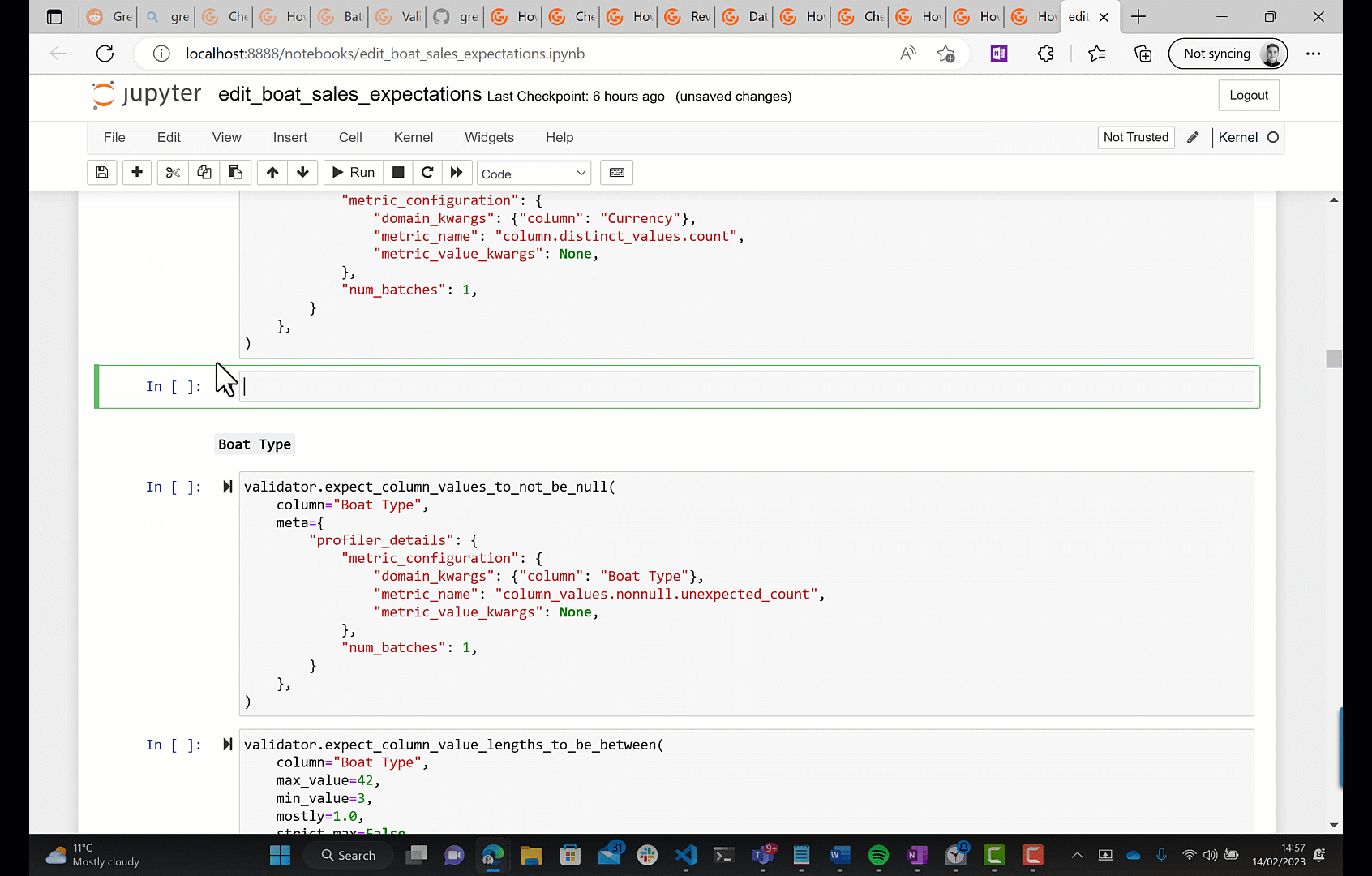
Now we've got our desired expectation suite, let's use it to validate a new batch of data; this is simulating the situation where you've got a new data drop incoming that you need to validate. To do this we need to create what GE call a Checkpoint; a Checkpoint associates an expectation suite with a batch of data, you can then run the Checkpoint any number of times in the future to validate the batch of data against the Expectation Suite. Again, by default, GE will launch a Jupyter notebook for you to configure a checkpoint.

You can see in the GIF shown above that I'm creating a Checkpoint using the Expectation Suite created earlier and with boat_sales_new.csv as the batch. Towards the end of the GIF, you can see a new tab in the browser being opened, this is showing the results of running the checkpoint.

A number of the expectations have failed on this new batch of data. At this point (assuming we're happy with the expectations), we'd starting cleaning the data to get those expectations to pass.
Going further with Great Expectations
The example I've demonstrated here is quite basic, and makes GE feel a bit overkill. Although it may seem cumbersome, many of the concepts and features of GE are much richer than what the example demonstrates, and I think GE will begin to shine when you want to do data validation in a more complex, real-world, production context. I'm not going to get into that in detail here, but the documentation is great; you can find lots of how-tos for configuring GE in more sophisticated ways and integrating it with other data tools, including cloud-based ones.
Take the Checkpoint concept. The example I've shown uses the SimpleCheckpoint (the default), which points at a specific csv and has some default configuration, like what post validation actions to take; with that configuration, I'd have to create a new Checkpoint if I wanted to run my expectations suite against a new file. But, you can configure a Checkpoint so that it receives a Batch Request at runtime; a Batch Request is like a query which you pass to your Data Source, which then produces a Batch of data. I'm envisioning scenarios where you'd want to integrate GE with your ETL/ELT process, and it seems like this type of functionality would come in very handy.
Great Expectations summary
Great Expectations is a heavy-weight package with a design that is clearly focused around integration and building production-ready validation systems. It introduces some of its own terminology and concepts, and feels opinionated in how it's helping you do validation. Whilst it's not quick and easy to get up and running, and even though I was frustrated multiple times throughout the process, I suspect all these things will be beneficial when developing in a more complex production setting.
Pandera vs Great Expectations
The key aspect that captures the differences between the two tools is that GE's design seems to have been strongly guided by the idea of building production-ready validation systems that integrate with other data tools, and can form part of a larger automated system. Therefore, naturally, the tool and API has to be larger and more complex to handle that additional complexity. This is reflected in the number of package dependencies: 107 for Great Expectations; 12 for Pandera.
On the other hand, Pandera seems to have been designed primarily with data scientists in mind, who are typically less concerned with production systems and engineering. Consequently, the tool is much more simple and concise, and I expect that building with Pandera in a production setting and integrating it with other data tools would require more effort. How much more? I don't know. That being said, Pandera does offer integrations with FastAPI; also, you may want to build your own validation system from the "lower level" components that Pandera offers.
| Consideration | Pandera | Great Expectations |
|---|---|---|
| Learning curve | Shallow - provides a familiar Pandas-like API | Relatively steep - introduces its own concepts and terminology. There are many moving parts |
| Documentation | Excellent | Excellent |
| Writing validation tests quickly from scratch | Very good fit. Simple and familiar Python API makes this easy. Python code becomes definition of the tests. | Not a great fit. You're not guided in this direction by the library. The Python API is less concise, and the Python code ultimately gets converted to JSON, which becomes the definition of the expectations. |
| Ability to profile data and autogenerate tests | Yes. | Yes, and generates a more comprehensive set of tests. |
| Integration with other tools and services | Features and documentation are relatively light on this front, suggesting the library is not well suited to this requirement | It's clear that integration has been a major consideration in the design of this library. |
| Building a comprehensive validation system in a complex domain | Again, features and documentation are relatively light on this front, indicating that this library isn't well suited to this requirement, or at least that fulfilling it would require considerable work. | It's clear that this library has been designed for the purpose of building comprehensive validation systems that can handle the complexities of the data space. The library implicitly states strong opinions on how to perform data validation, which I think act as guard rails for doing so. |
So, which one should you choose?
It depends. Given what I've said above, roughly speaking, if you want to get started writing basic tests quickly or want lower level control over you validation system, then choose Pandera. On the other hand, if you know you need to build a comprehensive validation system that needs to integrate with other tools and want sound help doing so, then Great Expectations is probably the way to go.



