Pass null values to SpecFlow scenarios via step argument transforms


I've always found getting csv files into a SQL Server instance much more convoluted than seems necessary.
The manual tools provided in SSMS have caused me hours of pain in the past, trying to match-up data types from source and sink. I never seemed to get it right. Is that just me?
Sometimes it's worth spending the extra time setting up an Azure Data Factory (ADF) copy activity to do this for you, especially if your end goal is for your whole data pipeline process to be automated.
ADF is Azure's job orchestration service, where one builds data "pipelines" which are a sequence of "activities", where "activities" can be, for example, copying a dataset from one location to another, transforming a dataset using U-SQL/Spark, or an activity which controls the flow of datasets within your pipeline. Whilst setting up an ADF pipeline may effectively ask you to do the same things that the SSMS wizards do (especially around specifying source types and sink types), I find the whole experience much kinder.

The problem is (no matter what tool you use to insert your data), very rarely can you be 100% sure that your column data types for your table in SQL Server will always be correct for the data you're trying to insert. This is especially the case if you're receiving the datasets upstream from some third party.
For example, we may have a column in the database defined as a varchar(3). If we try to insert the string "endjin" into this column, it wouldn't work. The ADF pipeline would fail, and the full dataset would not have been inserted into the database. Whoever relies on this dataset would then be affected, causing carnage in the workplace.
We have created a solution (using a custom USQL processor) whereby values in the csv datasets are checked against the column data type into which they will eventually try to be inserted. This, of course, occurs before the copy activity is attempted. If a value is seen to be invalid, it is routed to a separate table which holds all the erroneous values. A pretty nifty solution, and with every nifty solution should come some good tests. (Note: the actual solution isn't the subject of this blog.)
Enter SpecFlow
We test lots of our code using SpecFlow - we find it an incredibly powerful and elegant tool to use. One of the nicest aspects of it is the ability to effectively run separate versions of the same test by specifying a table of placeholder values for a particular Scenario Outline. Since our use-case is getting csv data into a database, all of our data types are covered using intrinsic data types in .NET. We have one SpecFlow feature file for each type from the set {DateTime, Decimal, Double, Float, Int, Long, String}.
Good tests should validate behaviour across the board, testing as many edge cases as possible. One of our (not-so) edge cases, is passing a null value into our USQL processor for a given column. In fact, it's a common occurrence for us to receive null values for fields in our csvs, so it's essential that this has test coverage.
Here's what a scenario in our DoubleColumnValidator feature looks like:
The problem is, all values used in the scenario examples are treated as strings. So, we have "null" where we really want null. Likewise, where we have the value 1234.5678 as a string, we want that to be of type double.
Now, in the corresponding method to the "Given" step, I could pass the value in as a string, and convert it to a double where I'm assigning the value to the "DoubleValue" key in the ScenarioContext dictionary, like so:
This works, but doing this for each and every one of my data types would be a bit painful and make things unnecessarily messy. This is where step argument transformations come into play. Using these custom transformations allows me to write the above as:
So a little bit of magic has been applied to the string representation of my double value in the scenario outline and it has arrived in my method as a nullable double, allowing me to write much more appealing code. But how? I have added a Transforms class, which includes all of my custom step argument transforms. It looks like this:
Here's what happens: when a value is passed into one of the parameters in the "Given" statement, SpecFlow first checks whether there are any step argument transformations where: 1. the regex matches the value being passed in, and 2. the return type of the transformation matches the associated type being passed into the method.
If so, SpecFlow performs this step argument transformation, but not before checking whether this transformation itself is matched by any other transformations given the above constraints.
Let's take the simple case, where we're passing in the string "12.345". In our "Given" statement, this value is being passed in as a nullable double (double?). Do we have a transformation where the regex matches the string "12.345" and the method returns a nullable double? Sure. In fact, our ToNullableDouble transformation actually matches on any value (represented by the regex (.*)). Our value is then parsed into a double, which is sent back to our "Given" method and everyone's happy.
Let's now take the more interesting example where we're passing in the string value "null", which we know to represent a null object. We again match on the ToNullableDouble transformation. But now, when SpecFlow checks for any other transformations which apply, it matches on the second method, ToNull. Why? Well, because the value "null" matches the regex "null" and the ToNull method returns a string, which is what is being passed into the ToNullableDouble method.
So we enter the ToNull method, set the value as null, send this value back up to the ToNullableDouble method, cast the null of type string to a null of type double, and again send it back to the method implementing the "Given" statement.

So we're effectively chaining transformations together. This is very handy for when you want to apply blanket rules to values of an object of a particular type. Implementing the same for all of our other types is cookie-cutter work, and we can keep all of our transformations in the same file.
However...
During a recent conversation with Ian about this blog, I have learned of the wise words of Raymond Chen: "Don't use global state to manage a local problem." What we've implemented here is working on the basis that the string value "null" is never actually meant to be regarded as the string "null". For numeric/DateTime types, of course, this can never be the case anyway - the string "null" will not parse into any of these types. But in the case of string types, some daredevils out there might actually want to keep the string "null" as a string. How can we cater for this, whilst still offering our null string to null object conversion?
The quick and dirty solution would be to generate a random string of arbitrary length, to use as an alias for null. All we'd have to do is change the regex in the ToNull method to that random string and all would be well. This solution is far from ideal, though. It would make the tests that little bit messier, and for anyone using the code, it may not be obvious what this random set of characters was doing.
The more sensible solution would be to have the null string to null object conversion optional to the user. We can do this by adding a tag to our scenario outline examples, and using this tag in our transforms to decide which rules to apply.
Let's hold this thought for just a moment, though. Let's first rewrite the ToNullableDouble transform slightly, in line with the understanding that the string "null" never actually means the string "null" for numeric/DateTime types:
Now, if the ToNullableDouble method receives either a null object or a null string, it will interpret that as null. So this method is essentially performing the same work as the ToNull method currently performs.
Let's now suppose that we're implementing the tests for our StringColumnValidator. Just to recap (it's been a long time since the start of this blog!), these tests check whether the string defined in the C# type will successfully be inserted into a string column in SQL Server. Like the double value validator, we want to check what would happen if we tried to insert the value null into our database.
Unlike all of our other types, we don't need to perform a type conversion for our values in our string tests - they are already strings. However, we do still want to be able to change "null" to null. Well, that is already done in our ToNull method defined further above. However, this is still applying the blanket rule that "null" should always be interpreted as null. Time to un-hold our thought from earlier.
To make the "Null string automatic conversion" optional, we can add a tag somewhere in the feature file, which we will use to toggle the different behaviour. When this tag is applied, the code will honour the null string to null object conversion. When it isn't applied, it won't. I say "somewhere", because there are numerous valid places one can place a tag.
Placing a tag at the "Feature" level applies that tag throughout the feature file, i.e. for every scenario in the file. At the Scenario level, the tag gets applied to that specific Scenario. At the Scenario Outline level, the tag applies to all the sets examples in that Scenario Outline. The last level is the "Examples" level. In this case, since you can have more than one set of examples for a particular Scenario Outline, the tag is applied to a particular set of that outline's examples.
In my case, I'm pretty confident that "null" should be converted to null for all of my string validation tests. For this reason, I'm going to put the tag at the "Feature" level:
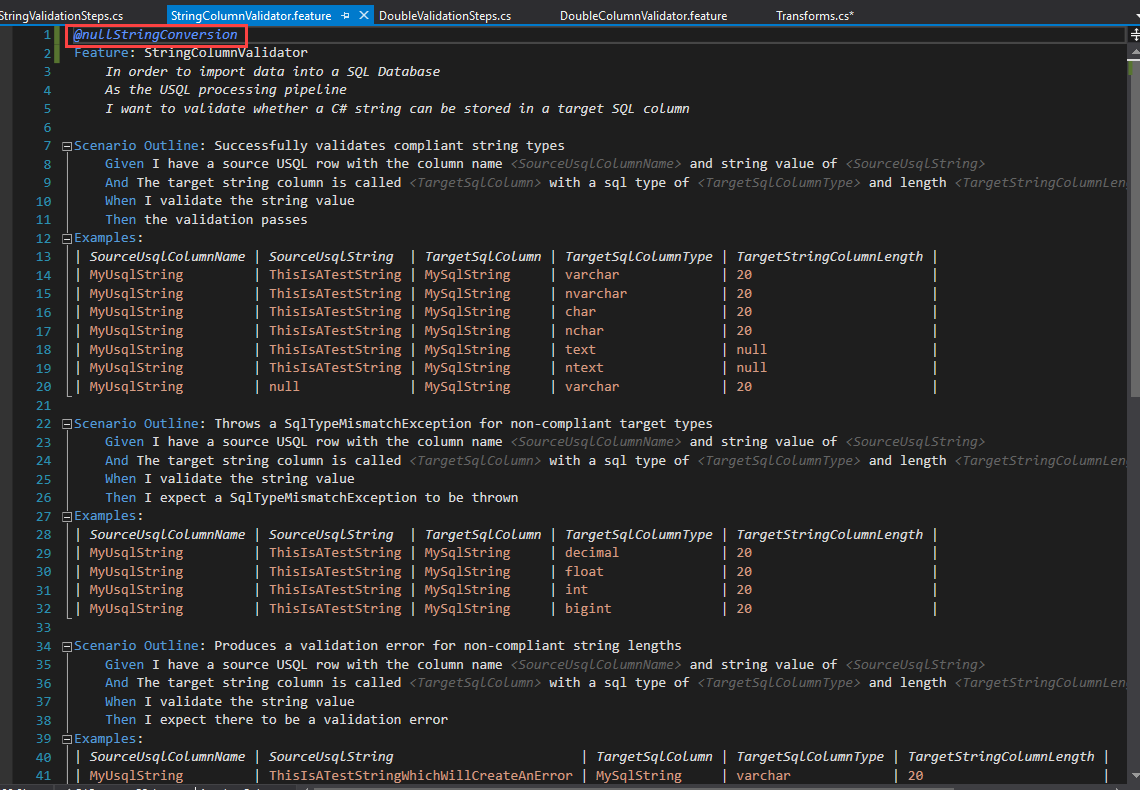
Now, all I have to do is inspect the FeatureContext.Current.FeatureInfo.Tags array in my Transform to check whether it contains the "nullStringConversion" tag, like this (I've also indicated how you'd access the tags array if you placed the tag at a different level in the feature file.):
Now, only when that tag is applied will the string null be converted to the object null, thus giving the user the option to apply this conversion.
In conclusion, we found this to be a nice way to abstract the messiness, and have a way of representing null in scenario outlines, which SpecFlow doesn't currently offer. We also learned how we can toggle this behaviour using tags. I hope you have found this blog useful!



