Machine Learning - the process is the science


As the interest in data science, predictive analytics and machine learning has grown in direct correlation to the amount of data that is now being captured by everyone from start ups to enterprise organisations, endjin have spent increasing amounts of time working with businesses who are looking for deeper and more valuable insights into their data.
As such, we've evolved a pragmatic approach to the machine learning process, based on a series of iterative experiments and relying on evidence-based decision making to answer the most important business questions.
This post digs into the detail behind the endjin process to explain why the "science" is really all about following the process, allowing you to iterate to insights quickly when there are no guarantees of success.
The process is the science
So what do machine learning and data science actually mean? My previous post argued that there's no mad science or dark art at play, just a pragmatic process based around trial and error with statistics. But to answer that question properly, it helps to break it down:
- The data is fairly explanatory - without it, none of this is possible and you're left with gut feel, instinct and hunches to base critical business decisions on
- The learning is the process of understanding the patterns in the data to develop and train a model
- The machine is the computer, software and tools used to do the high intensive processing that is required to train the model
- The science is the application of a process around all the above, as described in this post

Everything is an experiment
Anyone with a background in software engineering will be aware of the principles of agile and lean - iterative development cycles that enable teams to move fast, pivot fast or fail fast. We apply these with rigour to anything we do and help other organisations apply the same techniques to their own business processes.
Matthew has talked at great length about our New Product Development process and how breaking large strategic business goals down into small well-defined experiments with clear success criteria allows businesses to evaluate at every step of the way whether they're on the right track. The advantages of doing this are clear - when there's time, effort and money involved, being able to evaluate success regularly means being able to re-prioritise valuable resources accordingly.
The "best idea ever"™ that you were happy to throw an entire team behind last week may prove to be a waste of time pretty quickly, which is absolutely fine, as long as you have a process for recognising that just as quickly. And then doing something about it.
The same process can (and should) be applied to machine learning projects to the same great effect - especially as experimentation is already such a fundamental concept in machine learning to begin with. The truth is that there's no guarantees of success in machine learning projects - you may not be able to find a pattern in the data, or you may only find patterns that aren't strong enough for you to want to base business decisions around them. Because of this, any processes need to be experimental at their core, so it's possible to fail fast and move on.
The business objective
However, experimentation for experimentation's sake is nothing more than, well, experimentation. The mystique and nature of machine learning and data science is such that it is easy to fall into the trap of doing busy work - in this case, spending time on what is perceived by others to be complicated, scientific and a bit magical - meaning it must be important - when, in fact, it's not providing any real value to anyone or anything.
The key is aligning the data science work (and team) to the needs of the business, just like every other function. Data exploration, data preparation and model development should all be done in the context of answering a defined business question. In the same way that a business case and agreed set of requirements would be made before embarking on developing a new web application, data science work and machine learning experiments should be performed in line with a clear set of objectives that tie back to an overall strategy or business goal.
Start with a hypothesis
Once the business objective is understood, in order to run an experiment, the parameters need to be defined. This means stating what it is you're trying to prove and, most importantly, what success looks like. Defining the success criteria before you start the experiment is critical to keeping decisions to continue or change direction in line with the business goals. The best way to do this is to define a testable hypothesis.
The Texas Sharpshooter Fallacy

By formulating the hypothesis after data have already been gathered and examined, you're at risk of committing the Texas sharpshooter fallacy - when false conclusions are inferred by focusing on the similarities in data rather than the differences, or to put it another way, interpreting patterns when none exist.
Instead of painting on the target after you've fired the shots, define the success criteria first - only then can you truly avoid bias in your analysis of the results and be sure that your decisions are backed by evidence and not a pre-existing expectations.
For example, a hypothesis may look like:
"It is possible to predict a fraudulent credit card transaction with an accuracy of 90% based on the metadata associated with the transaction."
Writing the hypothesis forces you to think about the use case of the experiment you're performing. It also ties it back to real business value - in the example above it's clear to see that proving this hypothesis could lead to a number of strategic business decisions. Armed with an 90% confidence of risk, workflows around transaction processing can be designed accordingly.
Once the experiment has been defined, the machine learning process can be executed within meaningful boundaries.
It's all about the data
The most important activity in the machine learning process is choosing and preparing the data. The data holds the secrets. So, the more of it you have, and the better quality it is, the better the results will be.
Deciding which data is most relevant to prove (or disprove) your hypothesis generally requires domain expertise - whilst an experiment is essentially a trail and error exercise, having a solid, sensible starting point is clearly a good thing.

Once the data has been identified and obtained, it then needs to be prepared for use in the machine learning algorithms. This might mean deciding how to handle missing values, duplicate values, outlying values or values that have direct correlations to others (e.g. a crime rate could be inferred from a post code so are both indicators required?). Different data sets may need to be combined, including data from internal and external sources. Traditional ETL data processing to cleanse, transform and merge data is combined with statistical analysis to identify the most useful data attributes.
Model development
With prepared data, an appropriate algorithm can be applied to try to find a model that answers the questions you're asking. Selecting the best one to use depends on the size, quality and nature of your data, the type of question your asking and what you want to do with the answer. There are many well known algorithms that attempt to solve specific problems, which can be broken down into different categories, as described in my previous post.
An algorithm is typically "trained" on historical data - feeding in information about what we already know has happened so that it can learn the patterns and generate a model. The model can then be used to predict outcomes for new data in the future.
The model is evaluated against a different set of known data to score its accuracy. If the model performs well enough that it is deemed successful according to our hypothesis then (and only then) steps can be taken to deploy/productionize/integrate the model into other applications or business scenarios so that it's value can be realised.
Models will evolve over time - what's true in your data now may not be in a day, month or year's time. It's therefore important to build in a mechanism for re-training the model as part of then productionizing process so that it stays relevant and - most importantly still meets the success criteria that you defined.
Document everything
As with any science experiment, keeping detailed lab notes is really important. As there's no guarantees of success, being able to understand what you were going to do, why you chose to do it and what happened is really important in ensuring your experiments are both repeatable and not repeated unnecessarily. The best way to do this is to document as you go along (once again, document the whats and whys before you begin so as not to introduce bias after the fact).
Putting it all together
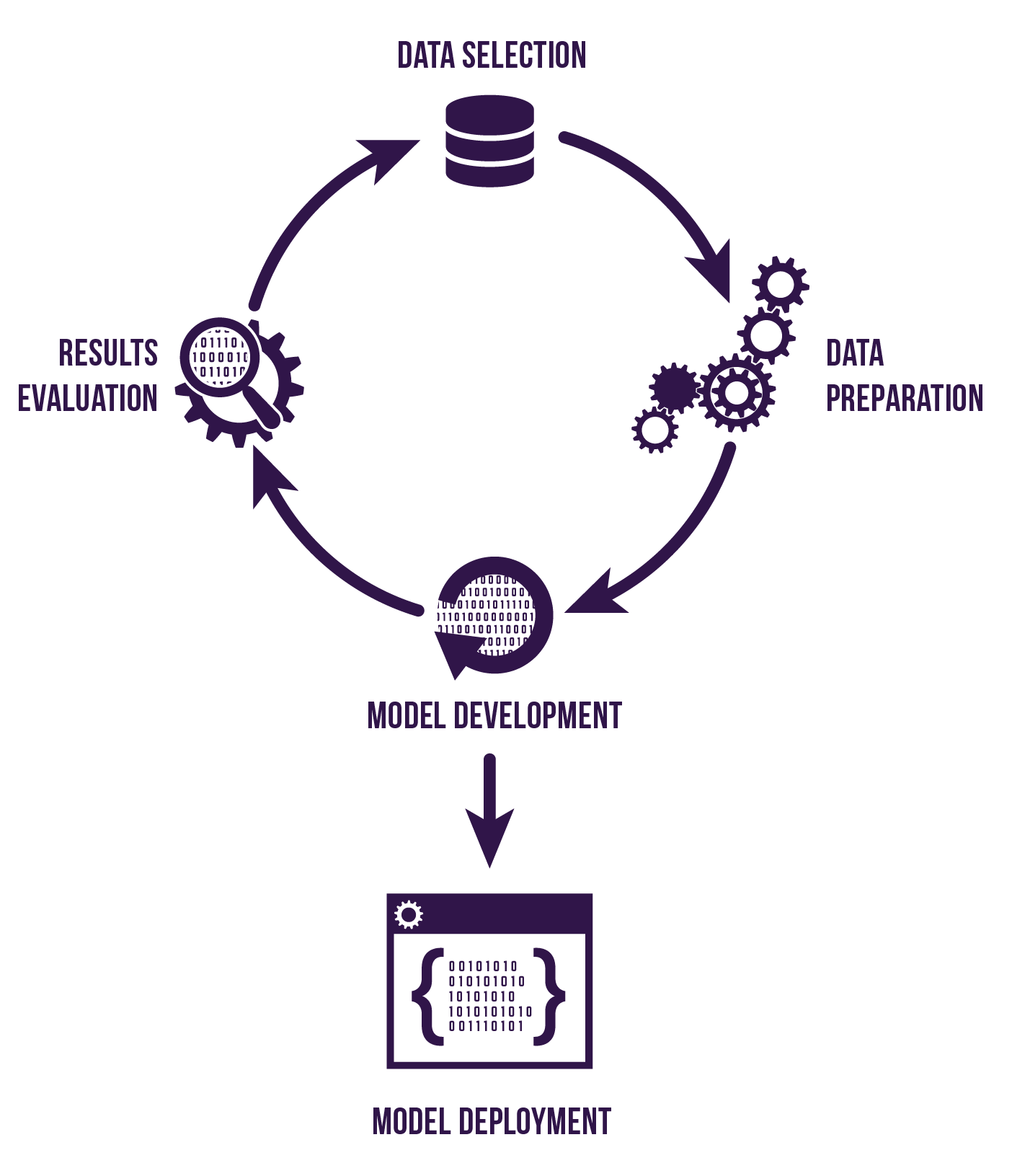
- Understand the business objective - be clear about what you're doing and why you're doing it
- Start with a hypothesis - define and state the parameters and the success criteria before you begin
- Time-box an experiment - decide how much time and effort you're willing to spend to prove or disprove your hypothesis
- Prepare the data - identify, source and prepare the data for use in the model
- Experiment with algorithms - select, train, evaluate and compare relevant algorithms for the type of problem
- Evaluate and iterate - use the evidence from the experiment to decide whether there's value in continuing
- Productionize - if you find a successful model, take necessary steps to realise the value across the organisation
The small print
To reiterate a final time, there's no guarantees of success in a machine learning experiment - there may be no meaningful pattern, or at least not one that meets your success criteria.
In this regard, this type of work is very different to typical software development or IT projects, as the outcomes are not known up front. Rather than committing to delivering a web application with a certain set of features, it more like committing to see whether it's possible to build a web application with a certain set of features. The difference is subtle, yet important, and reinforces why the emphasis should be on the process, rather than the result. The science is in the process.
Define the parameters and success criteria, execute the experiment, evaluate the results and move on. If the results weren't as you hoped or expected, then you've spent the minimum time and effort possible proving or disproving the hypothesis, which should be considered a success.
The other consideration is that executing a machine learning project isn't a one-off effort. In the same way that building a web application requires ongoing support and maintenance, so does a productionized model. As internal and external factors change over time, the patterns in the data will change too and consideration for re-training, re-evaluating and re-deploying the model should be applied accordingly.
At endjin, we execute machine learning and data science projects using the approach and process described here. We use tools such as Microsoft Azure Machine Learning Studio to quickly iterate over experiments, keep detailed lab notes and deploy effective models into production without friction.
We've put this into practice to answer difficult questions for our clients, some of which will be explained in a later post.
If you want to hear more about how we can apply the same approach for your business, please get in touch.