Machine Learning - mad science or a pragmatic process?


As the interest in data science, predictive analytics and machine learning has grown in direct correlation to the amount of data that is now being captured by everyone from start ups to enterprise organisations, endjin are spending increasing amounts of time working with businesses who are looking for deeper and more valuable insights into their data.
As such, we've adopted a pragmatic approach to the machine learning process, based on a series of iterative experiments and relying on evidence-based decision making to answer the most important business questions.
This post looks at what machine learning really is (and isn't), dispelling some of the myths and hype. My next post digs into more detail about the endjin approach to structured experimentation, arguing that the science is really all about the process.
Mad science, magic, or a pragmatic process?
It's no exaggeration to say that the hype around machine learning has gone a bit crazy recently. Since the explosion of Big Data, the need to make sense of masses of digital information has not surprisingly increased, causing a wave of excitement around a new era of data science.
In the progression from descriptive to predictive and prescriptive analytics, machine learning remains the cutting edge of data science, still holding some kind of mystique - especially to those who don't know their neural networks from their decision forests. Connotations of Mad Scientists, and Wizards are still rife, as if there's some kind of dark art or magic at play, a perspective seemingly perpetuated by the industry itself.
The reality is that machine learning, as a discipline, is really just a lot of trial and error – proving or disproving statistical scenarios through experimentation – without any hard guarantees of success. As such, we've turned to the standard process used in research labs the world over, and applied it to these business applications, relying on evidence-based decision making, tied back to well defined business objectives. But more on that later...

What's it all about?
To put it simply, think of machine learning as using statistics over big data to detect patterns. When the data is both long (i.e. lots of rows) and wide (i.e. lots of columns) it becomes increasingly difficult to see those patterns. Machine learning tools use compute power to do this, and once a pattern is found, it can then be used to make predictions for new data.
An Example
 Given a data set of one million historical credit card transactions that includes all manner of information about the transaction, e.g. the date and time, the amount, the location, the card balance, the product purchased etc. and, most importantly, whether the transaction was deemed fraudulent or genuine, a machine learning algorithm can calculate which pieces of that information are the most statistically significant in relation to whether the transaction was actually fraudulent.
Given a data set of one million historical credit card transactions that includes all manner of information about the transaction, e.g. the date and time, the amount, the location, the card balance, the product purchased etc. and, most importantly, whether the transaction was deemed fraudulent or genuine, a machine learning algorithm can calculate which pieces of that information are the most statistically significant in relation to whether the transaction was actually fraudulent.
It can find the pattern in the data that is too difficult to determine manually – the particular combination of parameters and ranges or categories of values that are more likely to lead to a fraudulent transaction outcome. This is the model.
Once we have a model, we can use it to predict whether a future transaction is likely to be fraudulent by passing through the same information parameters that we know about a new transaction.
The machine learns the model based on statistical analysis of existing data which can then be used to predict outcomes for new data
However, it's important to note a few things – firstly, a model is never going to be 100% accurate. There'll be a degree of confidence applied to it's accuracy which may or may not be high enough for a business to act on. e.g. if we can only predict whether a transaction is going to be fraudulent with 52% confidence, that's not much better than a random 50/50 decision and you probably wouldn't want to base any business process around it.
What it really tells us in this case is that a pattern can't be found in the data – either we don't have the right data in the first place, there's not enough of it, or the quality of the data is low. Or maybe there just simply isn't a pattern to be found - it's important to keep this in mind - there's never a guarantee of success in any machine learning experiment.
Secondly, machine learning isn't focused on explaining the underlying reasons behind the model. The key thing is being able to make a prediction, not explain the ins and outs. Some algorithms will give you an idea of the influential factors – i.e. the parameters that it deems important in the prediction, but it's less likely that you'll be able to understand the specific weightings or combinations of values that lead to the prediction.
This may or may not be a problem for you, depending on what you want to do with the model. But it does highlight the need to recognise that a model is a living and evolving thing – and what works now may become less accurate over time as data changes.
A model is a living and evolving thing
Because it's hard to define or explain the inner workings of the model, periodic or iterative validation – called retraining – over current data should be performed to maintain accuracy and ensure that confidence levels are still high enough to justify the associated business actions.
The machine
The "machine" bit of machine learning means using computers and software to do the necessary data processing. Running complicated algorithms over large amounts of data requires processing power beyond that of the average person. This could take many forms and there's a variety of languages, applications and platforms that are tailored to this kind of work.
The most widely used programming language for statistical computing and predictive analytics is R, which is integrated into many bigger data analysis frameworks. The Comprehensive R Archive Network is package repository containing pre-defined algorithms and utilities for us in R projects. Amazon, Google and Microsoft all offer cloud-based ML platforms (alongside a whole host of other specialist software and service offerings), which include functionality for connecting to, ingesting and processing data sources, provide libraries of pre-built algorithms and R language integration and enable visualisations and statistical analysis of results.
The right platform to choose is, as with any other software choice, down to a combination of many factors including feature set, price, previous experience etc.

The science bit
The "learning" bit of machine learning relates to algorithms being applied to the data to determine the patterns. There are many different types of algorithms and the best one to use depends on the size, quality and nature of your data, the type of question your asking and what you want to do with the answer.
There are many well known algorithms that attempt to solve specific problems, which are outside the scope of this article, but they can be broadly broken down into three categories:
Regression
Regression algorithms attempt to predict a value on a continuous scale (i.e. a number). For example, predicting future sales figures based on historical performance.
Classifying
Classifying algorithms attempt to group data into 2 or more pre-defined categories, for example, is a credit card transaction fraudulent or not.
Clustering
Clustering algorithms also attempt to group data, but without knowing how many groups there may be. In these scenarios, it's the groups themselves that are being defined as well as the members, for example, finding commonality in customer data to understand segmentation.
Supervised and Unsupervised learning
Whilst regression and classifying algorithms know what the results could be (and can therefore be tested for accuracy against historical data), clustering algorithms know neither how many clusters there will be, or what they are. In this regard, regression and classification are thought of as "supervised" learning - the algorithm is guided to the outcomes in the historical data (which are being used to "train" the model).
Clustering algorithms, on the other hand, have to form the categories of answer themselves without training data sets (referred to as "unsupervised" learning), meaning that the usefulness of those categories must be decided retrospectively by the data scientist and/or business stakeholders - often a subjective decision requiring relevant domain knowledge.
An Example
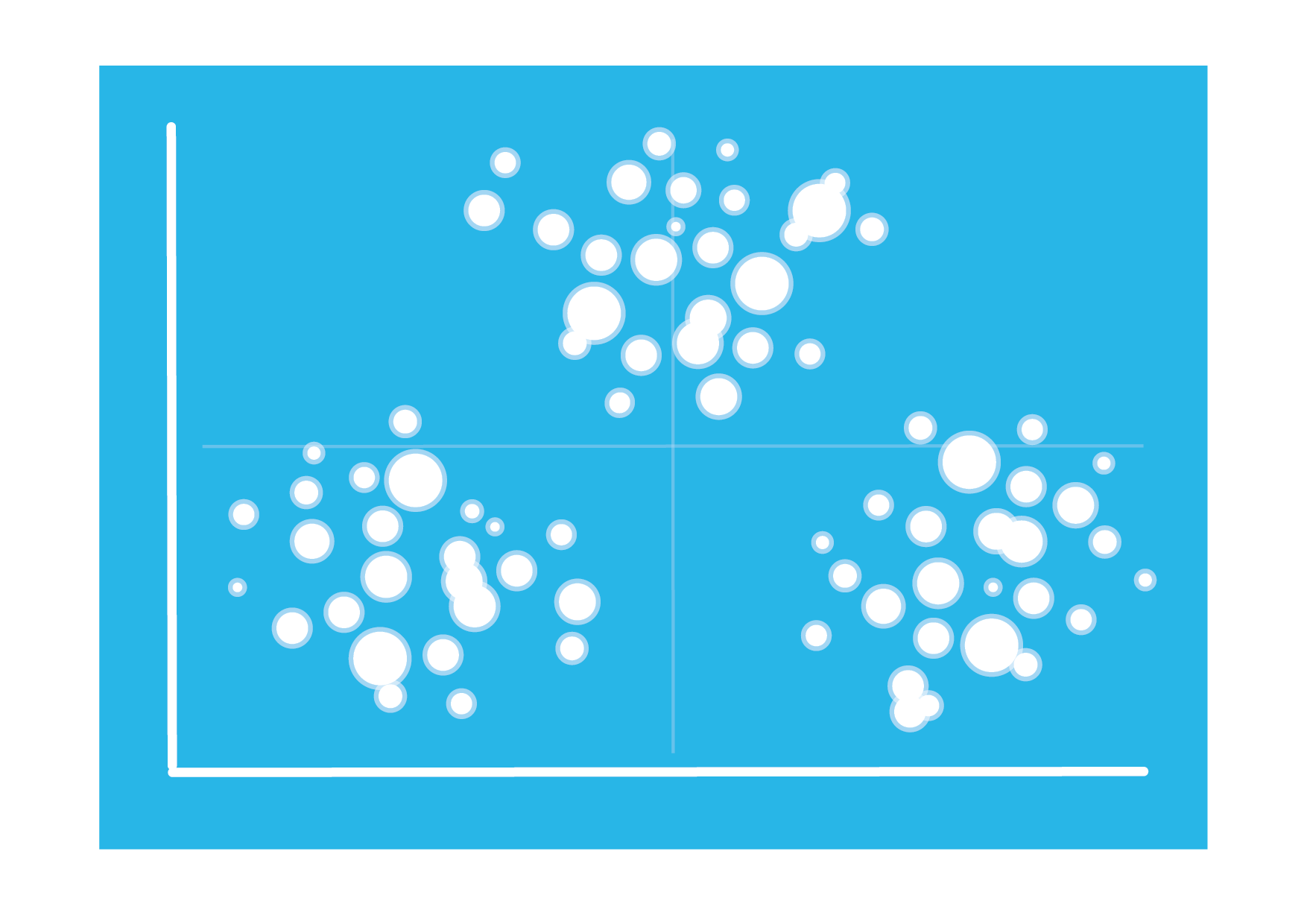 A classic application of cluster analysis is in determining segmentation profiles within customer data. For example, an e-commerce website will know a lot of information about a customer - from where they live, how much they spend, the type of products and brands they like, what devices they own and how, when and from where they visit the site etc.
A classic application of cluster analysis is in determining segmentation profiles within customer data. For example, an e-commerce website will know a lot of information about a customer - from where they live, how much they spend, the type of products and brands they like, what devices they own and how, when and from where they visit the site etc.
The goal of cluster analysis is to find data that are more similar to each other in comparison to others in the same group, based on a combination of variables, i.e. finding groups of customers that share the same characteristics.
When each customer belongs to a cluster, you can apply domain expertise to look for patterns in the data set to try to understand certain behaviour - e.g. based on the characteristics of a certain group of customers, why do they spend more on specific products, or convert on different offers? Once you begin to understand this behaviour, specific customer segments can be targeted in different ways to maximum effect.
Putting it all together
So, rather than Mad Science, the process of finding predictive models is essentially iterative trial and error with statistics – starting with raw data, processing the data so that it is in a usable and meaningful form to feed into an algorithm, running the algorithm, evaluating the results, and repeating until happy.
In typical endjin fashion, we aim to work smarter, not harder when conducting machine learning experiments. The approach that we follow will be described in detail in the next post in this series. We use tools such as Microsoft Azure Machine Learning Studio to quickly iterate over experiments, keep detailed lab notes and deploy effective models into production without friction.
We've put this into practice to answer difficult questions for our clients, some of which will be explained in a later post.
If you want to hear more about how we can apply the same approach for your business, please get in touch.


{kind=link}