Learning to Program - A Beginners Guide - Part Four - A Simple Model of a Computer


It's time for another block diagram.
Most modern digital computers are organized something like this:
We call this the Harvard Architecture. When we talk about architecture in computing, we mean a high-level view of the parts of a system, and how they relate to one another.
How does it work?
The Control Unit is, as its name implies, responsible for orchestrating what goes on.
It reads an instruction from the Program Instructions memory, and executes it. (It never writes anything back to the program instructions memory; that's why we've drawn the arrow going from the program instructions block to the control unit block.)

If there is some math or logic to be applied during the execution process, it will send the necessary information to the Arithmetic and Logic Unit (often known as the ALU - one of many acronyms which plague the computer industry), and get an answer back. Executing the instruction may involve reading something from the Data Memory; taking data from an external Input device (like a keyboard or a mouse); or writing something to an external Output device (like a display or a printer), or back into the Data Memory. (We read and write from data memory, hence the double-ended arrows.)
All these separate arrows on the diagram are quite important. They imply that there are separate means of reading from the program instruction memory, the data memory, and the input and output devices. This is an important optimization of earlier computer architectures (specifically the von Neumann architecture) where there was only a single channel of communication (called a bus - brace yourself, there's loads more jargon to come) between the control unit, the program instruction memory and the data memory.
Because, in general, the processor can read and execute program instructions far faster than it can move the information it needs to work on out of the data memory and into the control unit, pushing that all down a single pipe was (and still is!) very inefficient, with the processor stalled waiting for the next instruction to execute while data is read and written.
The idea of separate buses for data and instructions is one technique for overcoming this so-called von Neumann bottleneck, and is a key feature of the Harvard architecture.
So, once the control unit has finished executing one instruction, it moves on to the next, one after the other, in a well-ordered sequence, each instruction changing the state of the system (the values stored in memory, for example) as it goes.
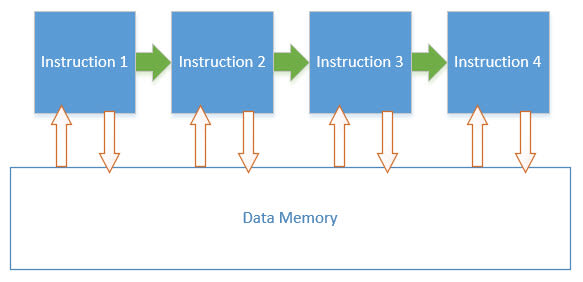
We call this step-by-step sequenced approach, where each step changes something about the state of the system imperative programming. It is so fundamental to our notion of how a digital computer works at this level, that it can sometimes seem that there is no other way of thinking about it.
We're going to start out looking at this imperative approach to learn a bit about how simple programs can be written, how we can represent information like numbers and text in a computer, and how we can apply logic for the purposes of decision making.
But one thing that will become apparent is that this imperative approach can get very complicated, very quickly. So, we'll move on to think about other, more declarative models, which help us to describe what we want the program to do, rather than tell it what to do.
As simple as possible but no simpler
For all that we've just used a lot of jargon, isn't this view of a processor a bit simplistic and diagrammatic? Well, yes, but it is not as artificial as you might think. Here's a (highly magnified) picture of an Intel Core i7-4770K.
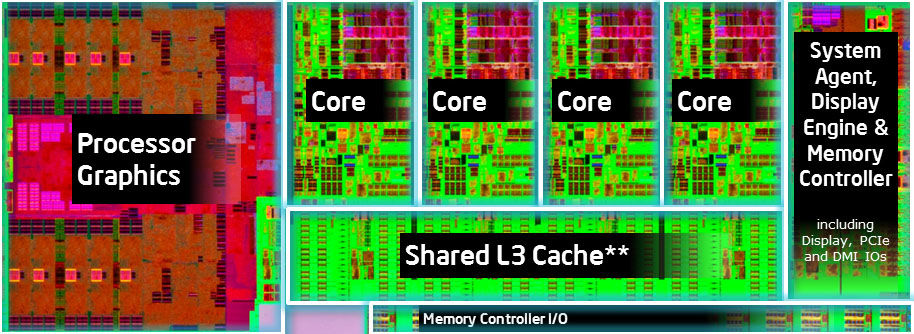
Image from Tom's Hardware
You can see that there are 4 things called cores - these actually contain the control unit and ALU (although there seem to be four of them, not one!). You can also see a block on the right which contains the "memory controller" (giving access to the Data memory and Instruction memory), along with I/O and various other bits and pieces. But it obviously isn't quite as simple as our diagram. There's a "graphics" unit on the left of the picture, and a massive part of the chip seems to be something called 'Shared L3 Cache'.

But it's true - our model is still very inaccurate. Remember our stack diagram from the previous section?
We're looking at a box right near the bottom of the stack, so we call this a low level view. We always tend to draw the stuff closest to the hardware near the bottom, and higher-level abstractions further up.
And, low level though this is, it is obvious that real computers are more complex than the story we've just told. Control Units (of which, as we've seen, there could be many) might speculatively execute many instructions ahead based on what the result of previous operations could possibly be; or they might read from that local L3 cache where they keep a copy of a commonly-used section of the data memory, for example.
Very commonly, in addition to the program instruction memory, and the data memory, they have a small number of specialist memory locations called registers which can temporarily store values in the control unit itself. These are often used to keep track of where we are in the program; store the intermediate results of more complex calculations; or keep references to where we've stored some information in the data memory.
More fundamentally, control units will usually be able to write to the program instruction list, as well as read from it, which enables them to load programs from external I/O devices (like hard disks).
Because of all these variations (in particular the ability to write to program instruction memory), almost all real computers are based on what we call a Modified Harvard Architecture.
So, if this description of a computer isn't strictly accurate, why do we care about the nuances of difference between 'von Neumann Architecture', 'Harvard Architecture' and 'Modified Harvard Architecture'?
First, there's the practical reason - it is useful to share an understanding of 'how things work' with other developers, and you need to know the language to join in the conversation. The computer industry is full of this jargon (we've already seen 'stack', 'architecture', 'registers', 'imperative', 'declarative', 'ALU', amongst others).
The fact that our models aren't strictly accurate doesn't matter - as long as they are good enough to help us understand a particular problem. As we've seen with the von Neumann bottleneck, these models can clearly show us a constraint that we need to consider when we try to design our programs.
This leads us on to the more philosophical reason for learning about architecture right at the beginning. We want to get used to thinking in terms of abstractions, models and simplifications - and not lose sight of the fact that they are all just models and simplifications. Looking at the nuances of difference between these different models helps us to reinforce that, and begins to train us to look for patterns and variations.
Given that we're programmers, let's start our exploration of this architecture by looking at the Program Instructions memory.



