RavenDB in the Cloud

We've been building some content-managed websites recently (this one, for instance). We needed a storage solution, and, as with many other document-centric applications, a document-orientated database is really what we want - something that lets us read, write and query document-structured data (1).
With Microsoft Windows Azure you have a bunch of different storage options available. Key/Value Pair data (what Microsoft choose to call 'NoSQL') is dealt with by Table Storage, binary objects go to Blob Storage, and your queuing needs are addressed by Queues (no, really?). Good old-fashioned relational data sits in SQL Azure.
What is missing right now (although I would expect this to be addressed in future) is a robust document database solution. Although a combination of Blob Storage and Table Storage can tempt you somewhere along the way, it rapidly becomes a apparent that they don't provide an ideal solution - you have to do too much heavy lifting at every stage, especially when it comes to querying.
So, we turned to third party options. In the past, we've used MongoDB, which is a great product, but feels a bit alien to the C# developer.

Step up, RavenDB.
RavenDB is a document database built top-to-bottom using managed code (including the .NET port of Lucene), and provides a very LINQ-friendly, ReST-friendly solution, with a neat .NET client library to boot. Very simple to use, robust and with decent performance.
How do you get it to run on Azure? There's lots of conflicting advice out there - mainly because previous versions of Raven didn't really support the environment - but if you are going to set up Raven in Azure yourself, you'll want Mark Rendle's sample.
If you take a look at the sample (represented in the diagram below), you'll see that it is running Raven in its own worker role (which means a bit of extra cost), and, while it supports replication (if you need it), you can't guarantee the referential integrity of the replicas - which is fine for a content management solution, but might not be what you want for a more transactional app.

A Warning To The Curious
When we initially experimented with Raven (and before we read Mark's sample) we set it up using Embedded mode, and ran it in the same worker role as our app. This was really easy to get up and running but proved to be horribly unreliable. As Azure recycles your instance (which sometimes means "yanks it away from underneath you") Raven Embedded had locks on the database open, and the new instance couldn't restart, and the site would go down. Not very desirable.
And if you go down the Embdedded route, you absolutely have to set up replication if you want to support more than one instance (which you do if you want any uptime guarantees).
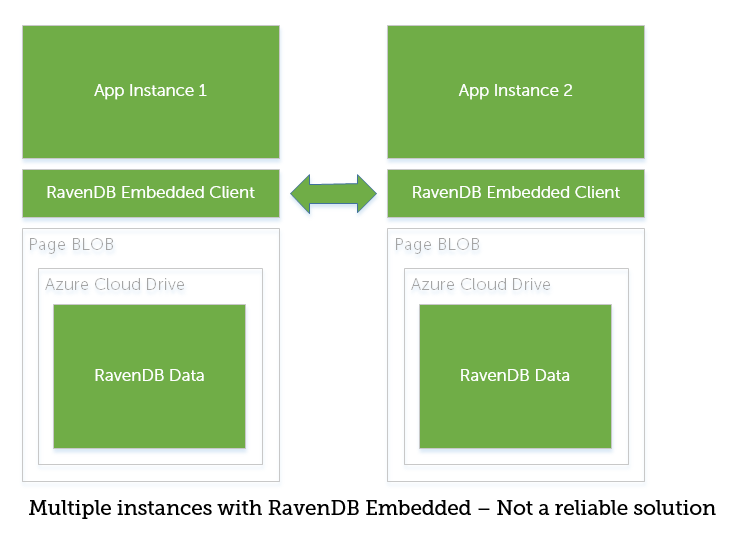
So - ruling out RavenDB Embedded, hosting Raven yourself, in its own worker role, is a great option for larger solutions with significant scaling requirements, but it is not the only option. We also looked at the cost/benefits of a hosted Raven instance, and determined that it was a better fit for some of our clients.
The main contenders in that space are RavenHQ, CloudBird and as an add-on in AppHarbor. We've got a couple of clients set up in each of RavenHQ and CloudBird, and we're comparing cost and reliability. (Both on a par, so far.)
The only real issue I have with this solution is that neither is actually hosted inside the Azure Fabric, so there is a penalty for data transfer - you need to have a good caching strategy in place. With that caveat, both have proved to be high-performance, robust solutions.
(1) I don't want to say "unstructured" - it isn't - it just isn't rigidly/immutably structured in the way we have come to expect from normalized, relational data. Of course, that expectation of relational systems is a largely false perception too, and one of the main reasons for the shocking forward/backward compatibility issues that most large systems suffer.