Accessing multi-select choice labels in Synapse Link for Dataverse


When you export a table from Dataverse into Synapse using the Azure Synapse Link for Dataverse, the multi-select choice columns in your linked tables will display a list of numerical choice values. This isn't very meaningful to the end-user, what we really want to display in our choice columns is the associated text choice labels. This blog post explains how to access the multi-select choice column choice labels from Azure Synapse Link for Dataverse using PySpark, Spark SQL or T-SQL through SQL Serverless.
Multi-select choice columns in Dataverse
A multi-select choice column, is a type of column that can be used in a Microsoft Dataverse table. In a multi-select choice column, the user can select one or more values from a set of options using a drop-down list control.
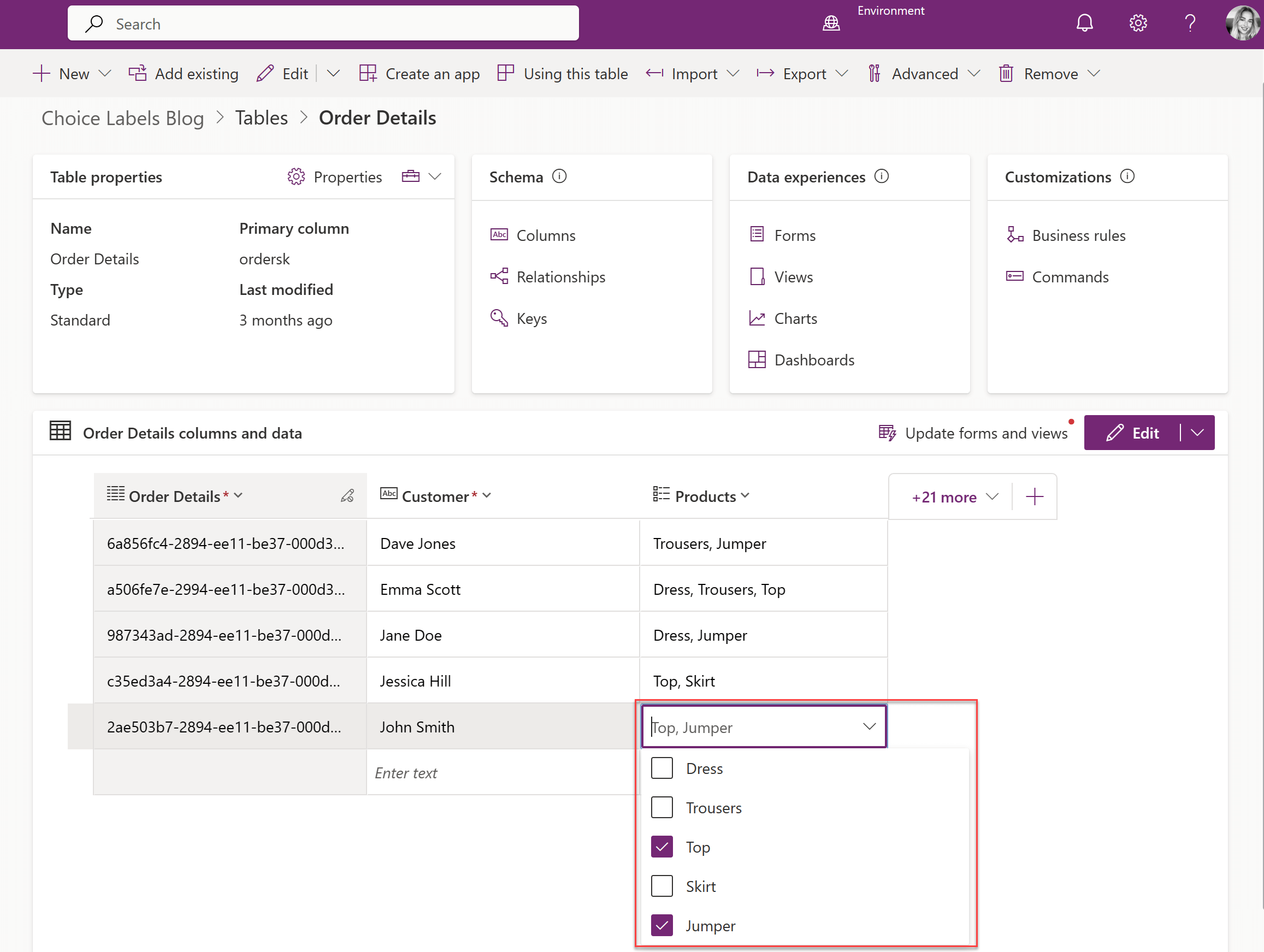
A multi-select choice column can be created in Dataverse by ticking the 'Selecting multiple choices is allowed' check-box when creating the choice column.

When you export a table from Dataverse into Synapse using the Azure Synapse Link for Dataverse, the multi-select choice columns in your linked tables will display a semi-colon separated list of numerical choice values.

This isn't very meaningful to the end-user, what we really want to display in our choice columns is the associated text choice labels, which are stored in the OptionsetMetadata table.

For detailed, contextual background on choice values and choice labels in Dataverse, and the storage of of choice labels in the OptionsetMetadata table of the Azure Synapse Link for Dataverse database, please refer back to first blog post in this series: How to access choice labels from Azure Synapse Link for Dataverse using PySpark.
Replacing the choice values with the choice labels using PySpark in a Synapse Notebook
First you will need to read your data from the Azure Synapse Link for Dataverse database into PySpark dataframes in a Synapse Notebook. For an explanation on how to do this, please refer back to first blog post in this series: How to access choice labels from Azure Synapse Link for Dataverse using PySpark.
Then you can replace the numerical choice values in your linked Dataverse table with the text choice labels using the following PySpark function:
from pyspark.sql.functions import split, explode
def swap_choice_value_with_choice_label(core_table_df, choice_options_df, column_name, table_name, option_set_name):
# Explode core_table_df on the column_name
exploded_df = core_table_df.withColumn(column_name, explode(split(core_table_df[column_name], ';')))
# Join exploded_df with the choice_options_df using table_name and option_set_name as additional join conditions
joined_df = exploded_df.join(
choice_options_df,
(exploded_df[column_name] == choice_options_df['Option']) &
(choice_options_df['EntityName'] == table_name) &
(choice_options_df['OptionSetName'] == option_set_name),
"left"
).drop(column_name, 'Option', 'EntityName', 'OptionSetName').withColumnRenamed('LocalizedLabel', column_name)
return joined_df

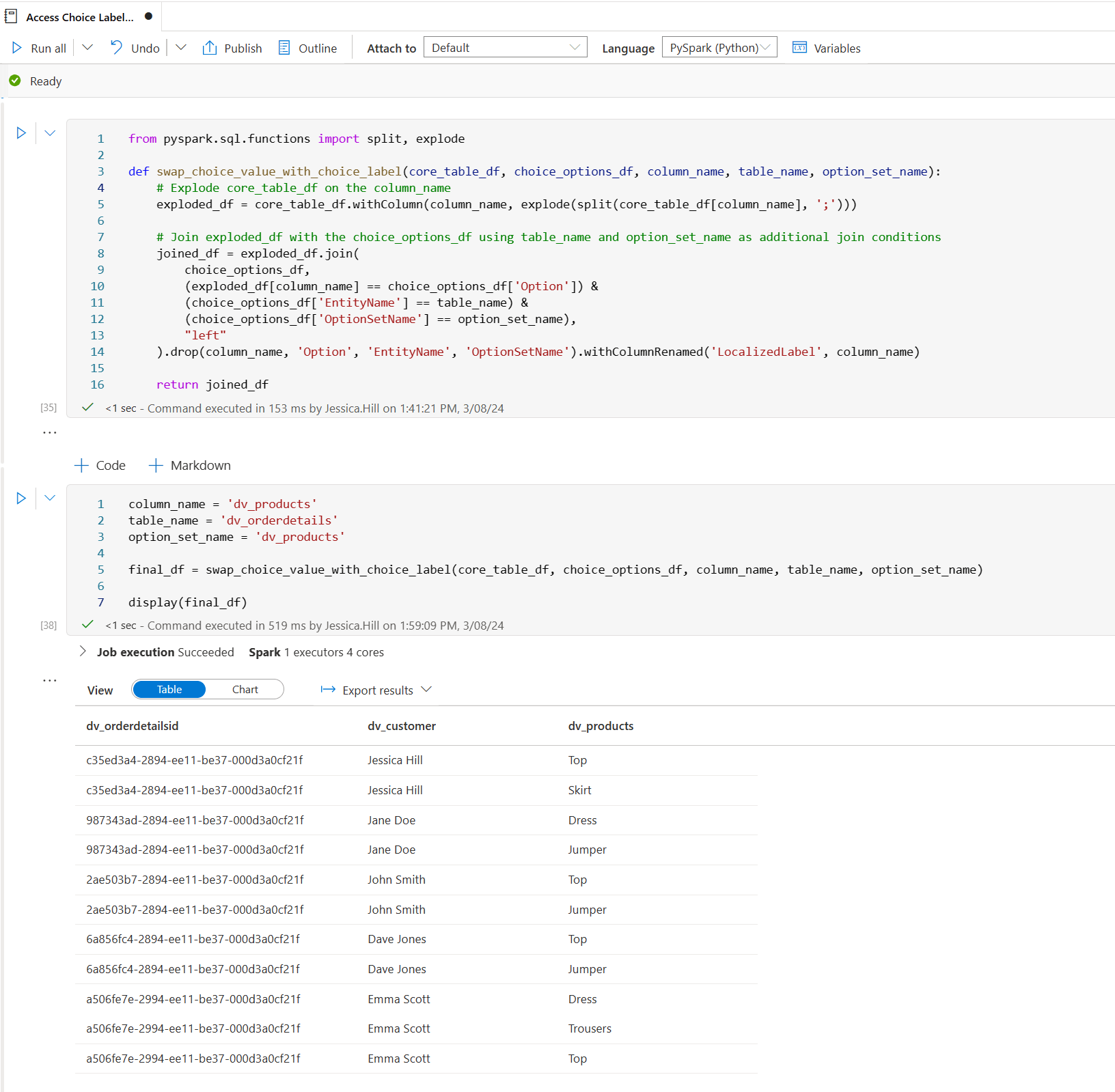
Here is an example implementation of the above PySpark function. This is how we transform a linked Dataverse table called dv_orderdetails, exploding and replacing the numerical choice values in the dv_products column with the text choice labels stored in the LocalizedLabel column of the OptionsetMetadata table:
core_table_df # This is your PySpark dataframe for your linked Dataverse table
choice_options_df # This is your PySpark dataframe for the OptionsetMetadata table
column_name = 'dv_products' # This is the name of the choice column in Synapse
table_name = 'dv_orderdetails' # This is the schema name of the core table in Dataverse
option_set_name = 'dv_products' # This is the schema name of the choice column in Dataverse
final_df = swap_choice_value_with_choice_label(core_table_df, choice_options_df, column_name, table_name, option_set_name)
And here is the resulting PySpark dataframe:
Replacing the choice values with the choice labels using Spark SQL in a Synapse Notebook
You can also replace the numerical choice values in your linked Dataverse table with the text choice labels using the following Spark SQL query within a Synapse Notebook:
SELECT
<'insert column 1 name here'>,
<'insert column 2 name here'>,
/* List all of the columns you would like to return from your linked table */
LocalizedLabel AS <'assign alias here'>
FROM (
SELECT
<'insert column 1 name here'> AS <'assign alias here'>,
<'insert column 2 name here'> AS <'assign alias here'>,
explode(split(<'insert choice column name here'>, ';')) AS <'assign choice column id alias here'>
FROM <'insert database name here'>.<'insert table name here'>
) tn
LEFT JOIN <'insert database name here'>.OptionsetMetadata om
ON tn.<'choice column id alias'> = om.Option
Here is an example implementation of the above Spark SQL query. This is how we would query a linked Dataverse table called dv_orderdetails, exploding and replacing the numerical choice values in the dv_products column with the text choice labels stored in the LocalizedLabel column of the OptionsetMetadata table:
SELECT
order_details_id,
customer,
LocalizedLabel AS products
FROM (
SELECT
dv_orderdetailsid AS order_details_id,
dv_customer AS customer,
explode(split(dv_products, ';')) AS product_id
FROM dataverse_edfreemansen.dv_orderdetails
) od
LEFT JOIN dataverse_edfreemansen.OptionsetMetadata om
ON od.product_id = om.Option;
And here is result of the query:

Replacing the choice values with the choice labels using T-SQL through SQL Severless
You can also replace the numerical choice values in your linked Dataverse table with the text choice labels using the following T-SQL query within a SQL script in Synapse:
SELECT
[<'insert column 1 name here'>] AS [<'assign alias here'>],
[<'insert column 2 name here'>] AS [<'assign alias here'>],
/* List all of the columns you would like to return from your linked table */
[LocalizedLabel] AS [<'assign alias here'>]
FROM [<'insert database name here'>].[dbo].[<'insert table name here'>]
CROSS APPLY STRING_SPLIT([<'insert choice column name here'>], ';') AS tn
LEFT JOIN [<'insert database name here'>].[dbo].[OptionsetMetadata] om
ON tn.value = om.[Option]
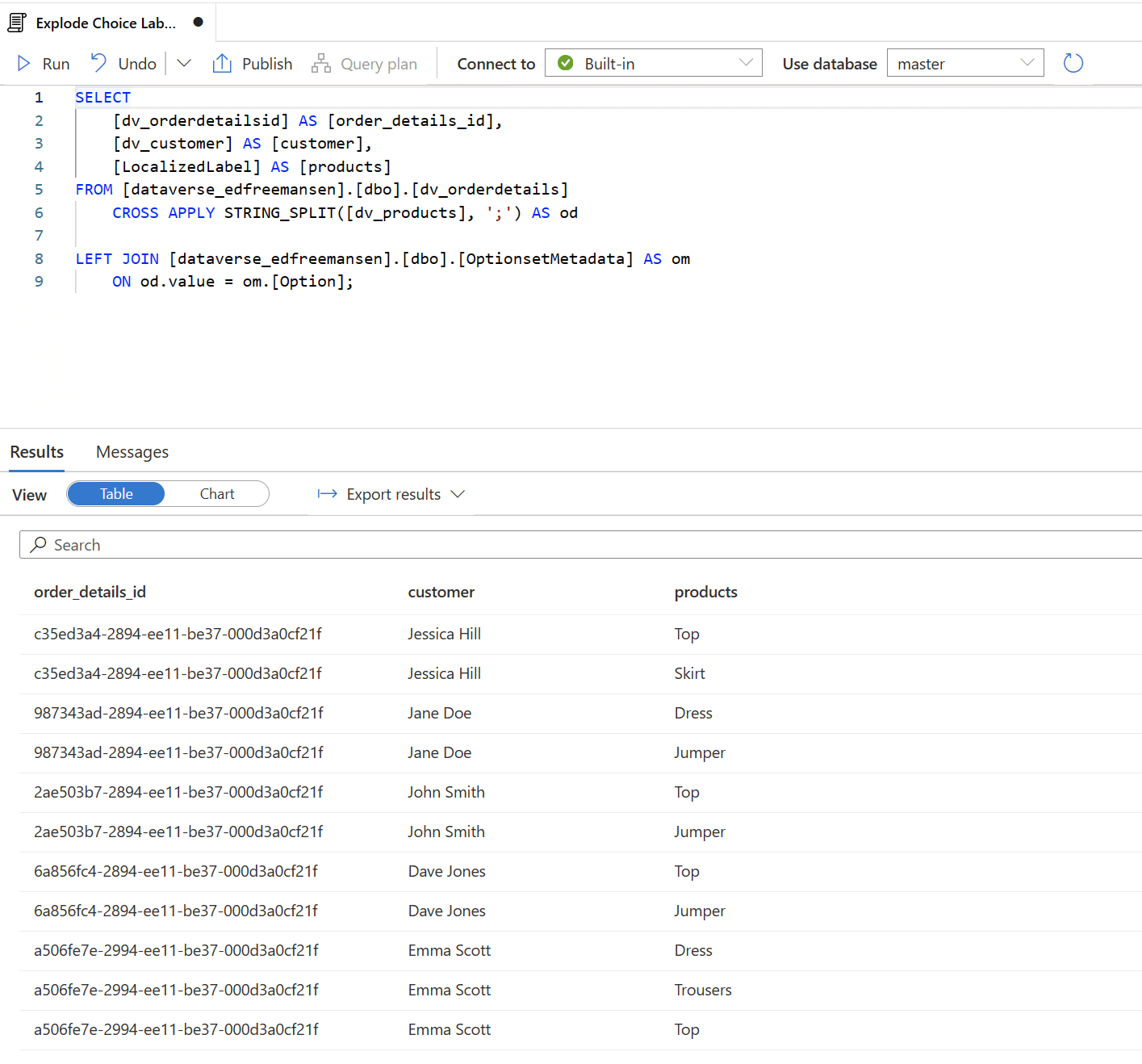
Here is an example implementation of the above T-SQL query. This is how we would query a linked Dataverse table called dv_orderdetails, exploding and replacing the numerical choice values in the dv_products column with the text choice labels stored in the LocalizedLabel column of the OptionsetMetadata table:
SELECT
[dv_orderdetailsid] AS [order_details_id],
[dv_customer] AS [customer],
[LocalizedLabel] AS [products]
FROM [dataverse_edfreemansen].[dbo].[dv_orderdetails]
CROSS APPLY STRING_SPLIT([dv_products], ';') AS od
LEFT JOIN [dataverse_edfreemansen].[dbo].[OptionsetMetadata] AS om
ON od.value = om.[Option];
And here is result of the query:
Conclusion
This blog post has explored how to access multi-select choice column choice labels from Azure Synapse Link for Dataverse using PySpark, Spark SQL or T-SQL through SQL Serverless.