What is Retrieval-Augmented Generation (RAG)?


There has been a massive explosion in the use of generative AI, and when and how we use it has become an incredibly important question. It is easy enough to throw anything into an LLM, and a lot of those attempts will be met with mixed success.
One thing that LLMs are provably good for is the summarisation / re-structuring of text. But, how do we focus the model down to the information we care about - and stop the tendency of adding additional, plausible, but possibly irrelevant (or incorrect!) information? And how do we limit the information it needs to parse so that we don’t reach token limits or performance degradation due to huge inputs? This is where RAG comes in.
What is RAG?
Retrieval-Augmented Generation (RAG) is a multi-step process by which we retrieve relevant information, and then add that information to the context, along with the given prompt. It allows us to ground responses in our data, rather than relying solely on pre-trained knowledge.
The RAG process is as follows:
- Retrieval: Retrieve relevant information. This can be from databases, documents, knowledge bases, etc. Often semantic / vector-based search is used to find information relevant to the input (more on this later).
- Augmentation: The retrieved information is then added into the context, augmenting the prompt with the relevant data.
- Generation: The language model generates a response, based on the augmented prompt.

This approach has a few advantages:
- Information is up to date as it can be retrieved from a live source, rather than relying on what the model was trained on.
- You can ground responses in your domain-specific knowledge, without needing a specialised model.
- You can add references to specific documents / pieces of information, allowing you to cross-check the response.
- By enforcing direct links to the data, you can reduce the chance of hallucinations (though with large caveats - the subject of a future post).
- You do not need to release sensitive information into model training processes.
- You can control access like you would to any databases, and only ever add information that a user is allowed to see into the context. This allows for a fine-grained security model that would be impossible if training the LLM on all of the data (in this case, there is no way to limit what data a user has access to, if they are given access to the LLM).
- Reducing the amount of information that the model needs to process (by limiting the context to the most relevant information) means that you can usually use smaller models and still achieve great results.
Let's take an example of a retail website where customers can leave reviews. You might want to build an application that allows users to ask questions about the reviews that customers have left.
In a RAG example, the review data could be queried (by standard query, or vector search), and the reviews that are relevant would be retrieved. These reviews would then be used to augment the user's question, and added to the context that is passed into an LLM. The LLM would then use that context to generate an answer to the user's question.
Retrieval
At the heart of RAG is the ability to retrieve content that is relevant.
Database Query
This could take the form of a standard database query based on criteria. In our review example, imagine that these reviews are stored in a database. The user could filter the reviews using certain criteria - "Clothing Product", "Fewer than 2 stars", "From the Last 24 Hours", etc.
These criteria could be used to query the database, and all relevant information returned. This information would then be added as context to any questions that the user wanted to ask.
Keyword Search
Another option is to filter the responses based on keywords. In our example, the user could input keywords ("late", "expensive", "broken", etc.). In this way, you can filter the results down to those which directly talk about relevant topics.
There are services, such as Azure AI Search, which allow you to do fast keyword matching on documents. Azure AI Search also allows you to do "fuzzy" matching - which handles differences in capitalisation, spelling mistakes, etc.
Again, the relevant documents would be added to the context used to augment the user's questions.
Vector Search
In vector search, embeddings are used to find documents which are conceptually related to the search terms or questions asked.
An embedding is a numerical representation of text - essentially converting words and sentences into arrays of numbers (vectors) that capture their semantic meaning. These vectors contain many dimensions, allowing for complex concepts to be represented. Embedding models are typically neural networks trained on massive amounts of text to learn these relationships.
The secret to vector search is that, using these embeddings, semantically similar text ends up with vectors that are close together in this high-dimensional space. For example, imagine we had the words "snail" and "slug" and vectorised them, you might end up with two vectors that point in a similar direction.
Though similar, these two words don't mean quite the same thing, and this is captured in vector space:
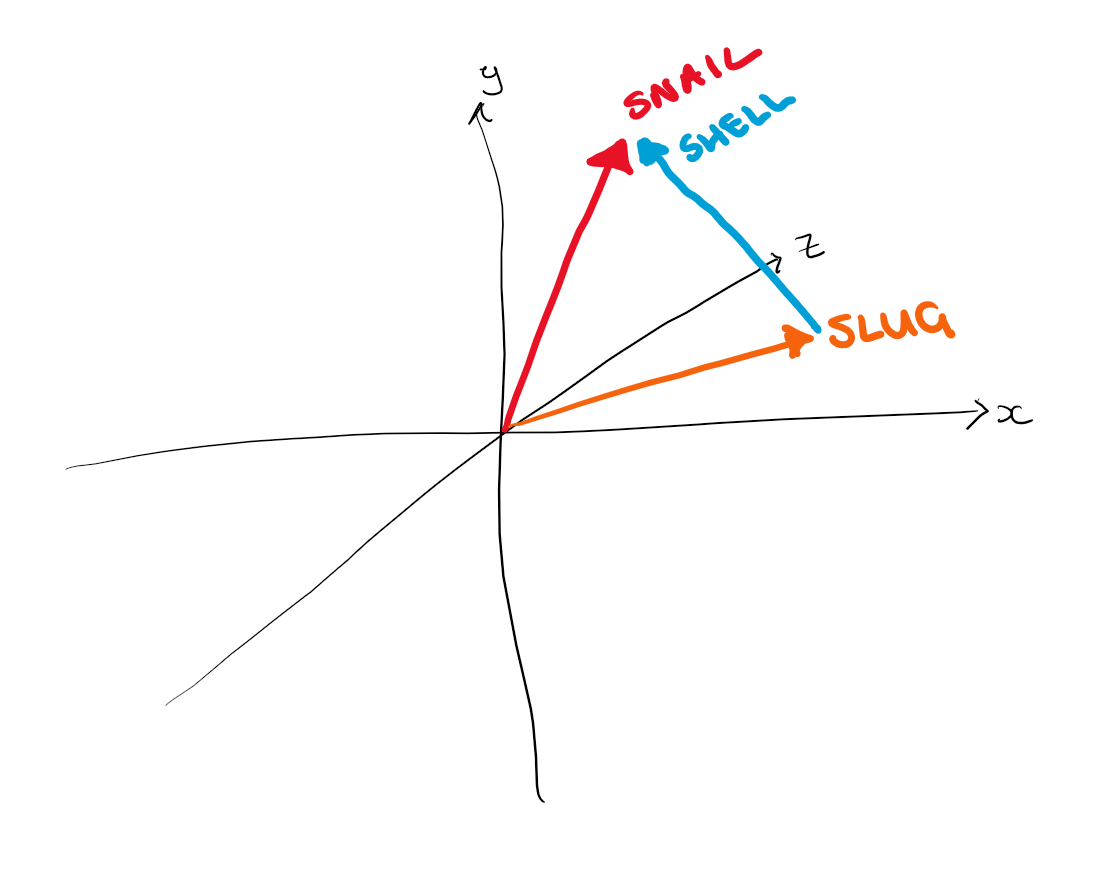
Here we can see that the vectors for snail and slug are pointing in relatively similar directions, and the difference between the two is about equal to the vector for "shell".
This is a super simplified example, and you would obviously need a lot more dimensions to represent all of the complex information that makes up a "slug" or "snail". But using this, we can start to visualise how different information and the connections between it can be represented in vector space.
An important thing to understand here is that AI embeddings turn words into vectors in context. For example, the word "bow" in the sentence "she had a bow in her hair", would have a very different vector to "the actors took a bow". Embedding models don't really embed the meaning of just a word, but instead the meaning of a sentence or context around a word is represented in vector space.
In practice, in RAG scenarios, generally it is not a single word that is vectorised, but a whole sentence or block of text. The overall meaning of the text is then used to retrieve relevant results.

Going back to our retail example, when you embed the text "Shipping took forever" and "Delivery was extremely slow", they'll have similar vector representations despite different words, because they mean similar things. Meanwhile, "Material feels cheap and flimsy" will be far away in vector space.
The user might ask a question such as "What are customers saying about delivery?". Using vector search, the user's question (or prompt) can be vectorised, and used to find reviews that are relevant to what they're asking about.
Augmentation
Once relevant documents (and in the case of our example, reviews) have been retrieved, they are added to the context for the LLM. This usually involves literally adding the relevant documents into the prompt that is sent to the LLM.
For example, if a user asks "What are customers saying about delivery?", relevant reviews could be retrieved (using one of the methods above).
Then, the prompt sent into the LLM would include the user's question, and all of the relevant documents. E.g.:
Answer the following question: 'What are customers saying about delivery?', based on the customer reviews in the context provided. Do not use any information outside of what is contained in the given context.
Context:
Review 1
- Rating: 5
- Review Content: Amazing service! My order arrived in just 2 days, even though I only selected standard shipping. Very impressed.
Review 2
- Rating: 1
- Review Content: Shipping took over 3 weeks. No updates on tracking. Had to contact support multiple times. Completely unacceptable.
Review 3
- Rating: 4
- Review Content: Package arrived on time and in perfect condition. Tracking updates were accurate throughout the entire process.
Review 4
- Rating: 3
- Review Content: Delivery was supposed to be 5-7 days but took 10. Not terrible but not what was promised either.
Review 5
- Rating: 1
- Review Content: My package was marked as delivered but I never received it. Driver must have left it at the wrong address. Still waiting for resolution.
Review 6
- Rating: 5
- Review Content: Super fast shipping! Ordered on Monday and it was at my door by Wednesday morning. Packaging was secure too.
Review 7
- Rating: 2
- Review Content: Delivery took forever and the box was crushed when it finally arrived. Thankfully the product inside wasn't damaged.
It is worth noting that the retrieval of relevant information, rather than just augmenting the prompt with all review data, is an important step. This is because as prompt input sizes increase, the responses from the LLM degrade. Limiting the context to a smaller subset of relevant information is the best way to get useful responses.
Generation
The prompt will then be passed into an LLM. The LLM does not need to have been trained on any of the review data, as all of the relevant data is provided as part of the prompt.
The LLM will analyze the retrieved reviews and generate a natural language response. For our example question "What are customers saying about delivery?", the LLM might respond:
"Customer feedback on delivery is mixed. Positive reviews highlight fast shipping times, with some customers receiving orders in 2-3 days even with standard shipping. The tracking system is generally praised for being accurate. However, there are concerns about inconsistent delivery times - some orders took significantly longer than promised (10+ days instead of 5-7). There are also reports of damaged packages and delivery issues like packages being marked as delivered but not received."
This response is grounded entirely in the context provided - the LLM hasn't hallucinated information or drawn on training data that might be outdated or irrelevant to this specific business.
An important thing to note is that though using RAG will increase the likelihood of responses being grounded and relevant (and adding sentences to the prompt such as "Do not use any information outside of what is contained in the given context." will further increase this likelihood), there is still an inherent propensity for LLMs to fall back on training data, or include unexpected information in responses. As such, even in RAG situations, all responses must be validated against expected outputs.
Summary
RAG provides a powerful way to make LLMs more useful for real-world applications. By retrieving relevant information, augmenting prompts with that context, and then generating responses, we can:
- Keep information current and accurate
- Ground responses in domain-specific data
- Reduce hallucinations (with caveats)
- Maintain security and access controls
- Use smaller, more efficient models
Thanks for reading this introduction to RAG search. Watch out for my next blog, which will dive deeper into implementation!



